{"title":"词向量嵌入和自补充网络用于广义少镜头语义分割","authors":"Xiaowei Wang, Qiong Chen, Yong Yang","doi":"10.1016/j.neucom.2024.128737","DOIUrl":null,"url":null,"abstract":"<div><div>Under the condition of sufficient base class samples and a few novel class samples, Generalized Few-shot Semantic Segmentation (GFSS) classifies each pixel in the query image as base class, novel class, or background. A standard GFSS approach involves two training stages: base class learning and novel class updating. However, inter-class interference and information loss which contribute to the poor performance of GFSS, have not been synthetical considered. To address the problem, we propose an Embedded-Self-Supplementing Network (ESSNet), i.e., semantic word embedding and query set self-supplementing information to enhance segmentation accuracy. Specifically, the semantic word embedding module employs distance information between word vectors to assist the model in learning the distance between class prototypes. In order to transform the semantic word vector prototypes from the semantic space to the visual embedding space, we designed a triplet loss function to supervise the word vector embedding module, where the word vector prototype serves as an anchor and positive-negative samples are collected among the general features of the support image. To compensate for the information loss caused by using prototypes to represent classes, we propose a self-supplementing module to mine the information contained in the query image. Specifically, this module first makes a preliminary prediction on the query image, then selects high-confidence area to form pseudo labels, and finally uses pseudo labels to extract query prototypes to supplement the missing information. Extensive experiments on PASCAL-5<span><math><msup><mrow></mrow><mrow><mi>i</mi></mrow></msup></math></span> and COCO-20<span><math><msup><mrow></mrow><mrow><mi>i</mi></mrow></msup></math></span> show that ESSNet has superior performance and outperforms state-of-the-art methods in all settings.</div></div>","PeriodicalId":19268,"journal":{"name":"Neurocomputing","volume":"613 ","pages":"Article 128737"},"PeriodicalIF":6.5000,"publicationDate":"2025-01-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Word vector embedding and self-supplementing network for Generalized Few-shot Semantic Segmentation\",\"authors\":\"Xiaowei Wang, Qiong Chen, Yong Yang\",\"doi\":\"10.1016/j.neucom.2024.128737\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Under the condition of sufficient base class samples and a few novel class samples, Generalized Few-shot Semantic Segmentation (GFSS) classifies each pixel in the query image as base class, novel class, or background. A standard GFSS approach involves two training stages: base class learning and novel class updating. However, inter-class interference and information loss which contribute to the poor performance of GFSS, have not been synthetical considered. To address the problem, we propose an Embedded-Self-Supplementing Network (ESSNet), i.e., semantic word embedding and query set self-supplementing information to enhance segmentation accuracy. Specifically, the semantic word embedding module employs distance information between word vectors to assist the model in learning the distance between class prototypes. In order to transform the semantic word vector prototypes from the semantic space to the visual embedding space, we designed a triplet loss function to supervise the word vector embedding module, where the word vector prototype serves as an anchor and positive-negative samples are collected among the general features of the support image. To compensate for the information loss caused by using prototypes to represent classes, we propose a self-supplementing module to mine the information contained in the query image. Specifically, this module first makes a preliminary prediction on the query image, then selects high-confidence area to form pseudo labels, and finally uses pseudo labels to extract query prototypes to supplement the missing information. Extensive experiments on PASCAL-5<span><math><msup><mrow></mrow><mrow><mi>i</mi></mrow></msup></math></span> and COCO-20<span><math><msup><mrow></mrow><mrow><mi>i</mi></mrow></msup></math></span> show that ESSNet has superior performance and outperforms state-of-the-art methods in all settings.</div></div>\",\"PeriodicalId\":19268,\"journal\":{\"name\":\"Neurocomputing\",\"volume\":\"613 \",\"pages\":\"Article 128737\"},\"PeriodicalIF\":6.5000,\"publicationDate\":\"2025-01-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neurocomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S092523122401508X\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/21 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neurocomputing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S092523122401508X","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/21 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Word vector embedding and self-supplementing network for Generalized Few-shot Semantic Segmentation
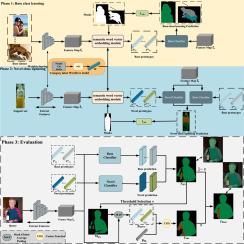
Under the condition of sufficient base class samples and a few novel class samples, Generalized Few-shot Semantic Segmentation (GFSS) classifies each pixel in the query image as base class, novel class, or background. A standard GFSS approach involves two training stages: base class learning and novel class updating. However, inter-class interference and information loss which contribute to the poor performance of GFSS, have not been synthetical considered. To address the problem, we propose an Embedded-Self-Supplementing Network (ESSNet), i.e., semantic word embedding and query set self-supplementing information to enhance segmentation accuracy. Specifically, the semantic word embedding module employs distance information between word vectors to assist the model in learning the distance between class prototypes. In order to transform the semantic word vector prototypes from the semantic space to the visual embedding space, we designed a triplet loss function to supervise the word vector embedding module, where the word vector prototype serves as an anchor and positive-negative samples are collected among the general features of the support image. To compensate for the information loss caused by using prototypes to represent classes, we propose a self-supplementing module to mine the information contained in the query image. Specifically, this module first makes a preliminary prediction on the query image, then selects high-confidence area to form pseudo labels, and finally uses pseudo labels to extract query prototypes to supplement the missing information. Extensive experiments on PASCAL-5 and COCO-20 show that ESSNet has superior performance and outperforms state-of-the-art methods in all settings.
期刊介绍:
Neurocomputing publishes articles describing recent fundamental contributions in the field of neurocomputing. Neurocomputing theory, practice and applications are the essential topics being covered.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
