{"title":"基于机器学习的中风后临床结局预测模型与传统预后评分的比较:基于医院的多中心观察研究。","authors":"Fumi Irie, Koutarou Matsumoto, Ryu Matsuo, Yasunobu Nohara, Yoshinobu Wakisaka, Tetsuro Ago, Naoki Nakashima, Takanari Kitazono, Masahiro Kamouchi","doi":"10.2196/46840","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Although machine learning is a promising tool for making prognoses, the performance of machine learning in predicting outcomes after stroke remains to be examined.</p><p><strong>Objective: </strong>This study aims to examine how much data-driven models with machine learning improve predictive performance for poststroke outcomes compared with conventional stroke prognostic scores and to elucidate how explanatory variables in machine learning-based models differ from the items of the stroke prognostic scores.</p><p><strong>Methods: </strong>We used data from 10,513 patients who were registered in a multicenter prospective stroke registry in Japan between 2007 and 2017. The outcomes were poor functional outcome (modified Rankin Scale score >2) and death at 3 months after stroke. Machine learning-based models were developed using all variables with regularization methods, random forests, or boosted trees. We selected 3 stroke prognostic scores, namely, ASTRAL (Acute Stroke Registry and Analysis of Lausanne), PLAN (preadmission comorbidities, level of consciousness, age, neurologic deficit), and iScore (Ischemic Stroke Predictive Risk Score) for comparison. Item-based regression models were developed using the items of these 3 scores. The model performance was assessed in terms of discrimination and calibration. To compare the predictive performance of the data-driven model with that of the item-based model, we performed internal validation after random splits of identical populations into 80% of patients as a training set and 20% of patients as a test set; the models were developed in the training set and were validated in the test set. We evaluated the contribution of each variable to the models and compared the predictors used in the machine learning-based models with the items of the stroke prognostic scores.</p><p><strong>Results: </strong>The mean age of the study patients was 73.0 (SD 12.5) years, and 59.1% (6209/10,513) of them were men. The area under the receiver operating characteristic curves and the area under the precision-recall curves for predicting poststroke outcomes were higher for machine learning-based models than for item-based models in identical populations after random splits. Machine learning-based models also performed better than item-based models in terms of the Brier score. Machine learning-based models used different explanatory variables, such as laboratory data, from the items of the conventional stroke prognostic scores. Including these data in the machine learning-based models as explanatory variables improved performance in predicting outcomes after stroke, especially poststroke death.</p><p><strong>Conclusions: </strong>Machine learning-based models performed better in predicting poststroke outcomes than regression models using the items of conventional stroke prognostic scores, although they required additional variables, such as laboratory data, to attain improved performance. Further studies are warranted to validate the usefulness of machine learning in clinical settings.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"3 ","pages":"e46840"},"PeriodicalIF":2.0000,"publicationDate":"2024-01-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11041492/pdf/","citationCount":"0","resultStr":"{\"title\":\"Predictive Performance of Machine Learning-Based Models for Poststroke Clinical Outcomes in Comparison With Conventional Prognostic Scores: Multicenter, Hospital-Based Observational Study.