Lukas Leindals, Peter Grønning, Dominik Franjo Dominković, Rune Grønborg Junker
{"title":"使用含水层热能存储的数据中心冷却运行的情境感知强化学习","authors":"Lukas Leindals, Peter Grønning, Dominik Franjo Dominković, Rune Grønborg Junker","doi":"10.1016/j.egyai.2024.100395","DOIUrl":null,"url":null,"abstract":"<div><p>Data centers are often equipped with multiple cooling units. Here, an aquifer thermal energy storage (ATES) system has shown to be efficient. However, the usage of hot and cold-water wells in the ATES must be balanced for legal and environmental reasons. Reinforcement Learning has been proven to be a useful tool for optimizing the cooling operation at data centers. Nonetheless, since cooling demand changes continuously, balancing the ATES usage on a yearly basis imposes an additional challenge in the form of a delayed reward. To overcome this, we formulate a return decomposition, Cool-RUDDER, which relies on simple domain knowledge and needs no training. We trained a proximal policy optimization agent to keep server temperatures steady while minimizing operational costs. Comparing the Cool-RUDDER reward signal to other ATES-associated rewards, all models kept the server temperatures steady at around 30 °C. An optimal ATES balance was defined to be 0% and a yearly imbalance of −4.9% with a confidence interval of [−6.2, −3.8]% was achieved for the Cool 2.0 reward. This outperformed a baseline ATES-associated reward of 0 at −16.3% with a confidence interval of [−17.1, −15.4]% and all other ATES-associated rewards. However, the improved ATES balance comes with a higher energy consumption cost of 12.5% when comparing the relative cost of the Cool 2.0 reward to the zero reward, resulting in a trade-off. Moreover, the method comes with limited requirements and is applicable to any long-term problem satisfying a linear state-transition system.</p></div>","PeriodicalId":34138,"journal":{"name":"Energy and AI","volume":"17 ","pages":"Article 100395"},"PeriodicalIF":9.6000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2666546824000612/pdfft?md5=b17bfa78652179749ed19203f3f51d82&pid=1-s2.0-S2666546824000612-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Context-aware reinforcement learning for cooling operation of data centers with an Aquifer Thermal Energy Storage\",\"authors\":\"Lukas Leindals, Peter Grønning, Dominik Franjo Dominković, Rune Grønborg Junker\",\"doi\":\"10.1016/j.egyai.2024.100395\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Data centers are often equipped with multiple cooling units. Here, an aquifer thermal energy storage (ATES) system has shown to be efficient. However, the usage of hot and cold-water wells in the ATES must be balanced for legal and environmental reasons. Reinforcement Learning has been proven to be a useful tool for optimizing the cooling operation at data centers. Nonetheless, since cooling demand changes continuously, balancing the ATES usage on a yearly basis imposes an additional challenge in the form of a delayed reward. To overcome this, we formulate a return decomposition, Cool-RUDDER, which relies on simple domain knowledge and needs no training. We trained a proximal policy optimization agent to keep server temperatures steady while minimizing operational costs. Comparing the Cool-RUDDER reward signal to other ATES-associated rewards, all models kept the server temperatures steady at around 30 °C. An optimal ATES balance was defined to be 0% and a yearly imbalance of −4.9% with a confidence interval of [−6.2, −3.8]% was achieved for the Cool 2.0 reward. This outperformed a baseline ATES-associated reward of 0 at −16.3% with a confidence interval of [−17.1, −15.4]% and all other ATES-associated rewards. However, the improved ATES balance comes with a higher energy consumption cost of 12.5% when comparing the relative cost of the Cool 2.0 reward to the zero reward, resulting in a trade-off. Moreover, the method comes with limited requirements and is applicable to any long-term problem satisfying a linear state-transition system.</p></div>\",\"PeriodicalId\":34138,\"journal\":{\"name\":\"Energy and AI\",\"volume\":\"17 \",\"pages\":\"Article 100395\"},\"PeriodicalIF\":9.6000,\"publicationDate\":\"2024-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2666546824000612/pdfft?md5=b17bfa78652179749ed19203f3f51d82&pid=1-s2.0-S2666546824000612-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Energy and AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2666546824000612\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/7/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Energy and AI","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666546824000612","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/5 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
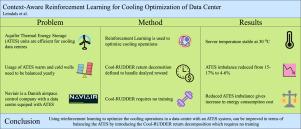
Context-aware reinforcement learning for cooling operation of data centers with an Aquifer Thermal Energy Storage
Data centers are often equipped with multiple cooling units. Here, an aquifer thermal energy storage (ATES) system has shown to be efficient. However, the usage of hot and cold-water wells in the ATES must be balanced for legal and environmental reasons. Reinforcement Learning has been proven to be a useful tool for optimizing the cooling operation at data centers. Nonetheless, since cooling demand changes continuously, balancing the ATES usage on a yearly basis imposes an additional challenge in the form of a delayed reward. To overcome this, we formulate a return decomposition, Cool-RUDDER, which relies on simple domain knowledge and needs no training. We trained a proximal policy optimization agent to keep server temperatures steady while minimizing operational costs. Comparing the Cool-RUDDER reward signal to other ATES-associated rewards, all models kept the server temperatures steady at around 30 °C. An optimal ATES balance was defined to be 0% and a yearly imbalance of −4.9% with a confidence interval of [−6.2, −3.8]% was achieved for the Cool 2.0 reward. This outperformed a baseline ATES-associated reward of 0 at −16.3% with a confidence interval of [−17.1, −15.4]% and all other ATES-associated rewards. However, the improved ATES balance comes with a higher energy consumption cost of 12.5% when comparing the relative cost of the Cool 2.0 reward to the zero reward, resulting in a trade-off. Moreover, the method comes with limited requirements and is applicable to any long-term problem satisfying a linear state-transition system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
