Aline Gendrin-Brokmann , Eden Harrison , Julianne Noveras , Leonidas Souliotis , Harris Vince , Ines Smit , Francisco Costa , David Milward , Sashka Dimitrievska , Paul Metcalfe , Emilie Louvet
{"title":"从科学文献中自动提取肿瘤疗效终点的深度学习 NLP 研究","authors":"Aline Gendrin-Brokmann , Eden Harrison , Julianne Noveras , Leonidas Souliotis , Harris Vince , Ines Smit , Francisco Costa , David Milward , Sashka Dimitrievska , Paul Metcalfe , Emilie Louvet","doi":"10.1016/j.ibmed.2024.100152","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>Benchmarking drug efficacy is a critical step in clinical trial design and planning. The challenge is that much of the data on efficacy endpoints is stored in scientific papers in free text form, so extraction of such data is currently a largely manual task. Our objective is to automate this task as much as possible.</p></div><div><h3>Methods</h3><p>In this study we have developed and optimised a framework to extract efficacy endpoints from text in scientific papers, using a machine learning approach.</p></div><div><h3>Results</h3><p>Our machine learning model predicts 25 classes associated with efficacy endpoints and leads to high F1 scores (harmonic mean of precision and recall) of 96.4 % on the test set, and 93.9 % and 93.7 % on two case studies.</p></div><div><h3>Conclusion</h3><p>These methods were evaluated against – and showed strong agreement with – subject matter experts and show significant promise in the future of automating the extraction of clinical endpoints from free text.</p></div><div><h3>Significance</h3><p>Clinical information extraction from text data is currently a laborious manual task which scales poorly and is prone to human error. Demonstrating the ability to extract efficacy endpoints automatically shows great promise for accelerating clinical trial design moving forwards.</p></div>","PeriodicalId":73399,"journal":{"name":"Intelligence-based medicine","volume":"10 ","pages":"Article 100152"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S266652122400019X/pdfft?md5=a92e134878dd46a959c3a33708e38779&pid=1-s2.0-S266652122400019X-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Investigating deep-learning NLP for automating the extraction of oncology efficacy endpoints from scientific literature\",\"authors\":\"Aline Gendrin-Brokmann , Eden Harrison , Julianne Noveras , Leonidas Souliotis , Harris Vince , Ines Smit , Francisco Costa , David Milward , Sashka Dimitrievska , Paul Metcalfe , Emilie Louvet\",\"doi\":\"10.1016/j.ibmed.2024.100152\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><p>Benchmarking drug efficacy is a critical step in clinical trial design and planning. The challenge is that much of the data on efficacy endpoints is stored in scientific papers in free text form, so extraction of such data is currently a largely manual task. Our objective is to automate this task as much as possible.</p></div><div><h3>Methods</h3><p>In this study we have developed and optimised a framework to extract efficacy endpoints from text in scientific papers, using a machine learning approach.</p></div><div><h3>Results</h3><p>Our machine learning model predicts 25 classes associated with efficacy endpoints and leads to high F1 scores (harmonic mean of precision and recall) of 96.4 % on the test set, and 93.9 % and 93.7 % on two case studies.</p></div><div><h3>Conclusion</h3><p>These methods were evaluated against – and showed strong agreement with – subject matter experts and show significant promise in the future of automating the extraction of clinical endpoints from free text.</p></div><div><h3>Significance</h3><p>Clinical information extraction from text data is currently a laborious manual task which scales poorly and is prone to human error. Demonstrating the ability to extract efficacy endpoints automatically shows great promise for accelerating clinical trial design moving forwards.</p></div>\",\"PeriodicalId\":73399,\"journal\":{\"name\":\"Intelligence-based medicine\",\"volume\":\"10 \",\"pages\":\"Article 100152\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S266652122400019X/pdfft?md5=a92e134878dd46a959c3a33708e38779&pid=1-s2.0-S266652122400019X-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Intelligence-based medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S266652122400019X\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/7/4 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Intelligence-based medicine","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S266652122400019X","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/4 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
目标以药物疗效为基准是临床试验设计和规划的关键步骤。面临的挑战是,大部分疗效终点数据都以自由文本形式存储在科学论文中,因此提取此类数据目前主要是一项人工任务。我们的机器学习模型预测了与疗效终点相关的 25 个类别,并在测试集上获得了 96.4% 的高 F1 分数(精确度和召回率的调和平均值),以及 93.9% 和 93.7% 的高 F1 分数(精确度和召回率的调和平均值)。结论根据主题专家的意见对这些方法进行了评估,结果表明这些方法与主题专家的意见非常一致,在未来从自由文本中自动提取临床终点方面大有可为。展示自动提取疗效终点的能力为加快临床试验设计的前进步伐带来了巨大希望。
Investigating deep-learning NLP for automating the extraction of oncology efficacy endpoints from scientific literature
Objective
Benchmarking drug efficacy is a critical step in clinical trial design and planning. The challenge is that much of the data on efficacy endpoints is stored in scientific papers in free text form, so extraction of such data is currently a largely manual task. Our objective is to automate this task as much as possible.
Methods
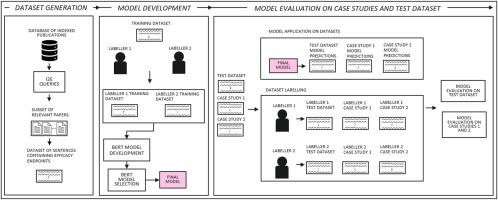
In this study we have developed and optimised a framework to extract efficacy endpoints from text in scientific papers, using a machine learning approach.
Results
Our machine learning model predicts 25 classes associated with efficacy endpoints and leads to high F1 scores (harmonic mean of precision and recall) of 96.4 % on the test set, and 93.9 % and 93.7 % on two case studies.
Conclusion
These methods were evaluated against – and showed strong agreement with – subject matter experts and show significant promise in the future of automating the extraction of clinical endpoints from free text.
Significance
Clinical information extraction from text data is currently a laborious manual task which scales poorly and is prone to human error. Demonstrating the ability to extract efficacy endpoints automatically shows great promise for accelerating clinical trial design moving forwards.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
