Maximo R Prescott, Samantha Yeager, Lillian Ham, Carlos D Rivera Saldana, Vanessa Serrano, Joey Narez, Dafna Paltin, Jorge Delgado, David J Moore, Jessica Montoya
{"title":"比较人工智能和生成式人工智能的功效和效率:定性专题分析。","authors":"Maximo R Prescott, Samantha Yeager, Lillian Ham, Carlos D Rivera Saldana, Vanessa Serrano, Joey Narez, Dafna Paltin, Jorge Delgado, David J Moore, Jessica Montoya","doi":"10.2196/54482","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Qualitative methods are incredibly beneficial to the dissemination and implementation of new digital health interventions; however, these methods can be time intensive and slow down dissemination when timely knowledge from the data sources is needed in ever-changing health systems. Recent advancements in generative artificial intelligence (GenAI) and their underlying large language models (LLMs) may provide a promising opportunity to expedite the qualitative analysis of textual data, but their efficacy and reliability remain unknown.</p><p><strong>Objective: </strong>The primary objectives of our study were to evaluate the consistency in themes, reliability of coding, and time needed for inductive and deductive thematic analyses between GenAI (ie, ChatGPT and Bard) and human coders.</p><p><strong>Methods: </strong>The qualitative data for this study consisted of 40 brief SMS text message reminder prompts used in a digital health intervention for promoting antiretroviral medication adherence among people with HIV who use methamphetamine. Inductive and deductive thematic analyses of these SMS text messages were conducted by 2 independent teams of human coders. An independent human analyst conducted analyses following both approaches using ChatGPT and Bard. The consistency in themes (or the extent to which the themes were the same) and reliability (or agreement in coding of themes) between methods were compared.</p><p><strong>Results: </strong>The themes generated by GenAI (both ChatGPT and Bard) were consistent with 71% (5/7) of the themes identified by human analysts following inductive thematic analysis. The consistency in themes was lower between humans and GenAI following a deductive thematic analysis procedure (ChatGPT: 6/12, 50%; Bard: 7/12, 58%). The percentage agreement (or intercoder reliability) for these congruent themes between human coders and GenAI ranged from fair to moderate (ChatGPT, inductive: 31/66, 47%; ChatGPT, deductive: 22/59, 37%; Bard, inductive: 20/54, 37%; Bard, deductive: 21/58, 36%). In general, ChatGPT and Bard performed similarly to each other across both types of qualitative analyses in terms of consistency of themes (inductive: 6/6, 100%; deductive: 5/6, 83%) and reliability of coding (inductive: 23/62, 37%; deductive: 22/47, 47%). On average, GenAI required significantly less overall time than human coders when conducting qualitative analysis (20, SD 3.5 min vs 567, SD 106.5 min).</p><p><strong>Conclusions: </strong>The promising consistency in the themes generated by human coders and GenAI suggests that these technologies hold promise in reducing the resource intensiveness of qualitative thematic analysis; however, the relatively lower reliability in coding between them suggests that hybrid approaches are necessary. Human coders appeared to be better than GenAI at identifying nuanced and interpretative themes. Future studies should consider how these powerful technologies can be best used in collaboration with human coders to improve the efficiency of qualitative research in hybrid approaches while also mitigating potential ethical risks that they may pose.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"3 ","pages":"e54482"},"PeriodicalIF":2.0000,"publicationDate":"2024-08-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11329846/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparing the Efficacy and Efficiency of Human and Generative AI: Qualitative Thematic Analyses.\",\"authors\":\"Maximo R Prescott, Samantha Yeager, Lillian Ham, Carlos D Rivera Saldana, Vanessa Serrano, Joey Narez, Dafna Paltin, Jorge Delgado, David J Moore, Jessica Montoya\",\"doi\":\"10.2196/54482\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Qualitative methods are incredibly beneficial to the dissemination and implementation of new digital health interventions; however, these methods can be time intensive and slow down dissemination when timely knowledge from the data sources is needed in ever-changing health systems. Recent advancements in generative artificial intelligence (GenAI) and their underlying large language models (LLMs) may provide a promising opportunity to expedite the qualitative analysis of textual data, but their efficacy and reliability remain unknown.</p><p><strong>Objective: </strong>The primary objectives of our study were to evaluate the consistency in themes, reliability of coding, and time needed for inductive and deductive thematic analyses between GenAI (ie, ChatGPT and Bard) and human coders.</p><p><strong>Methods: </strong>The qualitative data for this study consisted of 40 brief SMS text message reminder prompts used in a digital health intervention for promoting antiretroviral medication adherence among people with HIV who use methamphetamine. Inductive and deductive thematic analyses of these SMS text messages were conducted by 2 independent teams of human coders. An independent human analyst conducted analyses following both approaches using ChatGPT and Bard. The consistency in themes (or the extent to which the themes were the same) and reliability (or agreement in coding of themes) between methods were compared.</p><p><strong>Results: </strong>The themes generated by GenAI (both ChatGPT and Bard) were consistent with 71% (5/7) of the themes identified by human analysts following inductive thematic analysis. The consistency in themes was lower between humans and GenAI following a deductive thematic analysis procedure (ChatGPT: 6/12, 50%; Bard: 7/12, 58%). The percentage agreement (or intercoder reliability) for these congruent themes between human coders and GenAI ranged from fair to moderate (ChatGPT, inductive: 31/66, 47%; ChatGPT, deductive: 22/59, 37%; Bard, inductive: 20/54, 37%; Bard, deductive: 21/58, 36%). In general, ChatGPT and Bard performed similarly to each other across both types of qualitative analyses in terms of consistency of themes (inductive: 6/6, 100%; deductive: 5/6, 83%) and reliability of coding (inductive: 23/62, 37%; deductive: 22/47, 47%). On average, GenAI required significantly less overall time than human coders when conducting qualitative analysis (20, SD 3.5 min vs 567, SD 106.5 min).</p><p><strong>Conclusions: </strong>The promising consistency in the themes generated by human coders and GenAI suggests that these technologies hold promise in reducing the resource intensiveness of qualitative thematic analysis; however, the relatively lower reliability in coding between them suggests that hybrid approaches are necessary. Human coders appeared to be better than GenAI at identifying nuanced and interpretative themes. Future studies should consider how these powerful technologies can be best used in collaboration with human coders to improve the efficiency of qualitative research in hybrid approaches while also mitigating potential ethical risks that they may pose.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"3 \",\"pages\":\"e54482\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-08-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11329846/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/54482\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/54482","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Comparing the Efficacy and Efficiency of Human and Generative AI: Qualitative Thematic Analyses.
