Zengjie Wang, Wen Luo, Linwang Yuan, Hong Gao, Fan Wu, Xu Hu, Zhaoyuan Yu
{"title":"基于精确轨迹查询轨迹:基于Bloom过滤器的方法。","authors":"Zengjie Wang, Wen Luo, Linwang Yuan, Hong Gao, Fan Wu, Xu Hu, Zhaoyuan Yu","doi":"10.1007/s10707-021-00433-2","DOIUrl":null,"url":null,"abstract":"<p><p>Fast and precise querying in a given set of trajectory points is an important issue of trajectory query. Typically, there are massive trajectory data in the database, yet the query sets only have a few points, which is a challenge for the superior performance of trajectory querying. The current trajectory query methods commonly use the tree-based index structure and the signature-based method to classify, simplify, and filter the trajectory to improve the performance. However, the unstructured essence and the spatiotemporal heterogeneity of the trajectory-sequence lead these methods to a high degree of spatial overlap, frequent I/O, and high memory occupation. Thus, they are not suitable for the time-critical tasks of trajectory big data. In this paper, a query method of trajectory is developed on the Bloom Filter. Based on the gridded space and geocoding, the spatial trajectory sequences (tracks) query is transformed into the query of the text string. The geospace was regularly divided by the geographic grid, and each cell was assigned an independent geocode, converting the high-dimensional irregular space trajectory query into a one-dimensional string query. The point in each cell is regarded as a signature, which forms a mapping to the bit-array of the Bloom Filter. This conversion effectively eliminates the high degree of overlap and instability of query performance. Meanwhile, the independent coding ensures the uniqueness of the whole tracks. In this method, there is no need for additional I/O on the raw trajectory data when the track is queried. Compared to the original data, the memory occupied by this method is negligible. Based on Beijing Taxi and Shenzhen bus trajectory data, an experiment using this method was constructed, and random queries under a variety of conditions boundaries were constructed. The results verified that the performance and stability of our method, compared to R*tree index, have been improved by 2000 to 4000 times, based on one million to tens of millions of trajectory data. And the Bloom Filter-based query method is hardly affected by grid size, original data size, and length of tracks. With such a time advantage, our method is suitable for time-critical spatial computation tasks, such as anti-terrorism, public safety, epidemic prevention, and control, etc.</p>","PeriodicalId":55109,"journal":{"name":"Geoinformatica","volume":"25 2","pages":"397-416"},"PeriodicalIF":2.5000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1007/s10707-021-00433-2","citationCount":"1","resultStr":"{\"title\":\"Query the trajectory based on the precise track: a Bloom filter-based approach.\",\"authors\":\"Zengjie Wang, Wen Luo, Linwang Yuan, Hong Gao, Fan Wu, Xu Hu, Zhaoyuan Yu\",\"doi\":\"10.1007/s10707-021-00433-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Fast and precise querying in a given set of trajectory points is an important issue of trajectory query. Typically, there are massive trajectory data in the database, yet the query sets only have a few points, which is a challenge for the superior performance of trajectory querying. The current trajectory query methods commonly use the tree-based index structure and the signature-based method to classify, simplify, and filter the trajectory to improve the performance. However, the unstructured essence and the spatiotemporal heterogeneity of the trajectory-sequence lead these methods to a high degree of spatial overlap, frequent I/O, and high memory occupation. Thus, they are not suitable for the time-critical tasks of trajectory big data. In this paper, a query method of trajectory is developed on the Bloom Filter. Based on the gridded space and geocoding, the spatial trajectory sequences (tracks) query is transformed into the query of the text string. The geospace was regularly divided by the geographic grid, and each cell was assigned an independent geocode, converting the high-dimensional irregular space trajectory query into a one-dimensional string query. The point in each cell is regarded as a signature, which forms a mapping to the bit-array of the Bloom Filter. This conversion effectively eliminates the high degree of overlap and instability of query performance. Meanwhile, the independent coding ensures the uniqueness of the whole tracks. In this method, there is no need for additional I/O on the raw trajectory data when the track is queried. Compared to the original data, the memory occupied by this method is negligible. Based on Beijing Taxi and Shenzhen bus trajectory data, an experiment using this method was constructed, and random queries under a variety of conditions boundaries were constructed. The results verified that the performance and stability of our method, compared to R*tree index, have been improved by 2000 to 4000 times, based on one million to tens of millions of trajectory data. And the Bloom Filter-based query method is hardly affected by grid size, original data size, and length of tracks. With such a time advantage, our method is suitable for time-critical spatial computation tasks, such as anti-terrorism, public safety, epidemic prevention, and control, etc.</p>\",\"PeriodicalId\":55109,\"journal\":{\"name\":\"Geoinformatica\",\"volume\":\"25 2\",\"pages\":\"397-416\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2021-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1007/s10707-021-00433-2\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Geoinformatica\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10707-021-00433-2\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2021/3/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Geoinformatica","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10707-021-00433-2","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/3/15 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Query the trajectory based on the precise track: a Bloom filter-based approach.
