Kyeryoung Lee, Zongzhi Liu, Yun Mai, Tomi Jun, Meng Ma, Tongyu Wang, Lei Ai, Ediz Calay, William Oh, Gustavo Stolovitzky, Eric Schadt, Xiaoyan Wang
{"title":"利用自然语言处理模型和真实世界数据优化临床试验资格设计:算法开发与验证。","authors":"Kyeryoung Lee, Zongzhi Liu, Yun Mai, Tomi Jun, Meng Ma, Tongyu Wang, Lei Ai, Ediz Calay, William Oh, Gustavo Stolovitzky, Eric Schadt, Xiaoyan Wang","doi":"10.2196/50800","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Clinical trials are vital for developing new therapies but can also delay drug development. Efficient trial data management, optimized trial protocol, and accurate patient identification are critical for reducing trial timelines. Natural language processing (NLP) has the potential to achieve these objectives.</p><p><strong>Objective: </strong>This study aims to assess the feasibility of using data-driven approaches to optimize clinical trial protocol design and identify eligible patients. This involves creating a comprehensive eligibility criteria knowledge base integrated within electronic health records using deep learning-based NLP techniques.</p><p><strong>Methods: </strong>We obtained data of 3281 industry-sponsored phase 2 or 3 interventional clinical trials recruiting patients with non-small cell lung cancer, prostate cancer, breast cancer, multiple myeloma, ulcerative colitis, and Crohn disease from ClinicalTrials.gov, spanning the period between 2013 and 2020. A customized bidirectional long short-term memory- and conditional random field-based NLP pipeline was used to extract all eligibility criteria attributes and convert hypernym concepts into computable hyponyms along with their corresponding values. To illustrate the simulation of clinical trial design for optimization purposes, we selected a subset of patients with non-small cell lung cancer (n=2775), curated from the Mount Sinai Health System, as a pilot study.</p><p><strong>Results: </strong>We manually annotated the clinical trial eligibility corpus (485/3281, 14.78% trials) and constructed an eligibility criteria-specific ontology. Our customized NLP pipeline, developed based on the eligibility criteria-specific ontology that we created through manual annotation, achieved high precision (0.91, range 0.67-1.00) and recall (0.79, range 0.50-1) scores, as well as a high F<sub>1</sub>-score (0.83, range 0.67-1), enabling the efficient extraction of granular criteria entities and relevant attributes from 3281 clinical trials. A standardized eligibility criteria knowledge base, compatible with electronic health records, was developed by transforming hypernym concepts into machine-interpretable hyponyms along with their corresponding values. In addition, an interface prototype demonstrated the practicality of leveraging real-world data for optimizing clinical trial protocols and identifying eligible patients.</p><p><strong>Conclusions: </strong>Our customized NLP pipeline successfully generated a standardized eligibility criteria knowledge base by transforming hypernym criteria into machine-readable hyponyms along with their corresponding values. A prototype interface integrating real-world patient information allows us to assess the impact of each eligibility criterion on the number of patients eligible for the trial. Leveraging NLP and real-world data in a data-driven approach holds promise for streamlining the overall clinical trial process, optimizing processes, and improving efficiency in patient identification.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"3 ","pages":"e50800"},"PeriodicalIF":2.0000,"publicationDate":"2024-07-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11319878/pdf/","citationCount":"0","resultStr":"{\"title\":\"Optimizing Clinical Trial Eligibility Design Using Natural Language Processing Models and Real-World Data: Algorithm Development and Validation.\",\"authors\":\"Kyeryoung Lee, Zongzhi Liu, Yun Mai, Tomi Jun, Meng Ma, Tongyu Wang, Lei Ai, Ediz Calay, William Oh, Gustavo Stolovitzky, Eric Schadt, Xiaoyan Wang\",\"doi\":\"10.2196/50800\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Clinical trials are vital for developing new therapies but can also delay drug development. Efficient trial data management, optimized trial protocol, and accurate patient identification are critical for reducing trial timelines. Natural language processing (NLP) has the potential to achieve these objectives.</p><p><strong>Objective: </strong>This study aims to assess the feasibility of using data-driven approaches to optimize clinical trial protocol design and identify eligible patients. This involves creating a comprehensive eligibility criteria knowledge base integrated within electronic health records using deep learning-based NLP techniques.</p><p><strong>Methods: </strong>We obtained data of 3281 industry-sponsored phase 2 or 3 interventional clinical trials recruiting patients with non-small cell lung cancer, prostate cancer, breast cancer, multiple myeloma, ulcerative colitis, and Crohn disease from ClinicalTrials.gov, spanning the period between 2013 and 2020. A customized bidirectional long short-term memory- and conditional random field-based NLP pipeline was used to extract all eligibility criteria attributes and convert hypernym concepts into computable hyponyms along with their corresponding values. To illustrate the simulation of clinical trial design for optimization purposes, we selected a subset of patients with non-small cell lung cancer (n=2775), curated from the Mount Sinai Health System, as a pilot study.</p><p><strong>Results: </strong>We manually annotated the clinical trial eligibility corpus (485/3281, 14.78% trials) and constructed an eligibility criteria-specific ontology. Our customized NLP pipeline, developed based on the eligibility criteria-specific ontology that we created through manual annotation, achieved high precision (0.91, range 0.67-1.00) and recall (0.79, range 0.50-1) scores, as well as a high F<sub>1</sub>-score (0.83, range 0.67-1), enabling the efficient extraction of granular criteria entities and relevant attributes from 3281 clinical trials. A standardized eligibility criteria knowledge base, compatible with electronic health records, was developed by transforming hypernym concepts into machine-interpretable hyponyms along with their corresponding values. In addition, an interface prototype demonstrated the practicality of leveraging real-world data for optimizing clinical trial protocols and identifying eligible patients.</p><p><strong>Conclusions: </strong>Our customized NLP pipeline successfully generated a standardized eligibility criteria knowledge base by transforming hypernym criteria into machine-readable hyponyms along with their corresponding values. A prototype interface integrating real-world patient information allows us to assess the impact of each eligibility criterion on the number of patients eligible for the trial. Leveraging NLP and real-world data in a data-driven approach holds promise for streamlining the overall clinical trial process, optimizing processes, and improving efficiency in patient identification.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"3 \",\"pages\":\"e50800\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-07-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11319878/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/50800\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/50800","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Optimizing Clinical Trial Eligibility Design Using Natural Language Processing Models and Real-World Data: Algorithm Development and Validation.
