{"title":"未选择选项的贬值:对过度乐观预期的起源和维持的贝叶斯解释。","authors":"Corey Yishan Zhou, Dalin Guo, Angela J Yu","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Humans frequently overestimate the likelihood of desirable events while underestimating the likelihood of undesirable ones: a phenomenon known as <i>unrealistic optimism</i>. Previously, it was suggested that unrealistic optimism arises from asymmetric belief updating, with a relatively reduced coding of undesirable information. Prior studies have shown that a reinforcement learning (RL) model with asymmetric learning rates (greater for a positive prediction error than a negative prediction error) could account for unrealistic optimism in a bandit task, in particular the tendency of human subjects to persistently choosing a single option when there are multiple equally good options. Here, we propose an alternative explanation of such persistent behavior, by modeling human behavior using a Bayesian hidden Markov model, the Dynamic Belief Model (DBM). We find that DBM captures human choice behavior better than the previously proposed asymmetric RL model. Whereas asymmetric RL attains a measure of optimism by giving better-than-expected outcomes higher learning weights compared to worse-than-expected outcomes, DBM does so by progressively devaluing the unchosen options, thus placing a greater emphasis on <i>choice history</i> independent of reward outcome (e.g. an oft-chosen option might continue to be preferred even if it has not been particularly rewarding), which has broadly been shown to underlie sequential effects in a variety of behavioral settings. Moreover, previous work showed that the devaluation of unchosen options in DBM helps to compensate for a default assumption of environmental non-stationarity, thus allowing the decision-maker to both be more adaptive in changing environments and still obtain near-optimal performance in stationary environments. Thus, the current work suggests both a novel rationale and mechanism for persistent behavior in bandit tasks.</p>","PeriodicalId":72634,"journal":{"name":"CogSci ... Annual Conference of the Cognitive Science Society. Cognitive Science Society (U.S.). Conference","volume":"42 ","pages":"1682-1688"},"PeriodicalIF":0.0000,"publicationDate":"2020-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8336429/pdf/","citationCount":"0","resultStr":"{\"title\":\"Devaluation of Unchosen Options: A Bayesian Account of the Provenance and Maintenance of Overly Optimistic Expectations.\",\"authors\":\"Corey Yishan Zhou, Dalin Guo, Angela J Yu\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Humans frequently overestimate the likelihood of desirable events while underestimating the likelihood of undesirable ones: a phenomenon known as <i>unrealistic optimism</i>. Previously, it was suggested that unrealistic optimism arises from asymmetric belief updating, with a relatively reduced coding of undesirable information. Prior studies have shown that a reinforcement learning (RL) model with asymmetric learning rates (greater for a positive prediction error than a negative prediction error) could account for unrealistic optimism in a bandit task, in particular the tendency of human subjects to persistently choosing a single option when there are multiple equally good options. Here, we propose an alternative explanation of such persistent behavior, by modeling human behavior using a Bayesian hidden Markov model, the Dynamic Belief Model (DBM). We find that DBM captures human choice behavior better than the previously proposed asymmetric RL model. Whereas asymmetric RL attains a measure of optimism by giving better-than-expected outcomes higher learning weights compared to worse-than-expected outcomes, DBM does so by progressively devaluing the unchosen options, thus placing a greater emphasis on <i>choice history</i> independent of reward outcome (e.g. an oft-chosen option might continue to be preferred even if it has not been particularly rewarding), which has broadly been shown to underlie sequential effects in a variety of behavioral settings. Moreover, previous work showed that the devaluation of unchosen options in DBM helps to compensate for a default assumption of environmental non-stationarity, thus allowing the decision-maker to both be more adaptive in changing environments and still obtain near-optimal performance in stationary environments. Thus, the current work suggests both a novel rationale and mechanism for persistent behavior in bandit tasks.</p>\",\"PeriodicalId\":72634,\"journal\":{\"name\":\"CogSci ... Annual Conference of the Cognitive Science Society. Cognitive Science Society (U.S.). Conference\",\"volume\":\"42 \",\"pages\":\"1682-1688\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2020-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8336429/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"CogSci ... Annual Conference of the Cognitive Science Society. Cognitive Science Society (U.S.). Conference\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"CogSci ... Annual Conference of the Cognitive Science Society. Cognitive Science Society (U.S.). Conference","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Devaluation of Unchosen Options: A Bayesian Account of the Provenance and Maintenance of Overly Optimistic Expectations.
