Andrew Guide, Shawn Garbett, Xiaoke Feng, Brandy M Mapes, Justin Cook, Lina Sulieman, Robert M Cronin, Qingxia Chen
{"title":"平衡功效与计算负担:针对可靠量表中项目无响应的加权平均法、多重估算法和反向概率加权法。","authors":"Andrew Guide, Shawn Garbett, Xiaoke Feng, Brandy M Mapes, Justin Cook, Lina Sulieman, Robert M Cronin, Qingxia Chen","doi":"10.1093/jamia/ocae217","DOIUrl":null,"url":null,"abstract":"<p><strong>Importance: </strong>Scales often arise from multi-item questionnaires, yet commonly face item non-response. Traditional solutions use weighted mean (WMean) from available responses, but potentially overlook missing data intricacies. Advanced methods like multiple imputation (MI) address broader missing data, but demand increased computational resources. Researchers frequently use survey data in the All of Us Research Program (All of Us), and it is imperative to determine if the increased computational burden of employing MI to handle non-response is justifiable.</p><p><strong>Objectives: </strong>Using the 5-item Physical Activity Neighborhood Environment Scale (PANES) in All of Us, this study assessed the tradeoff between efficacy and computational demands of WMean, MI, and inverse probability weighting (IPW) when dealing with item non-response.</p><p><strong>Materials and methods: </strong>Synthetic missingness, allowing 1 or more item non-response, was introduced into PANES across 3 missing mechanisms and various missing percentages (10%-50%). Each scenario compared WMean of complete questions, MI, and IPW on bias, variability, coverage probability, and computation time.</p><p><strong>Results: </strong>All methods showed minimal biases (all <5.5%) for good internal consistency, with WMean suffered most with poor consistency. IPW showed considerable variability with increasing missing percentage. MI required significantly more computational resources, taking >8000 and >100 times longer than WMean and IPW in full data analysis, respectively.</p><p><strong>Discussion and conclusion: </strong>The marginal performance advantages of MI for item non-response in highly reliable scales do not warrant its escalated cloud computational burden in All of Us, particularly when coupled with computationally demanding post-imputation analyses. Researchers using survey scales with low missingness could utilize WMean to reduce computing burden.</p>","PeriodicalId":50016,"journal":{"name":"Journal of the American Medical Informatics Association","volume":" ","pages":"2869-2879"},"PeriodicalIF":7.1000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11631082/pdf/","citationCount":"0","resultStr":"{\"title\":\"Balancing efficacy and computational burden: weighted mean, multiple imputation, and inverse probability weighting methods for item non-response in reliable scales.\",\"authors\":\"Andrew Guide, Shawn Garbett, Xiaoke Feng, Brandy M Mapes, Justin Cook, Lina Sulieman, Robert M Cronin, Qingxia Chen\",\"doi\":\"10.1093/jamia/ocae217\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Importance: </strong>Scales often arise from multi-item questionnaires, yet commonly face item non-response. Traditional solutions use weighted mean (WMean) from available responses, but potentially overlook missing data intricacies. Advanced methods like multiple imputation (MI) address broader missing data, but demand increased computational resources. Researchers frequently use survey data in the All of Us Research Program (All of Us), and it is imperative to determine if the increased computational burden of employing MI to handle non-response is justifiable.</p><p><strong>Objectives: </strong>Using the 5-item Physical Activity Neighborhood Environment Scale (PANES) in All of Us, this study assessed the tradeoff between efficacy and computational demands of WMean, MI, and inverse probability weighting (IPW) when dealing with item non-response.