Libo Jiang, Michael A Quail, Jack Fraser-Govil, Haipeng Wang, Xuequn Shi, Karen Oliver, Esther Mellado Gomez, Fengtang Yang, Zemin Ning
{"title":"Hi-C 和关联读数的生物信息学应用","authors":"Libo Jiang, Michael A Quail, Jack Fraser-Govil, Haipeng Wang, Xuequn Shi, Karen Oliver, Esther Mellado Gomez, Fengtang Yang, Zemin Ning","doi":"10.1093/gpbjnl/qzae048","DOIUrl":null,"url":null,"abstract":"<p><p>Long-range sequencing grants insight into additional genetic information beyond what can be accessed by both short reads and modern long-read technology. Several new sequencing technologies, such as \"Hi-C\" and \"Linked Reads\", produce long-range datasets for high-throughput and high-resolution genome analyses, which are rapidly advancing the field of genome assembly, genome scaffolding, and more comprehensive variant identification. In this review, we focused on five major long-range sequencing technologies: high-throughput chromosome conformation capture (Hi-C), 10X Genomics Linked Reads, haplotagging, transposase enzyme linked long-read sequencing (TELL-seq), and single- tube long fragment read (stLFR). We detailed the mechanisms and data products of the five platforms and their important applications, evaluated the quality of sequencing data from different platforms, and discussed the currently available bioinformatics tools. This work will benefit the selection of appropriate long-range technology for specific biological studies.</p>","PeriodicalId":94020,"journal":{"name":"Genomics, proteomics & bioinformatics","volume":" ","pages":""},"PeriodicalIF":7.9000,"publicationDate":"2024-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11580686/pdf/","citationCount":"0","resultStr":"{\"title\":\"The Bioinformatic Applications of Hi-C and Linked Reads.\",\"authors\":\"Libo Jiang, Michael A Quail, Jack Fraser-Govil, Haipeng Wang, Xuequn Shi, Karen Oliver, Esther Mellado Gomez, Fengtang Yang, Zemin Ning\",\"doi\":\"10.1093/gpbjnl/qzae048\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Long-range sequencing grants insight into additional genetic information beyond what can be accessed by both short reads and modern long-read technology. Several new sequencing technologies, such as \\\"Hi-C\\\" and \\\"Linked Reads\\\", produce long-range datasets for high-throughput and high-resolution genome analyses, which are rapidly advancing the field of genome assembly, genome scaffolding, and more comprehensive variant identification. In this review, we focused on five major long-range sequencing technologies: high-throughput chromosome conformation capture (Hi-C), 10X Genomics Linked Reads, haplotagging, transposase enzyme linked long-read sequencing (TELL-seq), and single- tube long fragment read (stLFR). We detailed the mechanisms and data products of the five platforms and their important applications, evaluated the quality of sequencing data from different platforms, and discussed the currently available bioinformatics tools. This work will benefit the selection of appropriate long-range technology for specific biological studies.</p>\",\"PeriodicalId\":94020,\"journal\":{\"name\":\"Genomics, proteomics & bioinformatics\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":7.9000,\"publicationDate\":\"2024-10-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11580686/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Genomics, proteomics & bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/gpbjnl/qzae048\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics, proteomics & bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/gpbjnl/qzae048","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
The Bioinformatic Applications of Hi-C and Linked Reads.
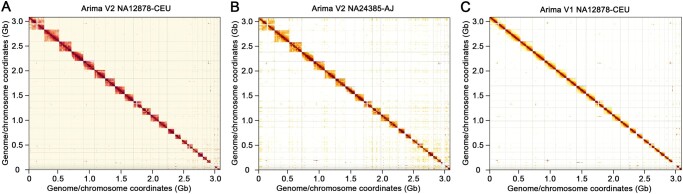
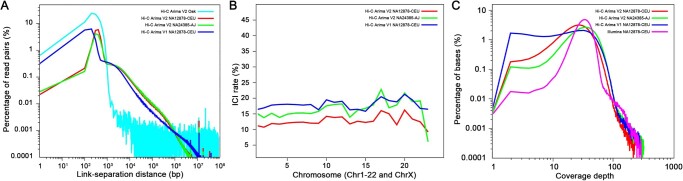
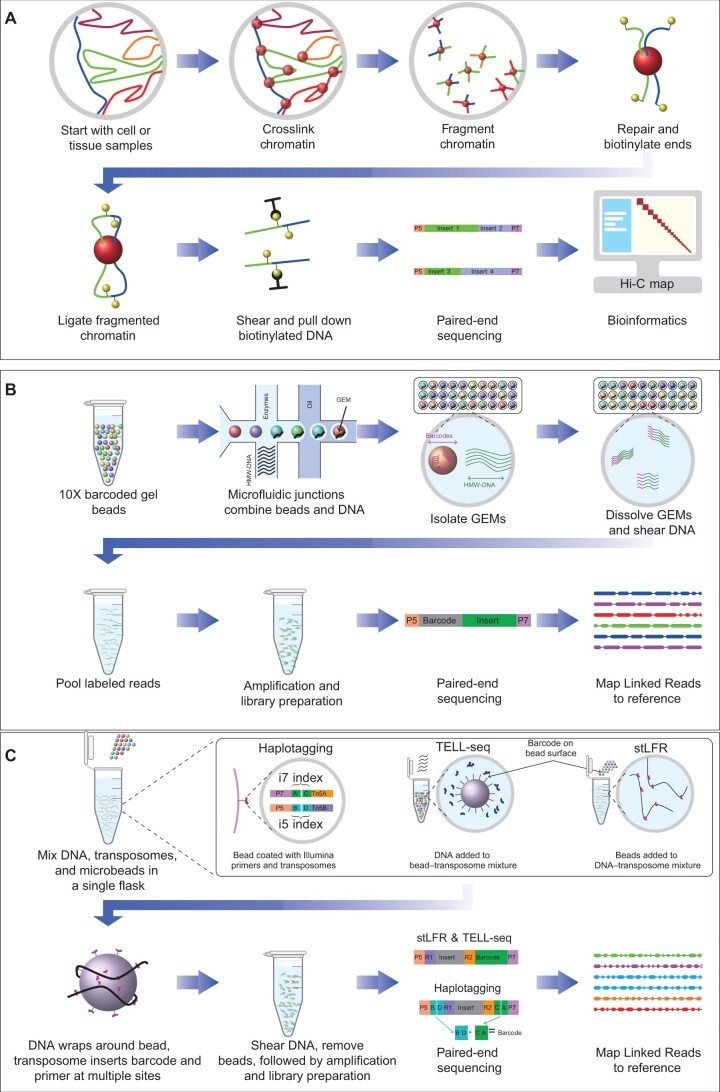
Long-range sequencing grants insight into additional genetic information beyond what can be accessed by both short reads and modern long-read technology. Several new sequencing technologies, such as "Hi-C" and "Linked Reads", produce long-range datasets for high-throughput and high-resolution genome analyses, which are rapidly advancing the field of genome assembly, genome scaffolding, and more comprehensive variant identification. In this review, we focused on five major long-range sequencing technologies: high-throughput chromosome conformation capture (Hi-C), 10X Genomics Linked Reads, haplotagging, transposase enzyme linked long-read sequencing (TELL-seq), and single- tube long fragment read (stLFR). We detailed the mechanisms and data products of the five platforms and their important applications, evaluated the quality of sequencing data from different platforms, and discussed the currently available bioinformatics tools. This work will benefit the selection of appropriate long-range technology for specific biological studies.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