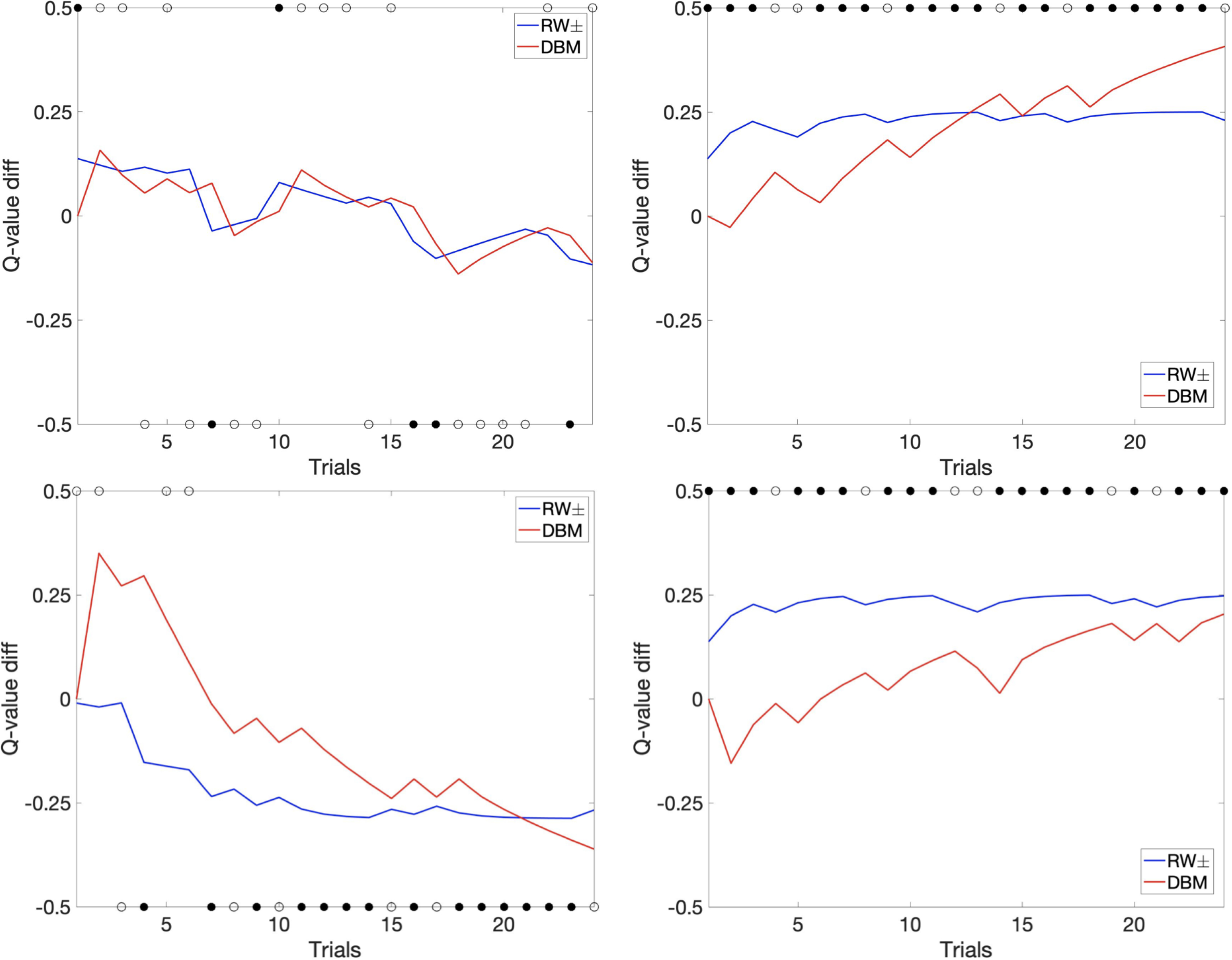
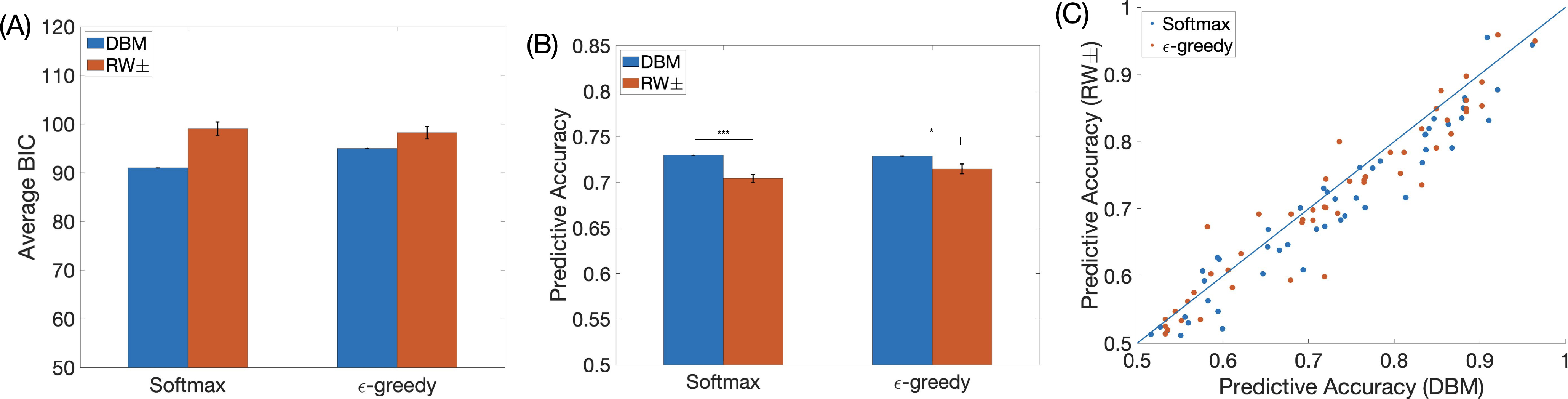
Humans frequently overestimate the likelihood of desirable events while underestimating the likelihood of undesirable ones: a phenomenon known as unrealistic optimism. Previously, it was suggested that unrealistic optimism arises from asymmetric belief updating, with a relatively reduced coding of undesirable information. Prior studies have shown that a reinforcement learning (RL) model with asymmetric learning rates (greater for a positive prediction error than a negative prediction error) could account for unrealistic optimism in a bandit task, in particular the tendency of human subjects to persistently choosing a single option when there are multiple equally good options. Here, we propose an alternative explanation of such persistent behavior, by modeling human behavior using a Bayesian hidden Markov model, the Dynamic Belief Model (DBM). We find that DBM captures human choice behavior better than the previously proposed asymmetric RL model. Whereas asymmetric RL attains a measure of optimism by giving better-than-expected outcomes higher learning weights compared to worse-than-expected outcomes, DBM does so by progressively devaluing the unchosen options, thus placing a greater emphasis on choice history independent of reward outcome (e.g. an oft-chosen option might continue to be preferred even if it has not been particularly rewarding), which has broadly been shown to underlie sequential effects in a variety of behavioral settings. Moreover, previous work showed that the devaluation of unchosen options in DBM helps to compensate for a default assumption of environmental non-stationarity, thus allowing the decision-maker to both be more adaptive in changing environments and still obtain near-optimal performance in stationary environments. Thus, the current work suggests both a novel rationale and mechanism for persistent behavior in bandit tasks.
 分享
分享



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
