Stephen Fahy, Stephan Oehme, Danko Dan Milinkovic, Benjamin Bartek
{"title":"使用定制ChatGPT加强患者对胫骨截骨术在膝关节骨性关节炎治疗中的作用的教育:可读性和质量评估。","authors":"Stephen Fahy, Stephan Oehme, Danko Dan Milinkovic, Benjamin Bartek","doi":"10.3389/fdgth.2024.1480381","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Knee osteoarthritis (OA) significantly impacts the quality of life of those afflicted, with many patients eventually requiring surgical intervention. While Total Knee Arthroplasty (TKA) is common, it may not be suitable for younger patients with unicompartmental OA, who might benefit more from High Tibial Osteotomy (HTO). Effective patient education is crucial for informed decision-making, yet most online health information has been found to be too complex for the average patient to understand. AI tools like ChatGPT may offer a solution, but their outputs often exceed the public's literacy level. This study assessed whether a customised ChatGPT could be utilized to improve readability and source accuracy in patient education on Knee OA and tibial osteotomy.</p><p><strong>Methods: </strong>Commonly asked questions about HTO were gathered using Google's \"People Also Asked\" feature and formatted to an 8th-grade reading level. Two ChatGPT-4 models were compared: a native version and a fine-tuned model (\"The Knee Guide\") optimized for readability and source citation through Instruction-Based Fine-Tuning (IBFT) and Reinforcement Learning from Human Feedback (RLHF). The responses were evaluated for quality using the DISCERN criteria and readability using the Flesch Reading Ease Score (FRES) and Flesch-Kincaid Grade Level (FKGL).</p><p><strong>Results: </strong>The native ChatGPT-4 model scored a mean DISCERN score of 38.41 (range 25-46), indicating poor quality, while \"The Knee Guide\" scored 45.9 (range 33-66), indicating moderate quality. Cronbach's Alpha was 0.86, indicating good interrater reliability. \"The Knee Guide\" achieved better readability with a mean FKGL of 8.2 (range 5-10.7, ±1.42) and a mean FRES of 60 (range 47-76, ±7.83), compared to the native model's FKGL of 13.9 (range 11-16, ±1.39) and FRES of 32 (range 14-47, ±8.3). These differences were statistically significant (<i>p</i> < 0.001).</p><p><strong>Conclusions: </strong>Fine-tuning ChatGPT significantly improved the readability and quality of HTO-related information. \"The Knee Guide\" demonstrated the potential of customized AI tools in enhancing patient education by making complex medical information more accessible and understandable.</p>","PeriodicalId":73078,"journal":{"name":"Frontiers in digital health","volume":"6 ","pages":"1480381"},"PeriodicalIF":3.2000,"publicationDate":"2025-01-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11738919/pdf/","citationCount":"0","resultStr":"{\"title\":\"Enhancing patient education on the role of tibial osteotomy in the management of knee osteoarthritis using a customized ChatGPT: a readability and quality assessment.\",\"authors\":\"Stephen Fahy, Stephan Oehme, Danko Dan Milinkovic, Benjamin Bartek\",\"doi\":\"10.3389/fdgth.2024.1480381\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Knee osteoarthritis (OA) significantly impacts the quality of life of those afflicted, with many patients eventually requiring surgical intervention. While Total Knee Arthroplasty (TKA) is common, it may not be suitable for younger patients with unicompartmental OA, who might benefit more from High Tibial Osteotomy (HTO). Effective patient education is crucial for informed decision-making, yet most online health information has been found to be too complex for the average patient to understand. AI tools like ChatGPT may offer a solution, but their outputs often exceed the public's literacy level. This study assessed whether a customised ChatGPT could be utilized to improve readability and source accuracy in patient education on Knee OA and tibial osteotomy.</p><p><strong>Methods: </strong>Commonly asked questions about HTO were gathered using Google's \\\"People Also Asked\\\" feature and formatted to an 8th-grade reading level. Two ChatGPT-4 models were compared: a native version and a fine-tuned model (\\\"The Knee Guide\\\") optimized for readability and source citation through Instruction-Based Fine-Tuning (IBFT) and Reinforcement Learning from Human Feedback (RLHF). The responses were evaluated for quality using the DISCERN criteria and readability using the Flesch Reading Ease Score (FRES) and Flesch-Kincaid Grade Level (FKGL).</p><p><strong>Results: </strong>The native ChatGPT-4 model scored a mean DISCERN score of 38.41 (range 25-46), indicating poor quality, while \\\"The Knee Guide\\\" scored 45.9 (range 33-66), indicating moderate quality. Cronbach's Alpha was 0.86, indicating good interrater reliability. \\\"The Knee Guide\\\" achieved better readability with a mean FKGL of 8.2 (range 5-10.7, ±1.42) and a mean FRES of 60 (range 47-76, ±7.83), compared to the native model's FKGL of 13.9 (range 11-16, ±1.39) and FRES of 32 (range 14-47, ±8.3). These differences were statistically significant (<i>p</i> < 0.001).</p><p><strong>Conclusions: </strong>Fine-tuning ChatGPT significantly improved the readability and quality of HTO-related information. \\\"The Knee Guide\\\" demonstrated the potential of customized AI tools in enhancing patient education by making complex medical information more accessible and understandable.</p>\",\"PeriodicalId\":73078,\"journal\":{\"name\":\"Frontiers in digital health\",\"volume\":\"6 \",\"pages\":\"1480381\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2025-01-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11738919/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fdgth.2024.1480381\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdgth.2024.1480381","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Enhancing patient education on the role of tibial osteotomy in the management of knee osteoarthritis using a customized ChatGPT: a readability and quality assessment.
