Jouni Sirén, Parsa Eskandar, Matteo Tommaso Ungaro, Glenn Hickey, Jordan M. Eizenga, Adam M. Novak, Xian Chang, Pi-Chuan Chang, Mikhail Kolmogorov, Andrew Carroll, Jean Monlong, Benedict Paten
{"title":"个性化泛基因组参考文献","authors":"Jouni Sirén, Parsa Eskandar, Matteo Tommaso Ungaro, Glenn Hickey, Jordan M. Eizenga, Adam M. Novak, Xian Chang, Pi-Chuan Chang, Mikhail Kolmogorov, Andrew Carroll, Jean Monlong, Benedict Paten","doi":"10.1038/s41592-024-02407-2","DOIUrl":null,"url":null,"abstract":"<p>Pangenomes reduce reference bias by representing genetic diversity better than a single reference sequence. Yet when comparing a sample to a pangenome, variants in the pangenome that are not part of the sample can be misleading, for example, causing false read mappings. These irrelevant variants are generally rarer in terms of allele frequency, and have previously been dealt with by filtering rare variants. However, this blunt heuristic both fails to remove some irrelevant variants and removes many relevant variants. We propose a new approach that imputes a personalized pangenome subgraph by sampling local haplotypes according to <i>k</i>-mer counts in the reads. We implement the approach in the vg toolkit (https://github.com/vgteam/vg) for the Giraffe short-read aligner and compare its accuracy to state-of-the-art methods using human pangenome graphs from the Human Pangenome Reference Consortium. This reduces small variant genotyping errors by four times relative to the Genome Analysis Toolkit and makes short-read structural variant genotyping of known variants competitive with long-read variant discovery methods.</p>","PeriodicalId":18981,"journal":{"name":"Nature Methods","volume":null,"pages":null},"PeriodicalIF":36.1000,"publicationDate":"2024-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Personalized pangenome references\",\"authors\":\"Jouni Sirén, Parsa Eskandar, Matteo Tommaso Ungaro, Glenn Hickey, Jordan M. Eizenga, Adam M. Novak, Xian Chang, Pi-Chuan Chang, Mikhail Kolmogorov, Andrew Carroll, Jean Monlong, Benedict Paten\",\"doi\":\"10.1038/s41592-024-02407-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Pangenomes reduce reference bias by representing genetic diversity better than a single reference sequence. Yet when comparing a sample to a pangenome, variants in the pangenome that are not part of the sample can be misleading, for example, causing false read mappings. These irrelevant variants are generally rarer in terms of allele frequency, and have previously been dealt with by filtering rare variants. However, this blunt heuristic both fails to remove some irrelevant variants and removes many relevant variants. We propose a new approach that imputes a personalized pangenome subgraph by sampling local haplotypes according to <i>k</i>-mer counts in the reads. We implement the approach in the vg toolkit (https://github.com/vgteam/vg) for the Giraffe short-read aligner and compare its accuracy to state-of-the-art methods using human pangenome graphs from the Human Pangenome Reference Consortium. This reduces small variant genotyping errors by four times relative to the Genome Analysis Toolkit and makes short-read structural variant genotyping of known variants competitive with long-read variant discovery methods.</p>\",\"PeriodicalId\":18981,\"journal\":{\"name\":\"Nature Methods\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":36.1000,\"publicationDate\":\"2024-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Methods\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1038/s41592-024-02407-2\",\"RegionNum\":1,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Methods","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1038/s41592-024-02407-2","RegionNum":1,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
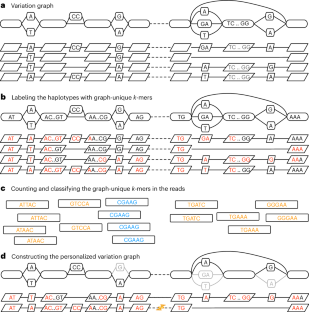
Pangenomes reduce reference bias by representing genetic diversity better than a single reference sequence. Yet when comparing a sample to a pangenome, variants in the pangenome that are not part of the sample can be misleading, for example, causing false read mappings. These irrelevant variants are generally rarer in terms of allele frequency, and have previously been dealt with by filtering rare variants. However, this blunt heuristic both fails to remove some irrelevant variants and removes many relevant variants. We propose a new approach that imputes a personalized pangenome subgraph by sampling local haplotypes according to k-mer counts in the reads. We implement the approach in the vg toolkit (https://github.com/vgteam/vg) for the Giraffe short-read aligner and compare its accuracy to state-of-the-art methods using human pangenome graphs from the Human Pangenome Reference Consortium. This reduces small variant genotyping errors by four times relative to the Genome Analysis Toolkit and makes short-read structural variant genotyping of known variants competitive with long-read variant discovery methods.
期刊介绍:
Nature Methods is a monthly journal that focuses on publishing innovative methods and substantial enhancements to fundamental life sciences research techniques. Geared towards a diverse, interdisciplinary readership of researchers in academia and industry engaged in laboratory work, the journal offers new tools for research and emphasizes the immediate practical significance of the featured work. It publishes primary research papers and reviews recent technical and methodological advancements, with a particular interest in primary methods papers relevant to the biological and biomedical sciences. This includes methods rooted in chemistry with practical applications for studying biological problems.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
