Melissa Sanabria, Jonas Hirsch, Pierre M. Joubert, Anna R. Poetsch
{"title":"DNA 语言模型 GROVER 学习人类基因组中的序列上下文","authors":"Melissa Sanabria, Jonas Hirsch, Pierre M. Joubert, Anna R. Poetsch","doi":"10.1038/s42256-024-00872-0","DOIUrl":null,"url":null,"abstract":"Deep-learning models that learn a sense of language on DNA have achieved a high level of performance on genome biological tasks. Genome sequences follow rules similar to natural language but are distinct in the absence of a concept of words. We established byte-pair encoding on the human genome and trained a foundation language model called GROVER (Genome Rules Obtained Via Extracted Representations) with the vocabulary selected via a custom task, next-k-mer prediction. The defined dictionary of tokens in the human genome carries best the information content for GROVER. Analysing learned representations, we observed that trained token embeddings primarily encode information related to frequency, sequence content and length. Some tokens are primarily localized in repeats, whereas the majority widely distribute over the genome. GROVER also learns context and lexical ambiguity. Average trained embeddings of genomic regions relate to functional genomics annotation and thus indicate learning of these structures purely from the contextual relationships of tokens. This highlights the extent of information content encoded by the sequence that can be grasped by GROVER. On fine-tuning tasks addressing genome biology with questions of genome element identification and protein–DNA binding, GROVER exceeds other models’ performance. GROVER learns sequence context, a sense for structure and language rules. Extracting this knowledge can be used to compose a grammar book for the code of life. Genomes can be modelled with language approaches by treating nucleotide bases A, C, G and T like text, but there is no natural concept of what the words would be and whether there is even a ‘language’ to be learned this way. Sanabria et al. have developed a language model called GROVER that learns with a ‘vocabulary’ of genome sequences with byte-pair encoding, a method from text compression, and shows good performance on genome biological tasks.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"6 8","pages":"911-923"},"PeriodicalIF":23.9000,"publicationDate":"2024-07-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s42256-024-00872-0.pdf","citationCount":"0","resultStr":"{\"title\":\"DNA language model GROVER learns sequence context in the human genome\",\"authors\":\"Melissa Sanabria, Jonas Hirsch, Pierre M. Joubert, Anna R. Poetsch\",\"doi\":\"10.1038/s42256-024-00872-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Deep-learning models that learn a sense of language on DNA have achieved a high level of performance on genome biological tasks. Genome sequences follow rules similar to natural language but are distinct in the absence of a concept of words. We established byte-pair encoding on the human genome and trained a foundation language model called GROVER (Genome Rules Obtained Via Extracted Representations) with the vocabulary selected via a custom task, next-k-mer prediction. The defined dictionary of tokens in the human genome carries best the information content for GROVER. Analysing learned representations, we observed that trained token embeddings primarily encode information related to frequency, sequence content and length. Some tokens are primarily localized in repeats, whereas the majority widely distribute over the genome. GROVER also learns context and lexical ambiguity. Average trained embeddings of genomic regions relate to functional genomics