{"title":"大型语言模型与小众智慧。","authors":"Sean Trott","doi":"10.1162/opmi_a_00144","DOIUrl":null,"url":null,"abstract":"<p><p>Recent advances in Large Language Models (LLMs) have raised the question of replacing human subjects with LLM-generated data. While some believe that LLMs capture the \"wisdom of the crowd\"-due to their vast training data-empirical evidence for this hypothesis remains scarce. We present a novel methodological framework to test this: the \"number needed to beat\" (NNB), which measures how many humans are needed for a sample's quality to rival the quality achieved by GPT-4, a state-of-the-art LLM. In a series of pre-registered experiments, we collect novel human data and demonstrate the utility of this method for four psycholinguistic datasets for English. We find that NNB > 1 for each dataset, but also that NNB varies across tasks (and in some cases is quite small, e.g., 2). We also introduce two \"centaur\" methods for combining LLM and human data, which outperform both stand-alone LLMs and human samples. Finally, we analyze the trade-offs in data cost and quality for each approach. While clear limitations remain, we suggest that this framework could guide decision-making about whether and how to integrate LLM-generated data into the research pipeline.</p>","PeriodicalId":32558,"journal":{"name":"Open Mind","volume":"8 ","pages":"723-738"},"PeriodicalIF":0.0000,"publicationDate":"2024-05-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11142632/pdf/","citationCount":"0","resultStr":"{\"title\":\"Large Language Models and the Wisdom of Small Crowds.\",\"authors\":\"Sean Trott\",\"doi\":\"10.1162/opmi_a_00144\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Recent advances in Large Language Models (LLMs) have raised the question of replacing human subjects with LLM-generated data. While some believe that LLMs capture the \\\"wisdom of the crowd\\\"-due to their vast training data-empirical evidence for this hypothesis remains scarce. We present a novel methodological framework to test this: the \\\"number needed to beat\\\" (NNB), which measures how many humans are needed for a sample's quality to rival the quality achieved by GPT-4, a state-of-the-art LLM. In a series of pre-registered experiments, we collect novel human data and demonstrate the utility of this method for four psycholinguistic datasets for English. We find that NNB > 1 for each dataset, but also that NNB varies across