\",\"authors\":\"Fumi Irie, Koutarou Matsumoto, Ryu Matsuo, Yasunobu Nohara, Yoshinobu Wakisaka, Tetsuro Ago, Naoki Nakashima, Takanari Kitazono, Masahiro Kamouchi\",\"doi\":\"10.2196/46840\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Although machine learning is a promising tool for making prognoses, the performance of machine learning in predicting outcomes after stroke remains to be examined.</p><p><strong>Objective: </strong>This study aims to examine how much data-driven models with machine learning improve predictive performance for poststroke outcomes compared with conventional stroke prognostic scores and to elucidate how explanatory variables in machine learning-based models differ from the items of the stroke prognostic scores.</p><p><strong>Methods: </strong>We used data from 10,513 patients who were registered in a multicenter prospective stroke registry in Japan between 2007 and 2017. The outcomes were poor functional outcome (modified Rankin Scale score >2) and death at 3 months after stroke. Machine learning-based models were developed using all variables with regularization methods, random forests, or boosted trees. We selected 3 stroke prognostic scores, namely, ASTRAL (Acute Stroke Registry and Analysis of Lausanne), PLAN (preadmission comorbidities, level of consciousness, age, neurologic deficit), and iScore (Ischemic Stroke Predictive Risk Score) for comparison. Item-based regression models were developed using the items of these 3 scores. The model performance was assessed in terms of discrimination and calibration. To compare the predictive performance of the data-driven model with that of the item-based model, we performed internal validation after random splits of identical populations into 80% of patients as a training set and 20% of patients as a test set; the models were developed in the training set and were validated in the test set. We evaluated the contribution of each variable to the models and compared the predictors used in the machine learning-based models with the items of the stroke prognostic scores.</p><p><strong>Results: </strong>The mean age of the study patients was 73.0 (SD 12.5) years, and 59.1% (6209/10,513) of them were men. The area under the receiver operating characteristic curves and the area under the precision-recall curves for predicting poststroke outcomes were higher for machine learning-based models than for item-based models in identical populations after random splits. Machine learning-based models also performed better than item-based models in terms of the Brier score. Machine learning-based models used different explanatory variables, such as laboratory data, from the items of the conventional stroke prognostic scores. Including these data in the machine learning-based models as explanatory variables improved performance in predicting outcomes after stroke, especially poststroke death.</p><p><strong>Conclusions: </strong>Machine learning-based models performed better in predicting poststroke outcomes than regression models using the items of conventional stroke prognostic scores, although they required additional variables, such as laboratory data, to attain improved performance. Further studies are warranted to validate the usefulness of machine learning in clinical settings.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"3 \",\"pages\":\"e46840\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-01-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11041492/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/46840\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/46840","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Predictive Performance of Machine Learning-Based Models for Poststroke Clinical Outcomes in Comparison With Conventional Prognostic Scores: Multicenter, Hospital-Based Observational Study.
