Surbhi Mittal, Kartik Thakral, Richa Singh, Mayank Vatsa, Tamar Glaser, Cristian Canton Ferrer, Tal Hassner
{"title":"以生物识别和医疗保健领域为例,介绍强调公平、隐私和监管规范的负责任机器学习数据集","authors":"Surbhi Mittal, Kartik Thakral, Richa Singh, Mayank Vatsa, Tamar Glaser, Cristian Canton Ferrer, Tal Hassner","doi":"10.1038/s42256-024-00874-y","DOIUrl":null,"url":null,"abstract":"Artificial Intelligence (AI) has seamlessly integrated into numerous scientific domains, catalysing unparalleled enhancements across a broad spectrum of tasks; however, its integrity and trustworthiness have emerged as notable concerns. The scientific community has focused on the development of trustworthy AI algorithms; however, machine learning and deep learning algorithms, popular in the AI community today, intrinsically rely on the quality of their training data. These algorithms are designed to detect patterns within the data, thereby learning the intended behavioural objectives. Any inadequacy in the data has the potential to translate directly into algorithms. In this study we discuss the importance of responsible machine learning datasets through the lens of fairness, privacy and regulatory compliance, and present a large audit of computer vision datasets. Despite the ubiquity of fairness and privacy challenges across diverse data domains, current regulatory frameworks primarily address human-centric data concerns. We therefore focus our discussion on biometric and healthcare datasets, although the principles we outline are broadly applicable across various domains. The audit is conducted through evaluation of the proposed responsible rubric. After surveying over 100 datasets, our detailed analysis of 60 distinct datasets highlights a universal susceptibility to fairness, privacy and regulatory compliance issues. This finding emphasizes the urgent need for revising dataset creation methodologies within the scientific community, especially in light of global advancements in data protection legislation. We assert that our study is critically relevant in the contemporary AI context, offering insights and recommendations that are both timely and essential for the ongoing evolution of AI technologies. There are pervasive concerns related to fairness, privacy and regulatory compliance in machine learning applications in healthcare, necessitating a reevaluation of dataset creation practices. Mittal et al. examine various computer vision datasets, providing insights to foster responsible AI development.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"6 8","pages":"936-949"},"PeriodicalIF":18.8000,"publicationDate":"2024-08-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s42256-024-00874-y.pdf","citationCount":"0","resultStr":"{\"title\":\"On responsible machine learning datasets emphasizing fairness, privacy and regulatory norms with examples in biometrics and healthcare\",\"authors\":\"Surbhi Mittal, Kartik Thakral, Richa Singh, Mayank Vatsa, Tamar Glaser, Cristian Canton Ferrer, Tal Hassner\",\"doi\":\"10.1038/s42256-024-00874-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Artificial Intelligence (AI) has seamlessly integrated into numerous scientific domains, catalysing unparalleled enhancements across a broad spectrum of tasks; however, its integrity and trustworthiness have emerged as notable concerns. The scientific community has focused on the development of trustworthy AI algorithms; however, machine learning and deep learning algorithms, popular in the AI community today, intrinsically rely on the quality of their training data. These algorithms are designed to detect patterns within the data, thereby learning the intended behavioural objectives. Any inadequacy in the data has the potential to translate directly into algorithms. In this study we discuss the importance of responsible machine learning datasets through the lens of fairness, privacy and regulatory compliance, and present a large audit of computer vision datasets. Despite the ubiquity of fairness and privacy challenges across diverse data domains, current