tasks (and in some cases is quite small, e.g., 2). We also introduce two \\\"centaur\\\" methods for combining LLM and human data, which outperform both stand-alone LLMs and human samples. Finally, we analyze the trade-offs in data cost and quality for each approach. While clear limitations remain, we suggest that this framework could guide decision-making about whether and how to integrate LLM-generated data into the research pipeline.</p>\",\"PeriodicalId\":32558,\"journal\":{\"name\":\"Open Mind\",\"volume\":\"8 \",\"pages\":\"723-738\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-05-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11142632/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Open Mind\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1162/opmi_a_00144\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"Social Sciences\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Open Mind","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/opmi_a_00144","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"Social Sciences","Score":null,"Total":0}
Large Language Models and the Wisdom of Small Crowds.
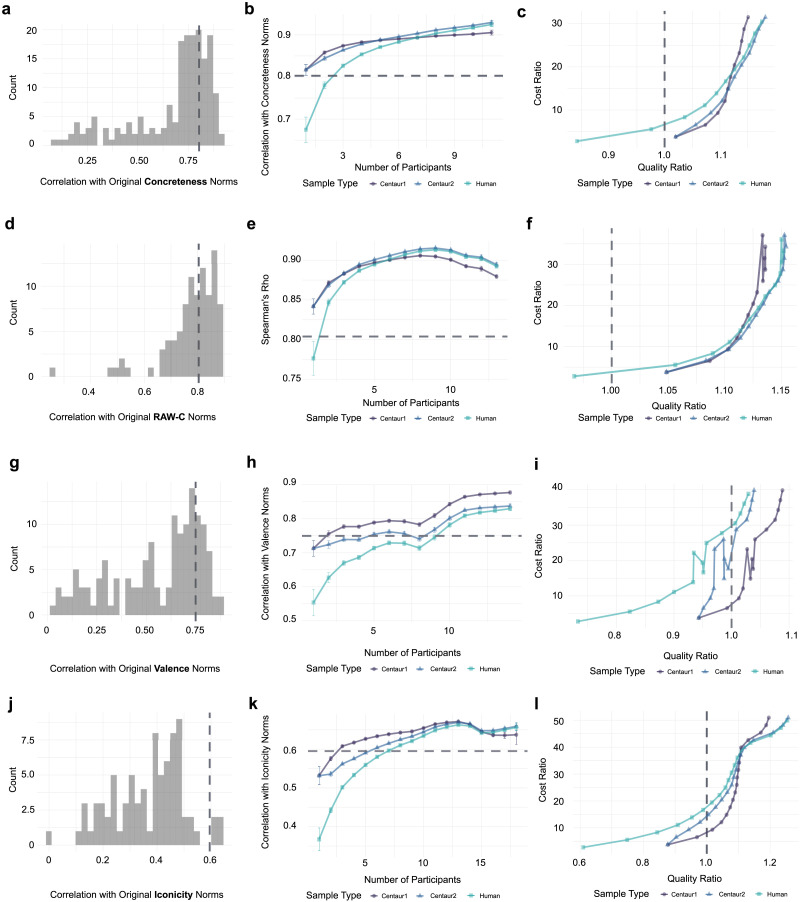
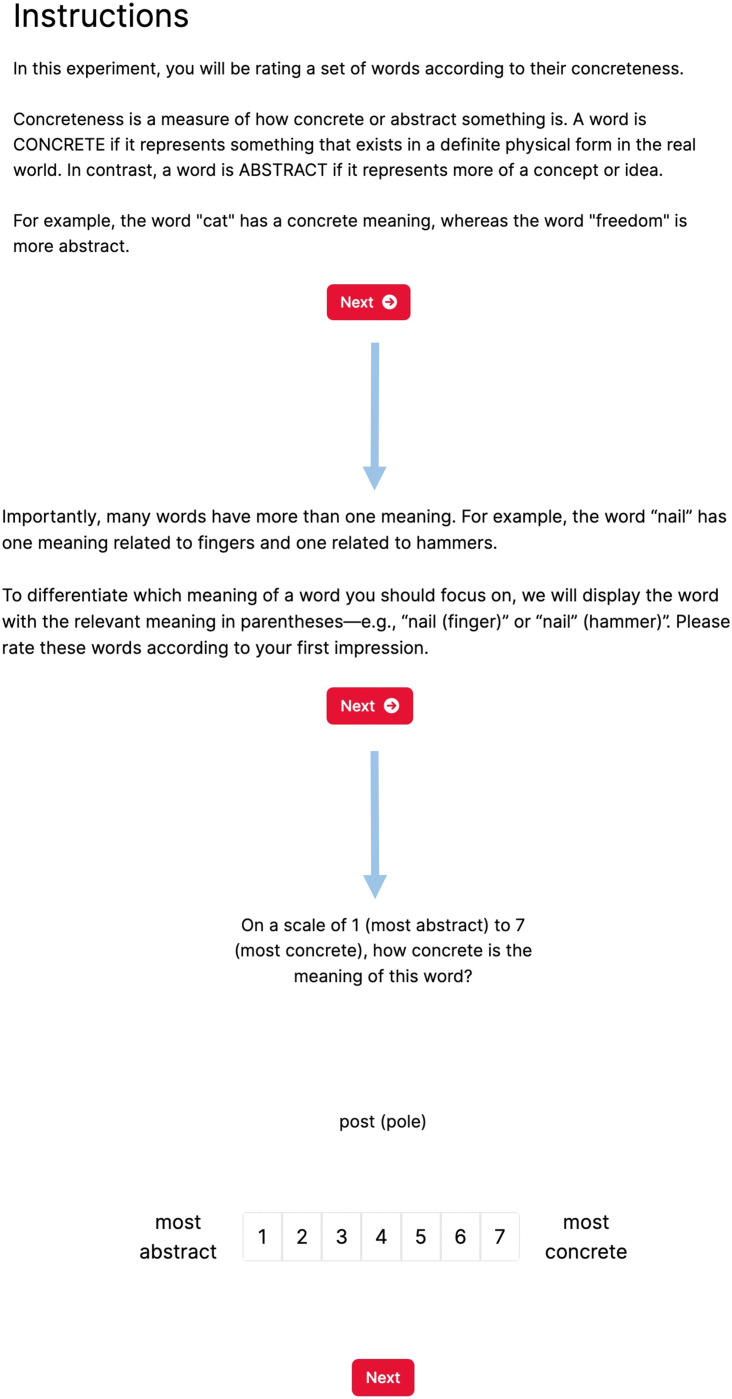
Recent advances in Large Language Models (LLMs) have raised the question of replacing human subjects with LLM-generated data. While some believe that LLMs capture the "wisdom of the crowd"-due to their vast training data-empirical evidence for this hypothesis remains scarce. We present a novel methodological framework to test this: the "number needed to beat" (NNB), which measures how many humans are needed for a sample's quality to rival the quality achieved by GPT-4, a state-of-the-art LLM. In a series of pre-registered experiments, we collect novel human data and demonstrate the utility of this method for four psycholinguistic datasets for English. We find that NNB > 1 for each dataset, but also that NNB varies across tasks (and in some cases is quite small, e.g., 2). We also introduce two "centaur" methods for combining LLM and human data, which outperform both stand-alone LLMs and human samples. Finally, we analyze the trade-offs in data cost and quality for each approach. While clear limitations remain, we suggest that this framework could guide decision-making about whether and how to integrate LLM-generated data into the research pipeline.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
