{"title":"VGF-Net:用于无人机导航和高度映射的视觉几何融合学习","authors":"Yilin Liu, Ke Xie, Hui Huang","doi":"10.1016/j.gmod.2021.101108","DOIUrl":null,"url":null,"abstract":"<div><p><span>The drone navigation requires the comprehensive understanding of both visual and geometric information in the 3D world. In this paper, we present a </span><em>Visual-Geometric Fusion Network</em><span> (VGF-Net), a deep network for the fusion analysis of visual/geometric data and the construction of 2.5D height maps for simultaneous drone navigation in novel environments. Given an initial rough height map and a sequence of RGB images, our VGF-Net extracts the visual information of the scene, along with a sparse set of 3D keypoints that capture the geometric relationship between objects in the scene. Driven by the data, VGF-Net adaptively fuses visual and geometric information, forming a unified </span><em>Visual-Geometric Representation</em>. This representation is fed to a new <em>Directional Attention Model</em> (DAM), which helps enhance the visual-geometric object relationship and propagates the informative data to dynamically refine the height map and the corresponding keypoints. An entire end-to-end information fusion and mapping system is formed, demonstrating remarkable robustness and high accuracy on the autonomous drone navigation across complex indoor and large-scale outdoor scenes.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"116 ","pages":"Article 101108"},"PeriodicalIF":2.2000,"publicationDate":"2021-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.gmod.2021.101108","citationCount":"14","resultStr":"{\"title\":\"VGF-Net: Visual-Geometric fusion learning for simultaneous drone navigation and height mapping\",\"authors\":\"Yilin Liu, Ke Xie, Hui Huang\",\"doi\":\"10.1016/j.gmod.2021.101108\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p><span>The drone navigation requires the comprehensive understanding of both visual and geometric information in the 3D world. In this paper, we present a </span><em>Visual-Geometric Fusion Network</em><span> (VGF-Net), a deep network for the fusion analysis of visual/geometric data and the construction of 2.5D height maps for simultaneous drone navigation in novel environments. Given an initial rough height map and a sequence of RGB images, our VGF-Net extracts the visual information of the scene, along with a sparse set of 3D keypoints that capture the geometric relationship between objects in the scene. Driven by the data, VGF-Net adaptively fuses visual and geometric information, forming a unified </span><em>Visual-Geometric Representation</em>. This representation is fed to a new <em>Directional Attention Model</em> (DAM), which helps enhance the visual-geometric object relationship and propagates the informative data to dynamically refine the height map and the corresponding keypoints. An entire end-to-end information fusion and mapping system is formed, demonstrating remarkable robustness and high accuracy on the autonomous drone navigation across complex indoor and large-scale outdoor scenes.</p></div>\",\"PeriodicalId\":55083,\"journal\":{\"name\":\"Graphical Models\",\"volume\":\"116 \",\"pages\":\"Article 101108\"},\"PeriodicalIF\":2.2000,\"publicationDate\":\"2021-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1016/j.gmod.2021.101108\",\"citationCount\":\"14\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Graphical Models\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1524070321000138\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2021/5/7 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070321000138","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/5/7 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
VGF-Net: Visual-Geometric fusion learning for simultaneous drone navigation and height mapping
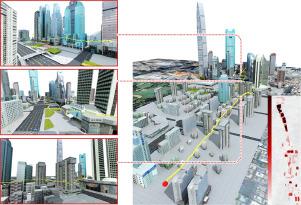
The drone navigation requires the comprehensive understanding of both visual and geometric information in the 3D world. In this paper, we present a Visual-Geometric Fusion Network (VGF-Net), a deep network for the fusion analysis of visual/geometric data and the construction of 2.5D height maps for simultaneous drone navigation in novel environments. Given an initial rough height map and a sequence of RGB images, our VGF-Net extracts the visual information of the scene, along with a sparse set of 3D keypoints that capture the geometric relationship between objects in the scene. Driven by the data, VGF-Net adaptively fuses visual and geometric information, forming a unified Visual-Geometric Representation. This representation is fed to a new Directional Attention Model (DAM), which helps enhance the visual-geometric object relationship and propagates the informative data to dynamically refine the height map and the corresponding keypoints. An entire end-to-end information fusion and mapping system is formed, demonstrating remarkable robustness and high accuracy on the autonomous drone navigation across complex indoor and large-scale outdoor scenes.
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