Background: Clinical trials are vital for developing new therapies but can also delay drug development. Efficient trial data management, optimized trial protocol, and accurate patient identification are critical for reducing trial timelines. Natural language processing (NLP) has the potential to achieve these objectives.
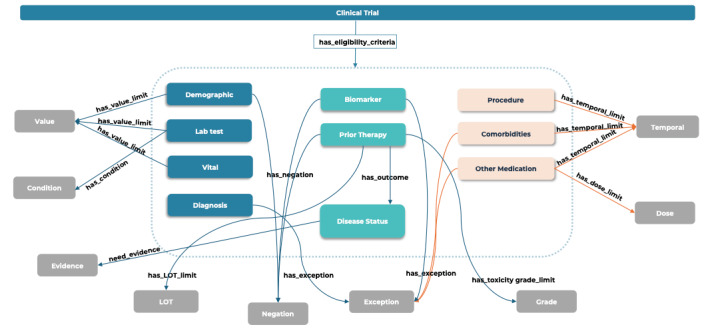
Objective: This study aims to assess the feasibility of using data-driven approaches to optimize clinical trial protocol design and identify eligible patients. This involves creating a comprehensive eligibility criteria knowledge base integrated within electronic health records using deep learning-based NLP techniques.
Methods: We obtained data of 3281 industry-sponsored phase 2 or 3 interventional clinical trials recruiting patients with non-small cell lung cancer, prostate cancer, breast cancer, multiple myeloma, ulcerative colitis, and Crohn disease from ClinicalTrials.gov, spanning the period between 2013 and 2020. A customized bidirectional long short-term memory- and conditional random field-based NLP pipeline was used to extract all eligibility criteria attributes and convert hypernym concepts into computable hyponyms along with their corresponding values. To illustrate the simulation of clinical trial design for optimization purposes, we selected a subset of patients with non-small cell lung cancer (n=2775), curated from the Mount Sinai Health System, as a pilot study.
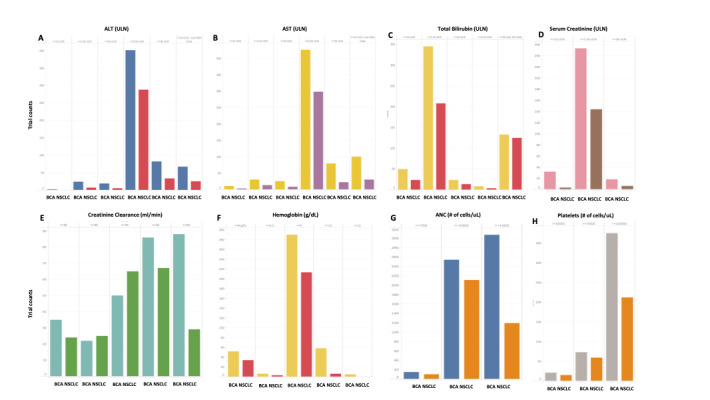
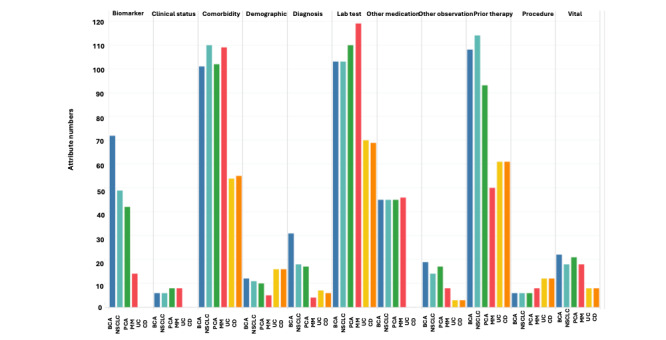
Results: We manually annotated the clinical trial eligibility corpus (485/3281, 14.78% trials) and constructed an eligibility criteria-specific ontology. Our customized NLP pipeline, developed based on the eligibility criteria-specific ontology that we created through manual annotation, achieved high precision (0.91, range 0.67-1.00) and recall (0.79, range 0.50-1) scores, as well as a high F1-score (0.83, range 0.67-1), enabling the efficient extraction of granular criteria entities and relevant attributes from 3281 clinical trials. A standardized eligibility criteria knowledge base, compatible with electronic health records, was developed by transforming hypernym concepts into machine-interpretable hyponyms along with their corresponding values. In addition, an interface prototype demonstrated the practicality of leveraging real-world data for optimizing clinical trial protocols and identifying eligible patients.
Conclusions: Our customized NLP pipeline successfully generated a standardized eligibility criteria knowledge base by transforming hypernym criteria into machine-readable hyponyms along with their corresponding values. A prototype interface integrating real-world patient information allows us to assess the impact of each eligibility criterion on the number of patients eligible for the trial. Leveraging NLP and real-world data in a data-driven approach holds promise for streamlining the overall clinical trial process, optimizing processes, and improving efficiency in patient identification.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
