{"title":"利用部分观测数据在高干扰环境中对机翼俯仰控制进行深度强化学习","authors":"Diederik Beckers, Jeff D. Eldredge","doi":"10.1103/physrevfluids.9.093902","DOIUrl":null,"url":null,"abstract":"This study explores the application of deep reinforcement learning (RL) to design an airfoil pitch controller capable of minimizing lift variations in randomly disturbed flows. The controller, treated as an agent in a partially observable Markov decision process, receives non-Markovian observations from the environment, simulating practical constraints where flow information is limited to force and pressure sensors. Deep RL, particularly the TD3 algorithm, is used to approximate an optimal control policy under such conditions. Testing is conducted for a flat plate airfoil in two environments: a classical unsteady environment with vertical acceleration disturbances (i.e., a Wagner setup) and a viscous flow model with pulsed point force disturbances. In both cases, augmenting observations of the lift, pitch angle, and angular velocity with extra wake information (e.g., from pressure sensors) and retaining memory of past observations enhances RL control performance. Results demonstrate the capability of RL control to match or exceed standard linear controllers in minimizing lift variations. Special attention is given to the choice of training data and the generalization to unseen disturbances.","PeriodicalId":20160,"journal":{"name":"Physical Review Fluids","volume":"1 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-09-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Deep reinforcement learning of airfoil pitch control in a highly disturbed environment using partial observations\",\"authors\":\"Diederik Beckers, Jeff D. Eldredge\",\"doi\":\"10.1103/physrevfluids.9.093902\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"This study explores the application of deep reinforcement learning (RL) to design an airfoil pitch controller capable of minimizing lift variations in randomly disturbed flows. The controller, treated as an agent in a partially observable Markov decision process, receives non-Markovian observations from the environment, simulating practical constraints where flow information is limited to force and pressure sensors. Deep RL, particularly the TD3 algorithm, is used to approximate an optimal control policy under such conditions. Testing is conducted for a flat plate airfoil in two environments: a classical unsteady environment with vertical acceleration disturbances (i.e., a Wagner setup) and a viscous flow model with pulsed point force disturbances. In both cases, augmenting observations of the lift, pitch angle, and angular velocity with extra wake information (e.g., from pressure sensors) and retaining memory of past observations enhances RL control performance. Results demonstrate the capability of RL control to match or exceed standard linear controllers in minimizing lift variations. Special attention is given to the choice of training data and the generalization to unseen disturbances.\",\"PeriodicalId\":20160,\"journal\":{\"name\":\"Physical Review Fluids\",\"volume\":\"1 1\",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-09-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Physical Review Fluids\",\"FirstCategoryId\":\"101\",\"ListUrlMain\":\"https://doi.org/10.1103/physrevfluids.9.093902\",\"RegionNum\":3,\"RegionCategory\":\"物理与天体物理\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PHYSICS, FLUIDS & PLASMAS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Physical Review Fluids","FirstCategoryId":"101","ListUrlMain":"https://doi.org/10.1103/physrevfluids.9.093902","RegionNum":3,"RegionCategory":"物理与天体物理","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PHYSICS, FLUIDS & PLASMAS","Score":null,"Total":0}
Deep reinforcement learning of airfoil pitch control in a highly disturbed environment using partial observations
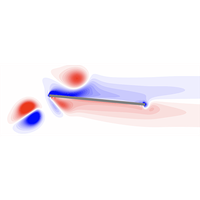
This study explores the application of deep reinforcement learning (RL) to design an airfoil pitch controller capable of minimizing lift variations in randomly disturbed flows. The controller, treated as an agent in a partially observable Markov decision process, receives non-Markovian observations from the environment, simulating practical constraints where flow information is limited to force and pressure sensors. Deep RL, particularly the TD3 algorithm, is used to approximate an optimal control policy under such conditions. Testing is conducted for a flat plate airfoil in two environments: a classical unsteady environment with vertical acceleration disturbances (i.e., a Wagner setup) and a viscous flow model with pulsed point force disturbances. In both cases, augmenting observations of the lift, pitch angle, and angular velocity with extra wake information (e.g., from pressure sensors) and retaining memory of past observations enhances RL control performance. Results demonstrate the capability of RL control to match or exceed standard linear controllers in minimizing lift variations. Special attention is given to the choice of training data and the generalization to unseen disturbances.
期刊介绍:
Physical Review Fluids is APS’s newest online-only journal dedicated to publishing innovative research that will significantly advance the fundamental understanding of fluid dynamics. Physical Review Fluids expands the scope of the APS journals to include additional areas of fluid dynamics research, complements the existing Physical Review collection, and maintains the same quality and reputation that authors and subscribers expect from APS. The journal is published with the endorsement of the APS Division of Fluid Dynamics.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
