{"title":"优化化学过程中的数据驱动故障检测和诊断","authors":"Nahid Raeisi Ardali, Reza Zarghami, Rahmat Sotudeh Gharebagh","doi":"10.1016/j.compchemeng.2024.108712","DOIUrl":null,"url":null,"abstract":"<div><p>Fault detection and diagnosis (FDD) is crucial for ensuring process safety and product quality in the chemical industry. Despite the large amounts of process data recorded and stored in chemical plants, most of them are not well-labeled, and their conditions are not adequately specified. In this study, an optimized data-driven FDD model was developed for a chemical process based on automatic clustering algorithms. Due to data preprocessing importance, feature selection was performed by a non-dominated sorting genetic algorithm (NSGAII) based on k-means clustering. The optimal subset of features is selected by comparing clustering results for each subset. The performance of the proposed feature selection method was compared with the Fisher discriminant ratio (FDR), and XGBoost methods. The t-distributed stochastic neighbor embedding (t-SNE), Isomap, and KPCA dimension reduction methods were also employed for feature extraction. Finally, automatic clustering was performed based on metaheuristic algorithms for fault detection and diagnosis. Results were compared with non-automatic clustering methods. The performance of the proposed method was evaluated by examining the Tennessee Eastman and four water tank processes as case studies. The results showed that the proposed method is reliable and capable of online and offline chemical process fault detection and diagnosis. As a result, the findings of this study can be used to stabilize the operation of chemical processes.</p></div>","PeriodicalId":286,"journal":{"name":"Computers & Chemical Engineering","volume":null,"pages":null},"PeriodicalIF":3.9000,"publicationDate":"2024-04-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Optimized data driven fault detection and diagnosis in chemical processes\",\"authors\":\"Nahid Raeisi Ardali, Reza Zarghami, Rahmat Sotudeh Gharebagh\",\"doi\":\"10.1016/j.compchemeng.2024.108712\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Fault detection and diagnosis (FDD) is crucial for ensuring process safety and product quality in the chemical industry. Despite the large amounts of process data recorded and stored in chemical plants, most of them are not well-labeled, and their conditions are not adequately specified. In this study, an optimized data-driven FDD model was developed for a chemical process based on automatic clustering algorithms. Due to data preprocessing importance, feature selection was performed by a non-dominated sorting genetic algorithm (NSGAII) based on k-means clustering. The optimal subset of features is selected by comparing clustering results for each subset. The performance of the proposed feature selection method was compared with the Fisher discriminant ratio (FDR), and XGBoost methods. The t-distributed stochastic neighbor embedding (t-SNE), Isomap, and KPCA dimension reduction methods were also employed for feature extraction. Finally, automatic clustering was performed based on metaheuristic algorithms for fault detection and diagnosis. Results were compared with non-automatic clustering methods. The performance of the proposed method was evaluated by examining the Tennessee Eastman and four water tank processes as case studies. The results showed that the proposed method is reliable and capable of online and offline chemical process fault detection and diagnosis. As a result, the findings of this study can be used to stabilize the operation of chemical processes.</p></div>\",\"PeriodicalId\":286,\"journal\":{\"name\":\"Computers & Chemical Engineering\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2024-04-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers & Chemical Engineering\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0098135424001303\",\"RegionNum\":2,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Chemical Engineering","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0098135424001303","RegionNum":2,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Optimized data driven fault detection and diagnosis in chemical processes
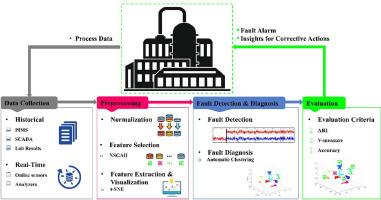
Fault detection and diagnosis (FDD) is crucial for ensuring process safety and product quality in the chemical industry. Despite the large amounts of process data recorded and stored in chemical plants, most of them are not well-labeled, and their conditions are not adequately specified. In this study, an optimized data-driven FDD model was developed for a chemical process based on automatic clustering algorithms. Due to data preprocessing importance, feature selection was performed by a non-dominated sorting genetic algorithm (NSGAII) based on k-means clustering. The optimal subset of features is selected by comparing clustering results for each subset. The performance of the proposed feature selection method was compared with the Fisher discriminant ratio (FDR), and XGBoost methods. The t-distributed stochastic neighbor embedding (t-SNE), Isomap, and KPCA dimension reduction methods were also employed for feature extraction. Finally, automatic clustering was performed based on metaheuristic algorithms for fault detection and diagnosis. Results were compared with non-automatic clustering methods. The performance of the proposed method was evaluated by examining the Tennessee Eastman and four water tank processes as case studies. The results showed that the proposed method is reliable and capable of online and offline chemical process fault detection and diagnosis. As a result, the findings of this study can be used to stabilize the operation of chemical processes.
期刊介绍:
Computers & Chemical Engineering is primarily a journal of record for new developments in the application of computing and systems technology to chemical engineering problems.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
