{"title":"使用基础模型的可靠燃烧科学知识处理框架","authors":"Vansh Sharma, Venkat Raman","doi":"10.1016/j.egyai.2024.100365","DOIUrl":null,"url":null,"abstract":"<div><p>This research explores the integration of large language models (LLMs) into scientific data assimilation, focusing on combustion science as a case study. Leveraging foundational models integrated with Retrieval-Augmented Generation (RAG) framework, the study introduces an approach to process diverse combustion research data, spanning experimental studies, simulations, and literature. The multifaceted nature of combustion research emphasizes the critical role of knowledge processing in navigating and extracting valuable information from a vast and diverse pool of sources. The developed approach minimizes computational and economic expenses while optimizing data privacy and accuracy. It incorporates prompt engineering and offline open-source LLMs, offering user autonomy in selecting base models. The study provides a thorough examination of text segmentation strategies, conducts comparative studies between LLMs, and explores various optimized prompts to demonstrate the effectiveness of the framework. By incorporating an external vector database, the framework outperforms a conventional LLM in generating accurate responses and constructing robust arguments. Additionally, the study delves into the investigation of optimized prompt templates for the purpose of efficient extraction of scientific literature. Furthermore, we present a targeted scaling study to quantify the algorithmic performance of the framework as the number of prompt tokens increases. The research addresses concerns related to hallucinations and false research articles by introducing a custom workflow developed with a detection algorithm to filter out inaccuracies. Despite identified areas for improvement, the framework consistently delivers accurate domain-specific responses with minimal human oversight. The prompt-agnostic approach introduced holds promise for future improvements. The study underscores the significance of integrating LLMs and knowledge processing techniques in scientific research, providing a foundation for advancements in data assimilation and utilization.</p></div>","PeriodicalId":34138,"journal":{"name":"Energy and AI","volume":"16 ","pages":"Article 100365"},"PeriodicalIF":9.6000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2666546824000314/pdfft?md5=253c1bc638957975ef44ed9f22b35270&pid=1-s2.0-S2666546824000314-main.pdf","citationCount":"0","resultStr":"{\"title\":\"A reliable knowledge processing framework for combustion science using foundation models\",\"authors\":\"Vansh Sharma, Venkat Raman\",\"doi\":\"10.1016/j.egyai.2024.100365\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>This research explores the integration of large language models (LLMs) into scientific data assimilation, focusing on combustion science as a case study. Leveraging foundational models integrated with Retrieval-Augmented Generation (RAG) framework, the study introduces an approach to process diverse combustion research data, spanning experimental studies, simulations, and literature. The multifaceted nature of combustion research emphasizes the critical role of knowledge processing in navigating and extracting valuable information from a vast and diverse pool of sources. The developed approach minimizes computational and economic expenses while optimizing data privacy and accuracy. It incorporates prompt engineering and offline open-source LLMs, offering user autonomy in selecting base models. The study provides a thorough examination of text segmentation strategies, conducts comparative studies between LLMs, and explores various optimized prompts to demonstrate the effectiveness of the framework. By incorporating an external vector database, the framework outperforms a conventional LLM in generating accurate responses and constructing robust arguments. Additionally, the study delves into the investigation of optimized prompt templates for the purpose of efficient extraction of scientific literature. Furthermore, we present a targeted scaling study to quantify the algorithmic performance of the framework as the number of prompt tokens increases. The research addresses concerns related to hallucinations and false research articles by introducing a custom workflow developed with a detection algorithm to filter out inaccuracies. Despite identified areas for improvement, the framework consistently delivers accurate domain-specific responses with minimal human oversight. The prompt-agnostic approach introduced holds promise for future improvements. The study underscores the significance of integrating LLMs and knowledge processing techniques in scientific research, providing a foundation for advancements in data assimilation and utilization.</p></div>\",\"PeriodicalId\":34138,\"journal\":{\"name\":\"Energy and AI\",\"volume\":\"16 \",\"pages\":\"Article 100365\"},\"PeriodicalIF\":9.6000,\"publicationDate\":\"2024-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2666546824000314/pdfft?md5=253c1bc638957975ef44ed9f22b35270&pid=1-s2.0-S2666546824000314-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Energy and AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2666546824000314\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/4/18 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Energy and AI","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666546824000314","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/4/18 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A reliable knowledge processing framework for combustion science using foundation models
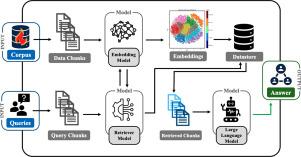
This research explores the integration of large language models (LLMs) into scientific data assimilation, focusing on combustion science as a case study. Leveraging foundational models integrated with Retrieval-Augmented Generation (RAG) framework, the study introduces an approach to process diverse combustion research data, spanning experimental studies, simulations, and literature. The multifaceted nature of combustion research emphasizes the critical role of knowledge processing in navigating and extracting valuable information from a vast and diverse pool of sources. The developed approach minimizes computational and economic expenses while optimizing data privacy and accuracy. It incorporates prompt engineering and offline open-source LLMs, offering user autonomy in selecting base models. The study provides a thorough examination of text segmentation strategies, conducts comparative studies between LLMs, and explores various optimized prompts to demonstrate the effectiveness of the framework. By incorporating an external vector database, the framework outperforms a conventional LLM in generating accurate responses and constructing robust arguments. Additionally, the study delves into the investigation of optimized prompt templates for the purpose of efficient extraction of scientific literature. Furthermore, we present a targeted scaling study to quantify the algorithmic performance of the framework as the number of prompt tokens increases. The research addresses concerns related to hallucinations and false research articles by introducing a custom workflow developed with a detection algorithm to filter out inaccuracies. Despite identified areas for improvement, the framework consistently delivers accurate domain-specific responses with minimal human oversight. The prompt-agnostic approach introduced holds promise for future improvements. The study underscores the significance of integrating LLMs and knowledge processing techniques in scientific research, providing a foundation for advancements in data assimilation and utilization.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
