Dieuwke Hupkes, Mario Giulianelli, Verna Dankers, Mikel Artetxe, Yanai Elazar, Tiago Pimentel, Christos Christodoulopoulos, Karim Lasri, Naomi Saphra, Arabella Sinclair, Dennis Ulmer, Florian Schottmann, Khuyagbaatar Batsuren, Kaiser Sun, Koustuv Sinha, Leila Khalatbari, Maria Ryskina, Rita Frieske, Ryan Cotterell, Zhijing Jin
{"title":"NLP 泛化研究的分类与回顾","authors":"Dieuwke Hupkes, Mario Giulianelli, Verna Dankers, Mikel Artetxe, Yanai Elazar, Tiago Pimentel, Christos Christodoulopoulos, Karim Lasri, Naomi Saphra, Arabella Sinclair, Dennis Ulmer, Florian Schottmann, Khuyagbaatar Batsuren, Kaiser Sun, Koustuv Sinha, Leila Khalatbari, Maria Ryskina, Rita Frieske, Ryan Cotterell, Zhijing Jin","doi":"10.1038/s42256-023-00729-y","DOIUrl":null,"url":null,"abstract":"The ability to generalize well is one of the primary desiderata for models of natural language processing (NLP), but what ‘good generalization’ entails and how it should be evaluated is not well understood. In this Analysis we present a taxonomy for characterizing and understanding generalization research in NLP. The proposed taxonomy is based on an extensive literature review and contains five axes along which generalization studies can differ: their main motivation, the type of generalization they aim to solve, the type of data shift they consider, the source by which this data shift originated, and the locus of the shift within the NLP modelling pipeline. We use our taxonomy to classify over 700 experiments, and we use the results to present an in-depth analysis that maps out the current state of generalization research in NLP and make recommendations for which areas deserve attention in the future. With the rapid development of natural language processing (NLP) models in the last decade came the realization that high performance levels on test sets do not imply that a model robustly generalizes to a wide range of scenarios. Hupkes et al. review generalization approaches in the NLP literature and propose a taxonomy based on five axes to analyse such studies: motivation, type of generalization, type of data shift, the source of this data shift, and the locus of the shift within the modelling pipeline.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"5 10","pages":"1161-1174"},"PeriodicalIF":23.9000,"publicationDate":"2023-10-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s42256-023-00729-y.pdf","citationCount":"0","resultStr":"{\"title\":\"A taxonomy and review of generalization research in NLP\",\"authors\":\"Dieuwke Hupkes, Mario Giulianelli, Verna Dankers, Mikel Artetxe, Yanai Elazar, Tiago Pimentel, Christos Christodoulopoulos, Karim Lasri, Naomi Saphra, Arabella Sinclair, Dennis Ulmer, Florian Schottmann, Khuyagbaatar Batsuren, Kaiser Sun, Koustuv Sinha, Leila Khalatbari, Maria Ryskina, Rita Frieske, Ryan Cotterell, Zhijing Jin\",\"doi\":\"10.1038/s42256-023-00729-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"The ability to generalize well is one of the primary desiderata for models of natural language processing (NLP), but what ‘good generalization’ entails and how it should be evaluated is not well understood. In this Analysis we present a taxonomy for characterizing and understanding generalization research in NLP. The proposed taxonomy is based on an extensive literature review and contains five axes along which generalization studies can differ: their main motivation, the type of generalization they aim to solve, the type of data shift they consider, the source by which this data shift originated, and the locus of the shift within the NLP modelling pipeline. We use our taxonomy to classify over 700 experiments, and we use the results to present an in-depth analysis that maps out the current state of generalization research in NLP and make recommendations for which areas deserve attention in the future. With the rapid development of natural language processing (NLP) models in the last decade came the realization that high performance levels on test sets do not imply that a model robustly generalizes to a wide range of scenarios. Hupkes et al. review generalization approaches in the NLP literature and propose a taxonomy based on five axes to analyse such studies: motivation, type of generalization, type of data shift, the source of this data shift, and the locus of the shift within the modelling pipeline.\",\"PeriodicalId\":48533,\"journal\":{\"name\":\"Nature Machine Intelligence\",\"volume\":\"5 10\",\"pages\":\"1161-1174\"},\"PeriodicalIF\":23.9000,\"publicationDate\":\"2023-10-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s42256-023-00729-y.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Machine Intelligence\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.nature.com/articles/s42256-023-00729-y\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-023-00729-y","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
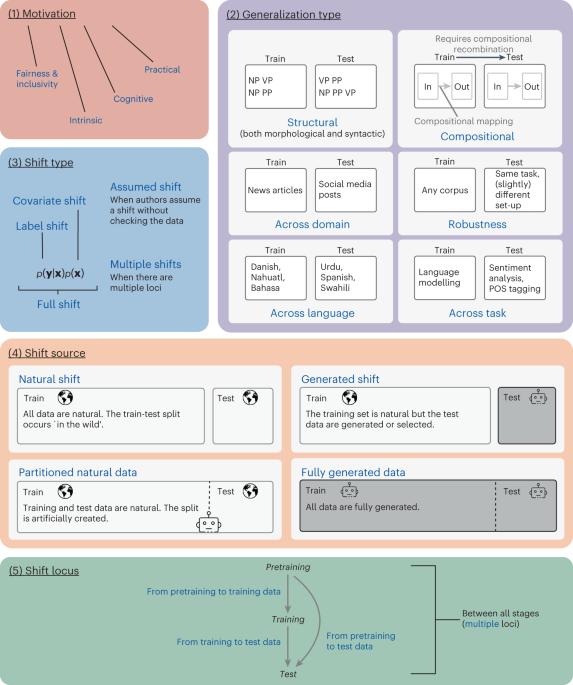
A taxonomy and review of generalization research in NLP
The ability to generalize well is one of the primary desiderata for models of natural language processing (NLP), but what ‘good generalization’ entails and how it should be evaluated is not well understood. In this Analysis we present a taxonomy for characterizing and understanding generalization research in NLP. The proposed taxonomy is based on an extensive literature review and contains five axes along which generalization studies can differ: their main motivation, the type of generalization they aim to solve, the type of data shift they consider, the source by which this data shift originated, and the locus of the shift within the NLP modelling pipeline. We use our taxonomy to classify over 700 experiments, and we use the results to present an in-depth analysis that maps out the current state of generalization research in NLP and make recommendations for which areas deserve attention in the future. With the rapid development of natural language processing (NLP) models in the last decade came the realization that high performance levels on test sets do not imply that a model robustly generalizes to a wide range of scenarios. Hupkes et al. review generalization approaches in the NLP literature and propose a taxonomy based on five axes to analyse such studies: motivation, type of generalization, type of data shift, the source of this data shift, and the locus of the shift within the modelling pipeline.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
