{"title":"混合数据的条件特征重要性","authors":"Kristin Blesch, David S. Watson, Marvin N. Wright","doi":"10.1007/s10182-023-00477-9","DOIUrl":null,"url":null,"abstract":"<div><p>Despite the popularity of feature importance (FI) measures in interpretable machine learning, the statistical adequacy of these methods is rarely discussed. From a statistical perspective, a major distinction is between analysing a variable’s importance before and after adjusting for covariates—i.e., between <i>marginal</i> and <i>conditional</i> measures. Our work draws attention to this rarely acknowledged, yet crucial distinction and showcases its implications. We find that few methods are available for testing conditional FI and practitioners have hitherto been severely restricted in method application due to mismatched data requirements. Most real-world data exhibits complex feature dependencies and incorporates both continuous and categorical features (i.e., mixed data). Both properties are oftentimes neglected by conditional FI measures. To fill this gap, we propose to combine the conditional predictive impact (CPI) framework with sequential knockoff sampling. The CPI enables conditional FI measurement that controls for any feature dependencies by sampling valid knockoffs—hence, generating synthetic data with similar statistical properties—for the data to be analysed. Sequential knockoffs were deliberately designed to handle mixed data and thus allow us to extend the CPI approach to such datasets. We demonstrate through numerous simulations and a real-world example that our proposed workflow controls type I error, achieves high power, and is in-line with results given by other conditional FI measures, whereas marginal FI metrics can result in misleading interpretations. Our findings highlight the necessity of developing statistically adequate, specialized methods for mixed data.</p></div>","PeriodicalId":55446,"journal":{"name":"Asta-Advances in Statistical Analysis","volume":"108 2","pages":"259 - 278"},"PeriodicalIF":1.4000,"publicationDate":"2023-04-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10182-023-00477-9.pdf","citationCount":"0","resultStr":"{\"title\":\"Conditional feature importance for mixed data\",\"authors\":\"Kristin Blesch, David S. Watson, Marvin N. Wright\",\"doi\":\"10.1007/s10182-023-00477-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Despite the popularity of feature importance (FI) measures in interpretable machine learning, the statistical adequacy of these methods is rarely discussed. From a statistical perspective, a major distinction is between analysing a variable’s importance before and after adjusting for covariates—i.e., between <i>marginal</i> and <i>conditional</i> measures. Our work draws attention to this rarely acknowledged, yet crucial distinction and showcases its implications. We find that few methods are available for testing conditional FI and practitioners have hitherto been severely restricted in method application due to mismatched data requirements. Most real-world data exhibits complex feature dependencies and incorporates both continuous and categorical features (i.e., mixed data). Both properties are oftentimes neglected by conditional FI measures. To fill this gap, we propose to combine the conditional predictive impact (CPI) framework with sequential knockoff sampling. The CPI enables conditional FI measurement that controls for any feature dependencies by sampling valid knockoffs—hence, generating synthetic data with similar statistical properties—for the data to be analysed. Sequential knockoffs were deliberately designed to handle mixed data and thus allow us to extend the CPI approach to such datasets. We demonstrate through numerous simulations and a real-world example that our proposed workflow controls type I error, achieves high power, and is in-line with results given by other conditional FI measures, whereas marginal FI metrics can result in misleading interpretations. Our findings highlight the necessity of developing statistically adequate, specialized methods for mixed data.</p></div>\",\"PeriodicalId\":55446,\"journal\":{\"name\":\"Asta-Advances in Statistical Analysis\",\"volume\":\"108 2\",\"pages\":\"259 - 278\"},\"PeriodicalIF\":1.4000,\"publicationDate\":\"2023-04-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s10182-023-00477-9.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Asta-Advances in Statistical Analysis\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10182-023-00477-9\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Asta-Advances in Statistical Analysis","FirstCategoryId":"100","ListUrlMain":"https://link.springer.com/article/10.1007/s10182-023-00477-9","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 0
摘要
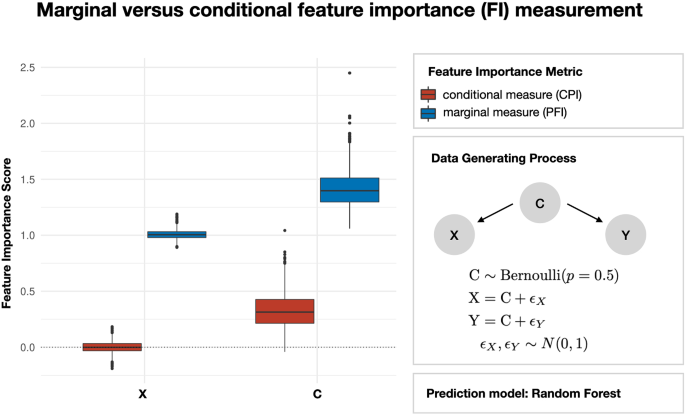
尽管特征重要性(FI)测量方法在可解释机器学习中很受欢迎,但很少有人讨论这些方法的统计充分性。从统计学的角度来看,一个主要的区别在于分析变量在调整协变量之前和之后的重要性,即边际测量和条件测量之间的区别。我们的研究提请人们注意这一鲜为人知但却至关重要的区别,并展示其影响。我们发现,目前可用来测试条件 FI 的方法很少,而且由于数据要求不匹配,从业人员在方法应用方面一直受到严重限制。现实世界中的大多数数据都表现出复杂的特征依赖性,同时包含连续和分类特征(即混合数据)。条件 FI 方法往往忽略了这两种特性。为了填补这一空白,我们建议将条件预测影响(CPI)框架与连续山寨抽样相结合。条件预测影响(CPI)通过对有效的山寨产品进行采样,从而生成与待分析数据具有相似统计属性的合成数据,从而实现条件预测影响测量,并控制任何特征依赖性。我们特意设计了连续山寨数据来处理混合数据,因此可以将 CPI 方法扩展到此类数据集。我们通过大量模拟和一个真实世界的例子证明,我们提出的工作流程可以控制 I 型误差,实现高功率,并且与其他条件 FI 指标给出的结果一致,而边际 FI 指标可能会导致误导性解释。我们的研究结果凸显了为混合数据开发统计充分的专门方法的必要性。
Despite the popularity of feature importance (FI) measures in interpretable machine learning, the statistical adequacy of these methods is rarely discussed. From a statistical perspective, a major distinction is between analysing a variable’s importance before and after adjusting for covariates—i.e., between marginal and conditional measures. Our work draws attention to this rarely acknowledged, yet crucial distinction and showcases its implications. We find that few methods are available for testing conditional FI and practitioners have hitherto been severely restricted in method application due to mismatched data requirements. Most real-world data exhibits complex feature dependencies and incorporates both continuous and categorical features (i.e., mixed data). Both properties are oftentimes neglected by conditional FI measures. To fill this gap, we propose to combine the conditional predictive impact (CPI) framework with sequential knockoff sampling. The CPI enables conditional FI measurement that controls for any feature dependencies by sampling valid knockoffs—hence, generating synthetic data with similar statistical properties—for the data to be analysed. Sequential knockoffs were deliberately designed to handle mixed data and thus allow us to extend the CPI approach to such datasets. We demonstrate through numerous simulations and a real-world example that our proposed workflow controls type I error, achieves high power, and is in-line with results given by other conditional FI measures, whereas marginal FI metrics can result in misleading interpretations. Our findings highlight the necessity of developing statistically adequate, specialized methods for mixed data.
期刊介绍:
AStA - Advances in Statistical Analysis, a journal of the German Statistical Society, is published quarterly and presents original contributions on statistical methods and applications and review articles.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