regulatory frameworks primarily address human-centric data concerns. We therefore focus our discussion on biometric and healthcare datasets, although the principles we outline are broadly applicable across various domains. The audit is conducted through evaluation of the proposed responsible rubric. After surveying over 100 datasets, our detailed analysis of 60 distinct datasets highlights a universal susceptibility to fairness, privacy and regulatory compliance issues. This finding emphasizes the urgent need for revising dataset creation methodologies within the scientific community, especially in light of global advancements in data protection legislation. We assert that our study is critically relevant in the contemporary AI context, offering insights and recommendations that are both timely and essential for the ongoing evolution of AI technologies. There are pervasive concerns related to fairness, privacy and regulatory compliance in machine learning applications in healthcare, necessitating a reevaluation of dataset creation practices. Mittal et al. examine various computer vision datasets, providing insights to foster responsible AI development.\",\"PeriodicalId\":48533,\"journal\":{\"name\":\"Nature Machine Intelligence\",\"volume\":\"6 8\",\"pages\":\"936-949\"},\"PeriodicalIF\":18.8000,\"publicationDate\":\"2024-08-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s42256-024-00874-y.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Machine Intelligence\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.nature.com/articles/s42256-024-00874-y\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00874-y","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
On responsible machine learning datasets emphasizing fairness, privacy and regulatory norms with examples in biometrics and healthcare
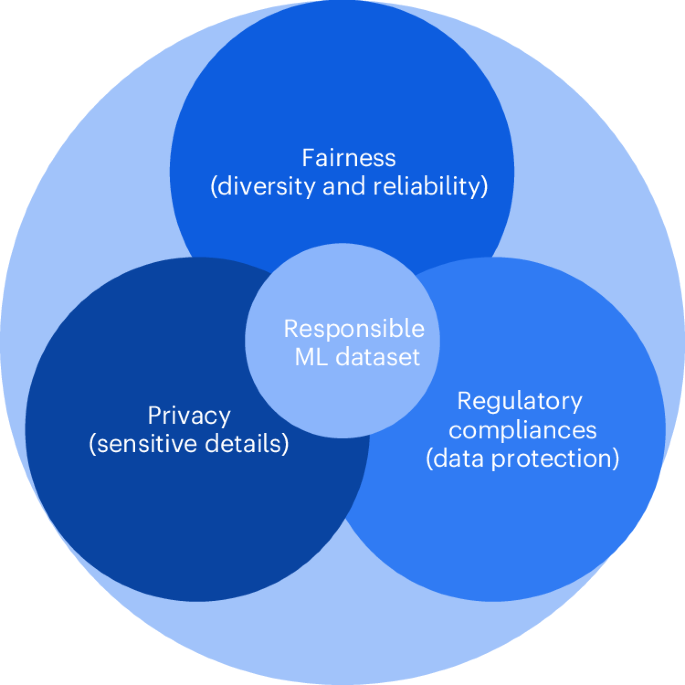
Artificial Intelligence (AI) has seamlessly integrated into numerous scientific domains, catalysing unparalleled enhancements across a broad spectrum of tasks; however, its integrity and trustworthiness have emerged as notable concerns. The scientific community has focused on the development of trustworthy AI algorithms; however, machine learning and deep learning algorithms, popular in the AI community today, intrinsically rely on the quality of their training data. These algorithms are designed to detect patterns within the data, thereby learning the intended behavioural objectives. Any inadequacy in the data has the potential to translate directly into algorithms. In this study we discuss the importance of responsible machine learning datasets through the lens of fairness, privacy and regulatory compliance, and present a large audit of computer vision datasets. Despite the ubiquity of fairness and privacy challenges across diverse data domains, current regulatory frameworks primarily address human-centric data concerns. We therefore focus our discussion on biometric and healthcare datasets, although the principles we outline are broadly applicable across various domains. The audit is conducted through evaluation of the proposed responsible rubric. After surveying over 100 datasets, our detailed analysis of 60 distinct datasets highlights a universal susceptibility to fairness, privacy and regulatory compliance issues. This finding emphasizes the urgent need for revising dataset creation methodologies within the scientific community, especially in light of global advancements in data protection legislation. We assert that our study is critically relevant in the contemporary AI context, offering insights and recommendations that are both timely and essential for the ongoing evolution of AI technologies. There are pervasive concerns related to fairness, privacy and regulatory compliance in machine learning applications in healthcare, necessitating a reevaluation of dataset creation practices. Mittal et al. examine various computer vision datasets, providing insights to foster responsible AI development.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
