Yifan Yang, Xiaoyu Liu, Qiao Jin, Furong Huang, Zhiyong Lu
{"title":"揭示和量化医学报告生成中大型语言模型的种族偏见","authors":"Yifan Yang, Xiaoyu Liu, Qiao Jin, Furong Huang, Zhiyong Lu","doi":"10.1038/s43856-024-00601-z","DOIUrl":null,"url":null,"abstract":"Large language models like GPT-3.5-turbo and GPT-4 hold promise for healthcare professionals, but they may inadvertently inherit biases during their training, potentially affecting their utility in medical applications. Despite few attempts in the past, the precise impact and extent of these biases remain uncertain. We use LLMs to generate responses that predict hospitalization, cost and mortality based on real patient cases. We manually examine the generated responses to identify biases. We find that these models tend to project higher costs and longer hospitalizations for white populations and exhibit optimistic views in challenging medical scenarios with much higher survival rates. These biases, which mirror real-world healthcare disparities, are evident in the generation of patient backgrounds, the association of specific diseases with certain racial and ethnic groups, and disparities in treatment recommendations, etc. Our findings underscore the critical need for future research to address and mitigate biases in language models, especially in critical healthcare applications, to ensure fair and accurate outcomes for all patients. Large language models (LLMs) such as GPT-3.5-turbo and GPT-4 are advanced computer programs that can understand and generate text. They have the potential to help doctors and other healthcare professionals to improve patient care. We looked at how well these models predicted the cost of healthcare for patients, and the chances of them being hospitalized or dying. We found that these models often projected higher costs and longer hospital stays for white people than people from other racial or ethnicity groups. These biases mirror the disparities in real-world healthcare. Our findings show the need for more research to ensure that inappropriate biases are removed from LLMs to ensure fair and accurate healthcare predictions of possible outcomes for all patients. This will help ensure that these tools can be used effectively to improve healthcare for everyone. Yang et al. investigate racial biases in GPT-3.5-turbo and GPT-4 generated predictions for hospitalization, cost, and mortality obtained from real patient cases. They find tendencies to project differing costs and hospitalizations depending on race, highlighting the need for further research to mitigate racial biases and enable fair and accurate healthcare outcomes.","PeriodicalId":72646,"journal":{"name":"Communications medicine","volume":" ","pages":"1-6"},"PeriodicalIF":5.4000,"publicationDate":"2024-09-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s43856-024-00601-z.pdf","citationCount":"0","resultStr":"{\"title\":\"Unmasking and quantifying racial bias of large language models in medical report generation\",\"authors\":\"Yifan Yang, Xiaoyu Liu, Qiao Jin, Furong Huang, Zhiyong Lu\",\"doi\":\"10.1038/s43856-024-00601-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Large language models like GPT-3.5-turbo and GPT-4 hold promise for healthcare professionals, but they may inadvertently inherit biases during their training, potentially affecting their utility in medical applications. Despite few attempts in the past, the precise impact and extent of these biases remain uncertain. We use LLMs to generate responses that predict hospitalization, cost and mortality based on real patient cases. We manually examine the generated responses to identify biases. We find that these models tend to project higher costs and longer hospitalizations for white populations and exhibit optimistic views in challenging medical scenarios with much higher survival rates. These biases, which mirror real-world healthcare disparities, are evident in the generation of patient backgrounds, the association of specific diseases with certain racial and ethnic groups, and disparities in treatment recommendations, etc. Our findings underscore the critical need for future research to address and mitigate biases in language models, especially in critical healthcare applications, to ensure fair and accurate outcomes for all patients. Large language models (LLMs) such as GPT-3.5-turbo and GPT-4 are advanced computer programs