</p><p><strong>Materials and methods: </strong>Synthetic missingness, allowing 1 or more item non-response, was introduced into PANES across 3 missing mechanisms and various missing percentages (10%-50%). Each scenario compared WMean of complete questions, MI, and IPW on bias, variability, coverage probability, and computation time.</p><p><strong>Results: </strong>All methods showed minimal biases (all <5.5%) for good internal consistency, with WMean suffered most with poor consistency. IPW showed considerable variability with increasing missing percentage. MI required significantly more computational resources, taking >8000 and >100 times longer than WMean and IPW in full data analysis, respectively.</p><p><strong>Discussion and conclusion: </strong>The marginal performance advantages of MI for item non-response in highly reliable scales do not warrant its escalated cloud computational burden in All of Us, particularly when coupled with computationally demanding post-imputation analyses. Researchers using survey scales with low missingness could utilize WMean to reduce computing burden.</p>\",\"PeriodicalId\":50016,\"journal\":{\"name\":\"Journal of the American Medical Informatics Association\",\"volume\":\" \",\"pages\":\"2869-2879\"},\"PeriodicalIF\":7.1000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11631082/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of the American Medical Informatics Association\",\"FirstCategoryId\":\"91\",\"ListUrlMain\":\"https://doi.org/10.1093/jamia/ocae217\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the American Medical Informatics Association","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1093/jamia/ocae217","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
摘要
重要性:量表通常由多项目问卷产生,但通常面临项目无响应的问题。传统的解决方案使用现有回答的加权平均值(WMean),但可能会忽略缺失数据的复杂性。多重估算(MI)等先进方法可以解决更广泛的缺失数据问题,但需要更多的计算资源。研究人员经常在 "我们所有人 "研究计划(All of Us)中使用调查数据,因此必须确定采用多重归因法处理非响应所增加的计算负担是否合理:本研究使用 All of Us 中的 5 项体育活动邻里环境量表 (PANES),评估了 WMean、MI 和反概率加权 (IPW) 在处理项目无响应时的功效和计算需求之间的权衡:在 PANES 中引入了 3 种缺失机制和不同缺失百分比(10%-50%)的合成缺失,允许 1 个或多个项目无响应。每种情况都比较了完整问题、MI 和 IPW 对偏差、变异性、覆盖概率和计算时间的影响:结果:所有方法都显示出最小偏差(在完整数据分析中分别比 WMean 和 IPW 长 8000 倍和 100 倍以上):在高可靠性量表中,MI 对项目无响应的性能优势微乎其微,但这并不能证明其在 "我们所有人 "中云计算负担的增加是值得的,尤其是在与计算要求极高的输入后分析相结合的情况下。使用低缺失率调查量表的研究人员可以利用 WMean 来减轻计算负担。
Balancing efficacy and computational burden: weighted mean, multiple imputation, and inverse probability weighting methods for item non-response in reliable scales.
Importance: Scales often arise from multi-item questionnaires, yet commonly face item non-response. Traditional solutions use weighted mean (WMean) from available responses, but potentially overlook missing data intricacies. Advanced methods like multiple imputation (MI) address broader missing data, but demand increased computational resources. Researchers frequently use survey data in the All of Us Research Program (All of Us), and it is imperative to determine if the increased computational burden of employing MI to handle non-response is justifiable.
Objectives: Using the 5-item Physical Activity Neighborhood Environment Scale (PANES) in All of Us, this study assessed the tradeoff between efficacy and computational demands of WMean, MI, and inverse probability weighting (IPW) when dealing with item non-response.
Materials and methods: Synthetic missingness, allowing 1 or more item non-response, was introduced into PANES across 3 missing mechanisms and various missing percentages (10%-50%). Each scenario compared WMean of complete questions, MI, and IPW on bias, variability, coverage probability, and computation time.