Introduction: Knee osteoarthritis (OA) significantly impacts the quality of life of those afflicted, with many patients eventually requiring surgical intervention. While Total Knee Arthroplasty (TKA) is common, it may not be suitable for younger patients with unicompartmental OA, who might benefit more from High Tibial Osteotomy (HTO). Effective patient education is crucial for informed decision-making, yet most online health information has been found to be too complex for the average patient to understand. AI tools like ChatGPT may offer a solution, but their outputs often exceed the public's literacy level. This study assessed whether a customised ChatGPT could be utilized to improve readability and source accuracy in patient education on Knee OA and tibial osteotomy.
Methods: Commonly asked questions about HTO were gathered using Google's "People Also Asked" feature and formatted to an 8th-grade reading level. Two ChatGPT-4 models were compared: a native version and a fine-tuned model ("The Knee Guide") optimized for readability and source citation through Instruction-Based Fine-Tuning (IBFT) and Reinforcement Learning from Human Feedback (RLHF). The responses were evaluated for quality using the DISCERN criteria and readability using the Flesch Reading Ease Score (FRES) and Flesch-Kincaid Grade Level (FKGL).
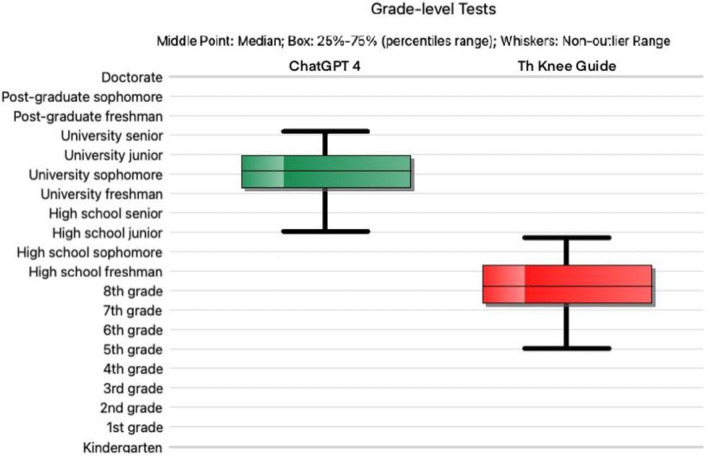
Results: The native ChatGPT-4 model scored a mean DISCERN score of 38.41 (range 25-46), indicating poor quality, while "The Knee Guide" scored 45.9 (range 33-66), indicating moderate quality. Cronbach's Alpha was 0.86, indicating good interrater reliability. "The Knee Guide" achieved better readability with a mean FKGL of 8.2 (range 5-10.7, ±1.42) and a mean FRES of 60 (range 47-76, ±7.83), compared to the native model's FKGL of 13.9 (range 11-16, ±1.39) and FRES of 32 (range 14-47, ±8.3). These differences were statistically significant (p < 0.001).
Conclusions: Fine-tuning ChatGPT significantly improved the readability and quality of HTO-related information. "The Knee Guide" demonstrated the potential of customized AI tools in enhancing patient education by making complex medical information more accessible and understandable.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
