{"title":"使用机器翻译和 BERT 对希腊语文本进行问题解答的比较评估","authors":"Michalis Mountantonakis, Loukas Mertzanis, Michalis Bastakis, Yannis Tzitzikas","doi":"10.1007/s10579-024-09745-9","DOIUrl":null,"url":null,"abstract":"<p>Although there are numerous and effective BERT models for question answering (QA) over plain texts in English, it is not the same for other languages, such as Greek. Since it can be time-consuming to train a new BERT model for a given language, we present a generic methodology for multilingual QA by combining at runtime existing machine translation (MT) models and BERT QA models pretrained in English, and we perform a comparative evaluation for Greek language. Particularly, we propose a pipeline that (a) exploits widely used MT libraries for translating a question and a context from a source language to the English language, (b) extracts the answer from the translated English context through popular BERT models (pretrained in English corpus), (c) translates the answer back to the source language, and (d) evaluates the answer through semantic similarity metrics based on sentence embeddings, such as Bi-Encoder and BERTScore. For evaluating our system, we use 21 models, whereas we have created a test set with 20 texts and 200 questions and we have manually labelled 4200 answers. These resources can be reused for several tasks including QA and sentence similarity. Moreover, we use the existing multilingual test set XQuAD, with 240 texts and 1190 questions in Greek language. We focus on both the effectiveness and efficiency, through manually and machine labelled results. The results of the evaluation show that the proposed approach can be an efficient and effective alternative option to multilingual BERT. In particular, although the multilingual BERT QA model provides the highest scores for both human and automatic evaluation, all the models combining MT and BERT QA models are faster and some of them achieve quite similar scores.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"1782 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A comparative evaluation for question answering over Greek texts by using machine translation and BERT\",\"authors\":\"Michalis Mountantonakis, Loukas Mertzanis, Michalis Bastakis, Yannis Tzitzikas\",\"doi\":\"10.1007/s10579-024-09745-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Although there are numerous and effective BERT models for question answering (QA) over plain texts in English, it is not the same for other languages, such as Greek. Since it can be time-consuming to train a new BERT model for a given language, we present a generic methodology for multilingual QA by combining at runtime existing machine translation (MT) models and BERT QA models pretrained in English, and we perform a comparative evaluation for Greek language. Particularly, we propose a pipeline that (a) exploits widely used MT libraries for translating a question and a context from a source language to the English language, (b) extracts the answer from the translated English context through popular BERT models (pretrained in English corpus), (c) translates the answer back to the source language, and (d) evaluates the answer through semantic similarity metrics based on sentence embeddings, such as Bi-Encoder and BERTScore. For evaluating our system, we use 21 models, whereas we have created a test set with 20 texts and 200 questions and we have manually labelled 4200 answers. These resources can be reused for several tasks including QA and sentence similarity. Moreover, we use the existing multilingual test set XQuAD, with 240 texts and 1190 questions in Greek language. We focus on both the effectiveness and efficiency, through manually and machine labelled results. The results of the evaluation show that the proposed approach can be an efficient and effective alternative option to multilingual BERT. In particular, although the multilingual BERT QA model provides the highest scores for both human and automatic evaluation, all the models combining MT and BERT QA models are faster and some of them achieve quite similar scores.</p>\",\"PeriodicalId\":49927,\"journal\":{\"name\":\"Language Resources and Evaluation\",\"volume\":\"1782 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-06-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Language Resources and Evaluation\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10579-024-09745-9\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-024-09745-9","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
A comparative evaluation for question answering over Greek texts by using machine translation and BERT
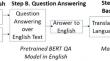
Although there are numerous and effective BERT models for question answering (QA) over plain texts in English, it is not the same for other languages, such as Greek. Since it can be time-consuming to train a new BERT model for a given language, we present a generic methodology for multilingual QA by combining at runtime existing machine translation (MT) models and BERT QA models pretrained in English, and we perform a comparative evaluation for Greek language. Particularly, we propose a pipeline that (a) exploits widely used MT libraries for translating a question and a context from a source language to the English language, (b) extracts the answer from the translated English context through popular BERT models (pretrained in English corpus), (c) translates the answer back to the source language, and (d) evaluates the answer through semantic similarity metrics based on sentence embeddings, such as Bi-Encoder and BERTScore. For evaluating our system, we use 21 models, whereas we have created a test set with 20 texts and 200 questions and we have manually labelled 4200 answers. These resources can be reused for several tasks including QA and sentence similarity. Moreover, we use the existing multilingual test set XQuAD, with 240 texts and 1190 questions in Greek language. We focus on both the effectiveness and efficiency, through manually and machine labelled results. The results of the evaluation show that the proposed approach can be an efficient and effective alternative option to multilingual BERT. In particular, although the multilingual BERT QA model provides the highest scores for both human and automatic evaluation, all the models combining MT and BERT QA models are faster and some of them achieve quite similar scores.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