Background: Qualitative methods are incredibly beneficial to the dissemination and implementation of new digital health interventions; however, these methods can be time intensive and slow down dissemination when timely knowledge from the data sources is needed in ever-changing health systems. Recent advancements in generative artificial intelligence (GenAI) and their underlying large language models (LLMs) may provide a promising opportunity to expedite the qualitative analysis of textual data, but their efficacy and reliability remain unknown.
Objective: The primary objectives of our study were to evaluate the consistency in themes, reliability of coding, and time needed for inductive and deductive thematic analyses between GenAI (ie, ChatGPT and Bard) and human coders.
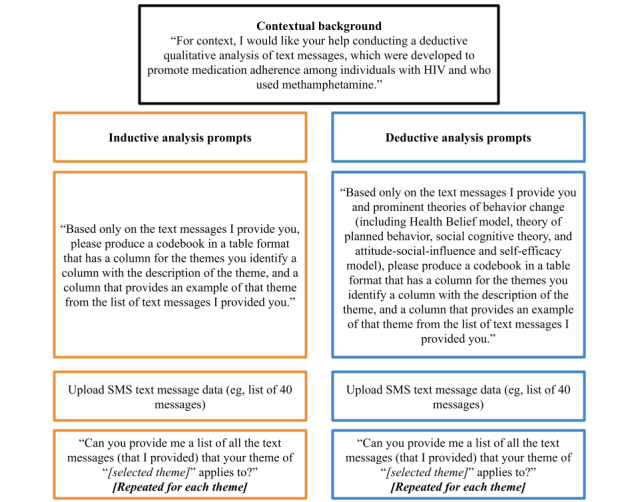
Methods: The qualitative data for this study consisted of 40 brief SMS text message reminder prompts used in a digital health intervention for promoting antiretroviral medication adherence among people with HIV who use methamphetamine. Inductive and deductive thematic analyses of these SMS text messages were conducted by 2 independent teams of human coders. An independent human analyst conducted analyses following both approaches using ChatGPT and Bard. The consistency in themes (or the extent to which the themes were the same) and reliability (or agreement in coding of themes) between methods were compared.
Results: The themes generated by GenAI (both ChatGPT and Bard) were consistent with 71% (5/7) of the themes identified by human analysts following inductive thematic analysis. The consistency in themes was lower between humans and GenAI following a deductive thematic analysis procedure (ChatGPT: 6/12, 50%; Bard: 7/12, 58%). The percentage agreement (or intercoder reliability) for these congruent themes between human coders and GenAI ranged from fair to moderate (ChatGPT, inductive: 31/66, 47%; ChatGPT, deductive: 22/59, 37%; Bard, inductive: 20/54, 37%; Bard, deductive: 21/58, 36%). In general, ChatGPT and Bard performed similarly to each other across both types of qualitative analyses in terms of consistency of themes (inductive: 6/6, 100%; deductive: 5/6, 83%) and reliability of coding (inductive: 23/62, 37%; deductive: 22/47, 47%). On average, GenAI required significantly less overall time than human coders when conducting qualitative analysis (20, SD 3.5 min vs 567, SD 106.5 min).
Conclusions: The promising consistency in the themes generated by human coders and GenAI suggests that these technologies hold promise in reducing the resource intensiveness of qualitative thematic analysis; however, the relatively lower reliability in coding between them suggests that hybrid approaches are necessary. Human coders appeared to be better than GenAI at identifying nuanced and interpretative themes. Future studies should consider how these powerful technologies can be best used in collaboration with human coders to improve the efficiency of qualitative research in hybrid approaches while also mitigating potential ethical risks that they may pose.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