annotation and thus indicate learning of these structures purely from the contextual relationships of tokens. This highlights the extent of information content encoded by the sequence that can be grasped by GROVER. On fine-tuning tasks addressing genome biology with questions of genome element identification and protein–DNA binding, GROVER exceeds other models’ performance. GROVER learns sequence context, a sense for structure and language rules. Extracting this knowledge can be used to compose a grammar book for the code of life. Genomes can be modelled with language approaches by treating nucleotide bases A, C, G and T like text, but there is no natural concept of what the words would be and whether there is even a ‘language’ to be learned this way. Sanabria et al. have developed a language model called GROVER that learns with a ‘vocabulary’ of genome sequences with byte-pair encoding, a method from text compression, and shows good performance on genome biological tasks.\",\"PeriodicalId\":48533,\"journal\":{\"name\":\"Nature Machine Intelligence\",\"volume\":\"6 8\",\"pages\":\"911-923\"},\"PeriodicalIF\":23.9000,\"publicationDate\":\"2024-07-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s42256-024-00872-0.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Machine Intelligence\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.nature.com/articles/s42256-024-00872-0\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00872-0","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
DNA language model GROVER learns sequence context in the human genome
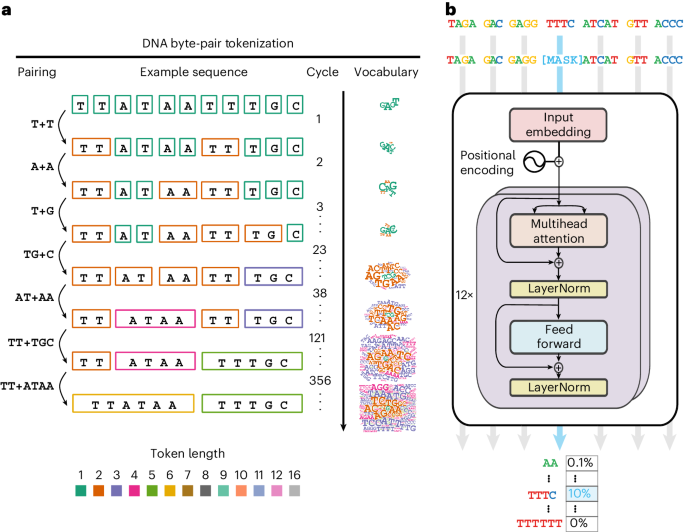
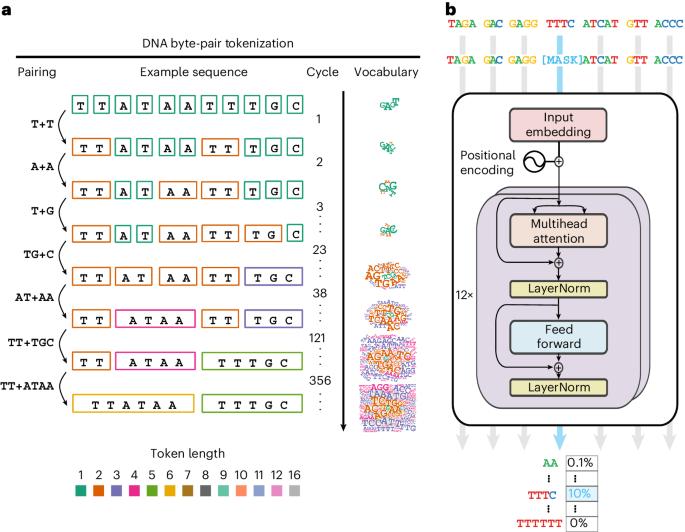
Deep-learning models that learn a sense of language on DNA have achieved a high level of performance on genome biological tasks. Genome sequences follow rules similar to natural language but are distinct in the absence of a concept of words. We established byte-pair encoding on the human genome and trained a foundation language model called GROVER (Genome Rules Obtained Via Extracted Representations) with the vocabulary selected via a custom task, next-k-mer prediction. The defined dictionary of tokens in the human genome carries best the information content for GROVER. Analysing learned representations, we observed that trained token embeddings primarily encode information related to frequency, sequence content and length. Some tokens are primarily localized in repeats, whereas the majority widely distribute over the genome. GROVER also learns context and lexical ambiguity. Average trained embeddings of genomic regions relate to functional genomics annotation and thus indicate learning of these structures purely from the contextual relationships of tokens. This highlights the extent of information content encoded by the sequence that can be grasped by GROVER. On fine-tuning tasks addressing genome biology with questions of genome element identification and protein–DNA binding, GROVER exceeds other models’ performance. GROVER learns sequence context, a sense for structure and language rules. Extracting this knowledge can be used to compose a grammar book for the code of life. Genomes can be modelled with language approaches by treating nucleotide bases A, C, G and T like text, but there is no natural concept of what the words would be and whether there is even a ‘language’ to be learned this way. Sanabria et al. have developed a language model called GROVER that learns with a ‘vocabulary’ of genome sequences with byte-pair encoding, a method from text compression, and shows good performance on genome biological tasks.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