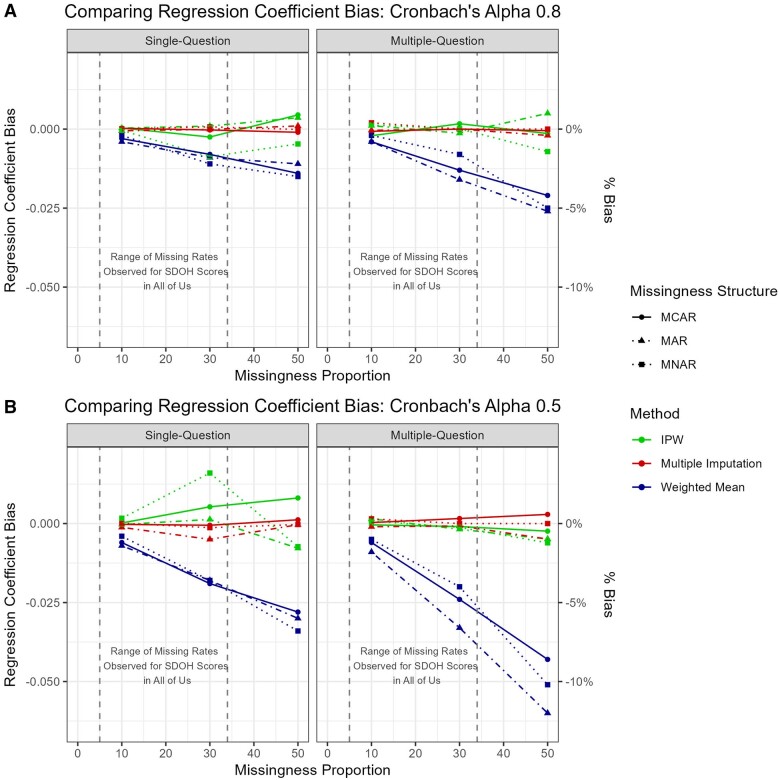
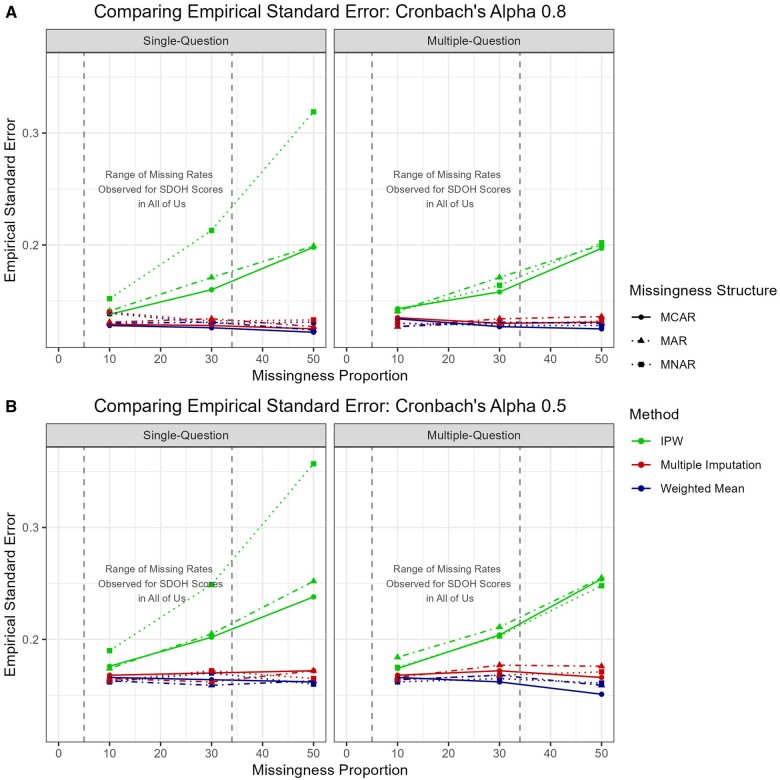
Results: All methods showed minimal biases (all <5.5%) for good internal consistency, with WMean suffered most with poor consistency. IPW showed considerable variability with increasing missing percentage. MI required significantly more computational resources, taking >8000 and >100 times longer than WMean and IPW in full data analysis, respectively.
Discussion and conclusion: The marginal performance advantages of MI for item non-response in highly reliable scales do not warrant its escalated cloud computational burden in All of Us, particularly when coupled with computationally demanding post-imputation analyses. Researchers using survey scales with low missingness could utilize WMean to reduce computing burden.
期刊介绍:
JAMIA is AMIA''s premier peer-reviewed journal for biomedical and health informatics. Covering the full spectrum of activities in the field, JAMIA includes informatics articles in the areas of clinical care, clinical research, translational science, implementation science, imaging, education, consumer health, public health, and policy. JAMIA''s articles describe innovative informatics research and systems that help to advance biomedical science and to promote health. Case reports, perspectives and reviews also help readers stay connected with the most important informatics developments in implementation, policy and education.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