Background: Although machine learning is a promising tool for making prognoses, the performance of machine learning in predicting outcomes after stroke remains to be examined.
Objective: This study aims to examine how much data-driven models with machine learning improve predictive performance for poststroke outcomes compared with conventional stroke prognostic scores and to elucidate how explanatory variables in machine learning-based models differ from the items of the stroke prognostic scores.
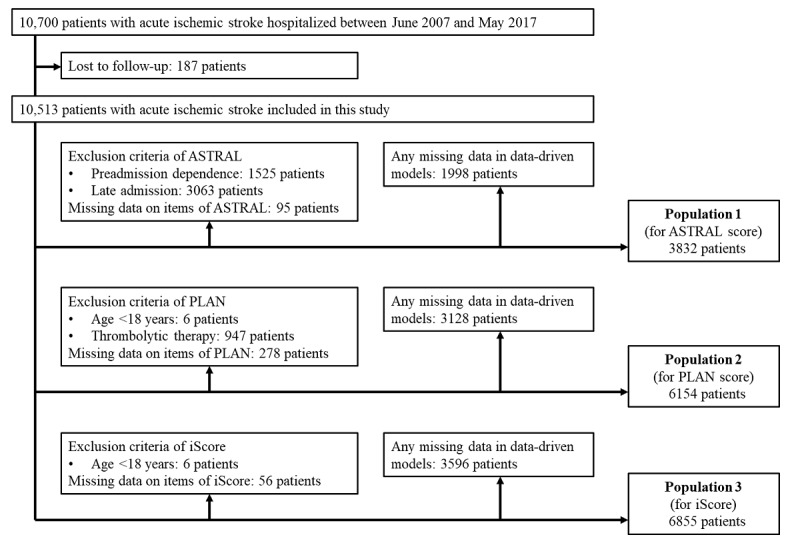
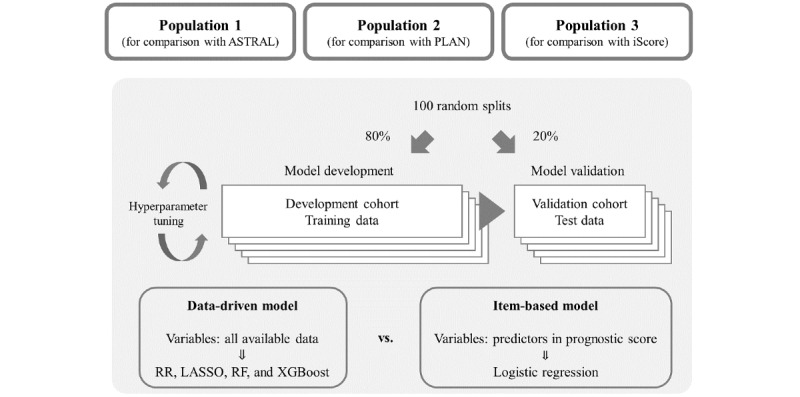
Methods: We used data from 10,513 patients who were registered in a multicenter prospective stroke registry in Japan between 2007 and 2017. The outcomes were poor functional outcome (modified Rankin Scale score >2) and death at 3 months after stroke. Machine learning-based models were developed using all variables with regularization methods, random forests, or boosted trees. We selected 3 stroke prognostic scores, namely, ASTRAL (Acute Stroke Registry and Analysis of Lausanne), PLAN (preadmission comorbidities, level of consciousness, age, neurologic deficit), and iScore (Ischemic Stroke Predictive Risk Score) for comparison. Item-based regression models were developed using the items of these 3 scores. The model performance was assessed in terms of discrimination and calibration. To compare the predictive performance of the data-driven model with that of the item-based model, we performed internal validation after random splits of identical populations into 80% of patients as a training set and 20% of patients as a test set; the models were developed in the training set and were validated in the test set. We evaluated the contribution of each variable to the models and compared the predictors used in the machine learning-based models with the items of the stroke prognostic scores.
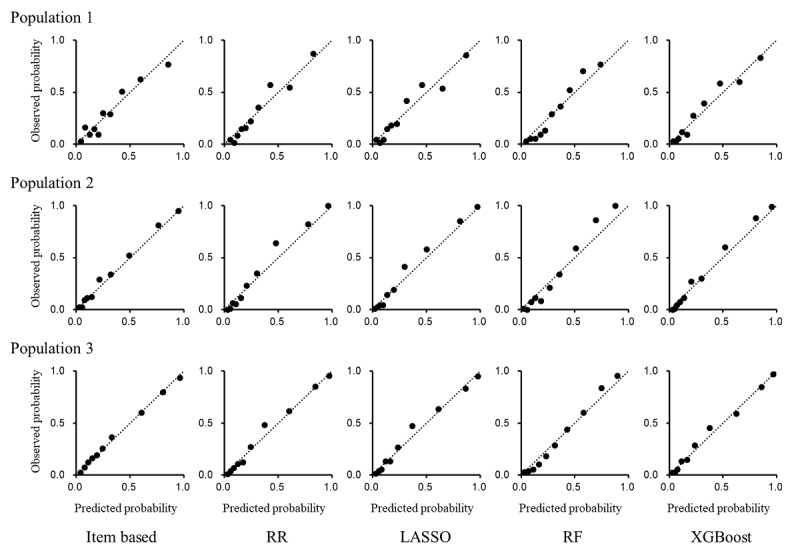
Results: The mean age of the study patients was 73.0 (SD 12.5) years, and 59.1% (6209/10,513) of them were men. The area under the receiver operating characteristic curves and the area under the precision-recall curves for predicting poststroke outcomes were higher for machine learning-based models than for item-based models in identical populations after random splits. Machine learning-based models also performed better than item-based models in terms of the Brier score. Machine learning-based models used different explanatory variables, such as laboratory data, from the items of the conventional stroke prognostic scores. Including these data in the machine learning-based models as explanatory variables improved performance in predicting outcomes after stroke, especially poststroke death.
Conclusions: Machine learning-based models performed better in predicting poststroke outcomes than regression models using the items of conventional stroke prognostic scores, although they required additional variables, such as laboratory data, to attain improved performance. Further studies are warranted to validate the usefulness of machine learning in clinical settings.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