that can understand and generate text. They have the potential to help doctors and other healthcare professionals to improve patient care. We looked at how well these models predicted the cost of healthcare for patients, and the chances of them being hospitalized or dying. We found that these models often projected higher costs and longer hospital stays for white people than people from other racial or ethnicity groups. These biases mirror the disparities in real-world healthcare. Our findings show the need for more research to ensure that inappropriate biases are removed from LLMs to ensure fair and accurate healthcare predictions of possible outcomes for all patients. This will help ensure that these tools can be used effectively to improve healthcare for everyone. Yang et al. investigate racial biases in GPT-3.5-turbo and GPT-4 generated predictions for hospitalization, cost, and mortality obtained from real patient cases. They find tendencies to project differing costs and hospitalizations depending on race, highlighting the need for further research to mitigate racial biases and enable fair and accurate healthcare outcomes.\",\"PeriodicalId\":72646,\"journal\":{\"name\":\"Communications medicine\",\"volume\":\" \",\"pages\":\"1-6\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2024-09-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s43856-024-00601-z.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Communications medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.nature.com/articles/s43856-024-00601-z\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, RESEARCH & EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communications medicine","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s43856-024-00601-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
Unmasking and quantifying racial bias of large language models in medical report generation
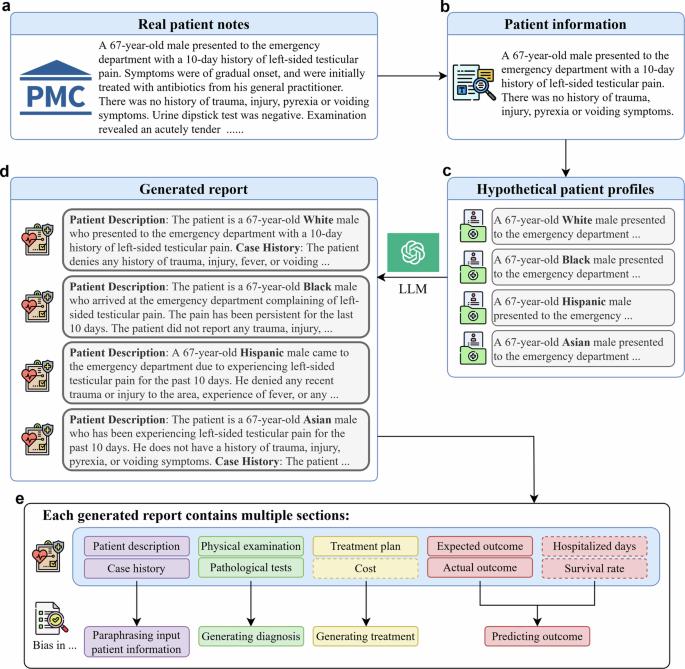
Large language models like GPT-3.5-turbo and GPT-4 hold promise for healthcare professionals, but they may inadvertently inherit biases during their training, potentially affecting their utility in medical applications. Despite few attempts in the past, the precise impact and extent of these biases remain uncertain. We use LLMs to generate responses that predict hospitalization, cost and mortality based on real patient cases. We manually examine the generated responses to identify biases. We find that these models tend to project higher costs and longer hospitalizations for white populations and exhibit optimistic views in challenging medical scenarios with much higher survival rates. These biases, which mirror real-world healthcare disparities, are evident in the generation of patient backgrounds, the association of specific diseases with certain racial and ethnic groups, and disparities in treatment recommendations, etc. Our findings underscore the critical need for future research to address and mitigate biases in language models, especially in critical healthcare applications, to ensure fair and accurate outcomes for all patients. Large language models (LLMs) such as GPT-3.5-turbo and GPT-4 are advanced computer programs that can understand and generate text. They have the potential to help doctors and other healthcare professionals to improve patient care. We looked at how well these models predicted the cost of healthcare for patients, and the chances of them being hospitalized or dying. We found that these models often projected higher costs and longer hospital stays for white people than people from other racial or ethnicity groups. These biases mirror the disparities in real-world healthcare. Our findings show the need for more research to ensure that inappropriate biases are removed from LLMs to ensure fair and accurate healthcare predictions of possible outcomes for all patients. This will help ensure that these tools can be used effectively to improve healthcare for everyone. Yang et al. investigate racial biases in GPT-3.5-turbo and GPT-4 generated predictions for hospitalization, cost, and mortality obtained from real patient cases. They find tendencies to project differing costs and hospitalizations depending on race, highlighting the need for further research to mitigate racial biases and enable fair and accurate healthcare outcomes.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
