{"title":"综合分析确定胰腺癌表观遗传生物标志物。","authors":"Panchami V.U. , Manish T.I. , Manesh K.K.","doi":"10.1016/j.compbiolchem.2024.108260","DOIUrl":null,"url":null,"abstract":"<div><div>Integrating and analyzing the pancancer data collected from different experiments is crucial for gaining insights into the common mechanisms in the molecular level underlying the development and progression of cancers. Epigenetic study of the pancancer data can provide promising results in biomarker discovery. The genes that are epigenetically dysregulated in different cancers are powerful biomarkers for drug-related studies. This paper identifies the genes having altered expression due to aberrant methylation patterns using differential analysis of TCGA pancancer data of 12 different cancers. We identified a comprehensive set of 115 epigenetic biomarker genes out of which 106 genes having pancancer properties. The correlation analysis, gene set enrichment, protein–protein interaction analysis, pancancer characteristics analysis, and diagnostic modeling were performed on these biomarkers to illustrate the power of this signature and found to be important in different molecular operations related to cancer. An accuracy of 97.56% was obtained on TCGA pancancer gene expression dataset for predicting the binary class tumor or normal. The source code and dataset of this work are available at <span><span>https://github.com/panchamisuneeth/EpiPanCan.git</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":10616,"journal":{"name":"Computational Biology and Chemistry","volume":"113 ","pages":"Article 108260"},"PeriodicalIF":3.1000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"An integrative analysis to identify pancancer epigenetic biomarkers\",\"authors\":\"Panchami V.U. , Manish T.I. , Manesh K.K.\",\"doi\":\"10.1016/j.compbiolchem.2024.108260\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Integrating and analyzing the pancancer data collected from different experiments is crucial for gaining insights into the common mechanisms in the molecular level underlying the development and progression of cancers. Epigenetic study of the pancancer data can provide promising results in biomarker discovery. The genes that are epigenetically dysregulated in different cancers are powerful biomarkers for drug-related studies. This paper identifies the genes having altered expression due to aberrant methylation patterns using differential analysis of TCGA pancancer data of 12 different cancers. We identified a comprehensive set of 115 epigenetic biomarker genes out of which 106 genes having pancancer properties. The correlation analysis, gene set enrichment, protein–protein interaction analysis, pancancer characteristics analysis, and diagnostic modeling were performed on these biomarkers to illustrate the power of this signature and found to be important in different molecular operations related to cancer. An accuracy of 97.56% was obtained on TCGA pancancer gene expression dataset for predicting the binary class tumor or normal. The source code and dataset of this work are available at <span><span>https://github.com/panchamisuneeth/EpiPanCan.git</span><svg><path></path></svg></span>.</div></div>\",\"PeriodicalId\":10616,\"journal\":{\"name\":\"Computational Biology and Chemistry\",\"volume\":\"113 \",\"pages\":\"Article 108260\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Biology and Chemistry\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1476927124002482\",\"RegionNum\":4,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/23 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Biology and Chemistry","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1476927124002482","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/23 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"BIOLOGY","Score":null,"Total":0}
An integrative analysis to identify pancancer epigenetic biomarkers
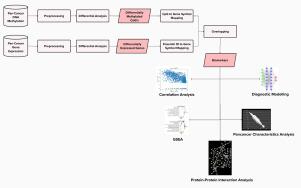
Integrating and analyzing the pancancer data collected from different experiments is crucial for gaining insights into the common mechanisms in the molecular level underlying the development and progression of cancers. Epigenetic study of the pancancer data can provide promising results in biomarker discovery. The genes that are epigenetically dysregulated in different cancers are powerful biomarkers for drug-related studies. This paper identifies the genes having altered expression due to aberrant methylation patterns using differential analysis of TCGA pancancer data of 12 different cancers. We identified a comprehensive set of 115 epigenetic biomarker genes out of which 106 genes having pancancer properties. The correlation analysis, gene set enrichment, protein–protein interaction analysis, pancancer characteristics analysis, and diagnostic modeling were performed on these biomarkers to illustrate the power of this signature and found to be important in different molecular operations related to cancer. An accuracy of 97.56% was obtained on TCGA pancancer gene expression dataset for predicting the binary class tumor or normal. The source code and dataset of this work are available at https://github.com/panchamisuneeth/EpiPanCan.git.
期刊介绍:
Computational Biology and Chemistry publishes original research papers and review articles in all areas of computational life sciences. High quality research contributions with a major computational component in the areas of nucleic acid and protein sequence research, molecular evolution, molecular genetics (functional genomics and proteomics), theory and practice of either biology-specific or chemical-biology-specific modeling, and structural biology of nucleic acids and proteins are particularly welcome. Exceptionally high quality research work in bioinformatics, systems biology, ecology, computational pharmacology, metabolism, biomedical engineering, epidemiology, and statistical genetics will also be considered.
Given their inherent uncertainty, protein modeling and molecular docking studies should be thoroughly validated. In the absence of experimental results for validation, the use of molecular dynamics simulations along with detailed free energy calculations, for example, should be used as complementary techniques to support the major conclusions. Submissions of premature modeling exercises without additional biological insights will not be considered.
Review articles will generally be commissioned by the editors and should not be submitted to the journal without explicit invitation. However prospective authors are welcome to send a brief (one to three pages) synopsis, which will be evaluated by the editors.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