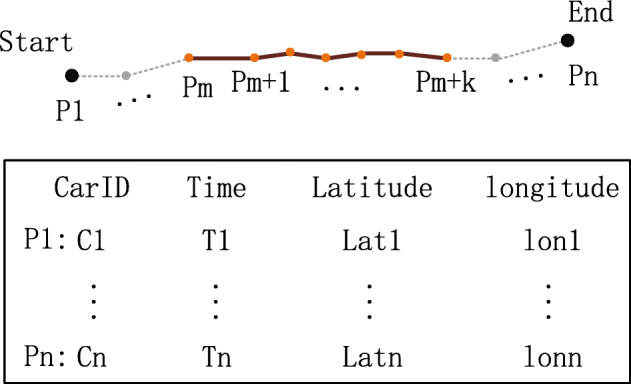
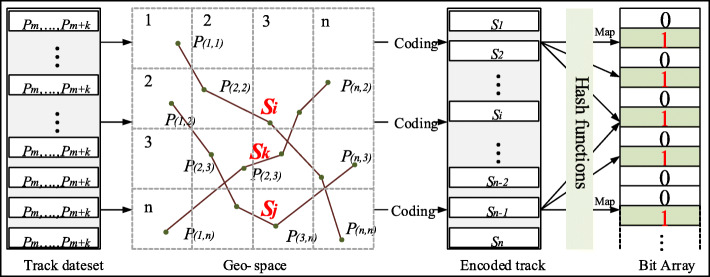
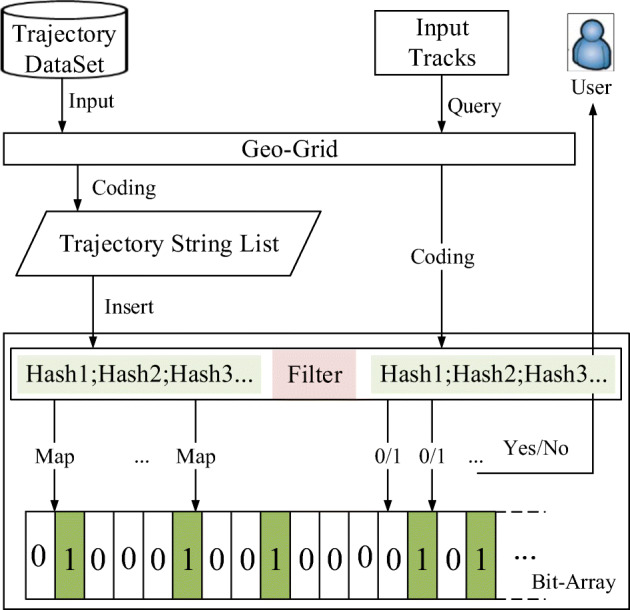
Fast and precise querying in a given set of trajectory points is an important issue of trajectory query. Typically, there are massive trajectory data in the database, yet the query sets only have a few points, which is a challenge for the superior performance of trajectory querying. The current trajectory query methods commonly use the tree-based index structure and the signature-based method to classify, simplify, and filter the trajectory to improve the performance. However, the unstructured essence and the spatiotemporal heterogeneity of the trajectory-sequence lead these methods to a high degree of spatial overlap, frequent I/O, and high memory occupation. Thus, they are not suitable for the time-critical tasks of trajectory big data. In this paper, a query method of trajectory is developed on the Bloom Filter. Based on the gridded space and geocoding, the spatial trajectory sequences (tracks) query is transformed into the query of the text string. The geospace was regularly divided by the geographic grid, and each cell was assigned an independent geocode, converting the high-dimensional irregular space trajectory query into a one-dimensional string query. The point in each cell is regarded as a signature, which forms a mapping to the bit-array of the Bloom Filter. This conversion effectively eliminates the high degree of overlap and instability of query performance. Meanwhile, the independent coding ensures the uniqueness of the whole tracks. In this method, there is no need for additional I/O on the raw trajectory data when the track is queried. Compared to the original data, the memory occupied by this method is negligible. Based on Beijing Taxi and Shenzhen bus trajectory data, an experiment using this method was constructed, and random queries under a variety of conditions boundaries were constructed. The results verified that the performance and stability of our method, compared to R*tree index, have been improved by 2000 to 4000 times, based on one million to tens of millions of trajectory data. And the Bloom Filter-based query method is hardly affected by grid size, original data size, and length of tracks. With such a time advantage, our method is suitable for time-critical spatial computation tasks, such as anti-terrorism, public safety, epidemic prevention, and control, etc.
期刊介绍:
GeoInformatica is located at the confluence of two rapidly advancing domains: Computer Science and Geographic Information Science; nowadays, Earth studies use more and more sophisticated computing theory and tools, and computer processing of Earth observations through Geographic Information Systems (GIS) attracts a great deal of attention from governmental, industrial and research worlds.
This journal aims to promote the most innovative results coming from the research in the field of computer science applied to geographic information systems. Thus, GeoInformatica provides an effective forum for disseminating original and fundamental research and experience in the rapidly advancing area of the use of computer science for spatial studies.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
