Zarif L Azher, Anish Suvarna, Ji-Qing Chen, Ze Zhang, Brock C Christensen, Lucas A Salas, Louis J Vaickus, Joshua J Levy
{"title":"评估可解释多模态深度学习中用于癌症预测的新兴预训练策略。","authors":"Zarif L Azher, Anish Suvarna, Ji-Qing Chen, Ze Zhang, Brock C Christensen, Lucas A Salas, Louis J Vaickus, Joshua J Levy","doi":"10.1186/s13040-023-00338-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Deep learning models can infer cancer patient prognosis from molecular and anatomic pathology information. Recent studies that leveraged information from complementary multimodal data improved prognostication, further illustrating the potential utility of such methods. However, current approaches: 1) do not comprehensively leverage biological and histomorphological relationships and 2) make use of emerging strategies to \"pretrain\" models (i.e., train models on a slightly orthogonal dataset/modeling objective) which may aid prognostication by reducing the amount of information required for achieving optimal performance. In addition, model interpretation is crucial for facilitating the clinical adoption of deep learning methods by fostering practitioner understanding and trust in the technology.</p><p><strong>Methods: </strong>Here, we develop an interpretable multimodal modeling framework that combines DNA methylation, gene expression, and histopathology (i.e., tissue slides) data, and we compare performance of crossmodal pretraining, contrastive learning, and transfer learning versus the standard procedure.</p><p><strong>Results: </strong>Our models outperform the existing state-of-the-art method (average 11.54% C-index increase), and baseline clinically driven models (average 11.7% C-index increase). Model interpretations elucidate consideration of biologically meaningful factors in making prognosis predictions.</p><p><strong>Discussion: </strong>Our results demonstrate that the selection of pretraining strategies is crucial for obtaining highly accurate prognostication models, even more so than devising an innovative model architecture, and further emphasize the all-important role of the tumor microenvironment on disease progression.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"23"},"PeriodicalIF":6.1000,"publicationDate":"2023-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10363299/pdf/","citationCount":"2","resultStr":"{\"title\":\"Assessment of emerging pretraining strategies in interpretable multimodal deep learning for cancer prognostication.\",\"authors\":\"Zarif L Azher, Anish Suvarna, Ji-Qing Chen, Ze Zhang, Brock C Christensen, Lucas A Salas, Louis J Vaickus, Joshua J Levy\",\"doi\":\"10.1186/s13040-023-00338-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Deep learning models can infer cancer patient prognosis from molecular and anatomic pathology information. Recent studies that leveraged information from complementary multimodal data improved prognostication, further illustrating the potential utility of such methods. However, current approaches: 1) do not comprehensively leverage biological and histomorphological relationships and 2) make use of emerging strategies to \\\"pretrain\\\" models (i.e., train models on a slightly orthogonal dataset/modeling objective) which may aid prognostication by reducing the amount of information required for achieving optimal performance. In addition, model interpretation is crucial for facilitating the clinical adoption of deep learning methods by fostering practitioner understanding and trust in the technology.</p><p><strong>Methods: </strong>Here, we develop an interpretable multimodal modeling framework that combines DNA methylation, gene expression, and histopathology (i.e., tissue slides) data, and we compare performance of crossmodal pretraining, contrastive learning, and transfer learning versus the standard procedure.</p><p><strong>Results: </strong>Our models outperform the existing state-of-the-art method (average 11.54% C-index increase), and baseline clinically driven models (average 11.7% C-index increase). Model interpretations elucidate consideration of biologically meaningful factors in making prognosis predictions.</p><p><strong>Discussion: </strong>Our results demonstrate that the selection of pretraining strategies is crucial for obtaining highly accurate prognostication models, even more so than devising an innovative model architecture, and further emphasize the all-important role of the tumor microenvironment on disease progression.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"16 1\",\"pages\":\"23\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2023-07-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10363299/pdf/\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-023-00338-w\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00338-w","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Assessment of emerging pretraining strategies in interpretable multimodal deep learning for cancer prognostication.
Background: Deep learning models can infer cancer patient prognosis from molecular and anatomic pathology information. Recent studies that leveraged information from complementary multimodal data improved prognostication, further illustrating the potential utility of such methods. However, current approaches: 1) do not comprehensively leverage biological and histomorphological relationships and 2) make use of emerging strategies to "pretrain" models (i.e., train models on a slightly orthogonal dataset/modeling objective) which may aid prognostication by reducing the amount of information required for achieving optimal performance. In addition, model interpretation is crucial for facilitating the clinical adoption of deep learning methods by fostering practitioner understanding and trust in the technology.
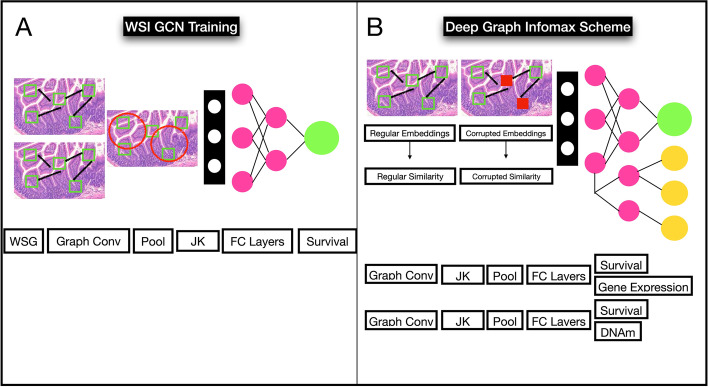
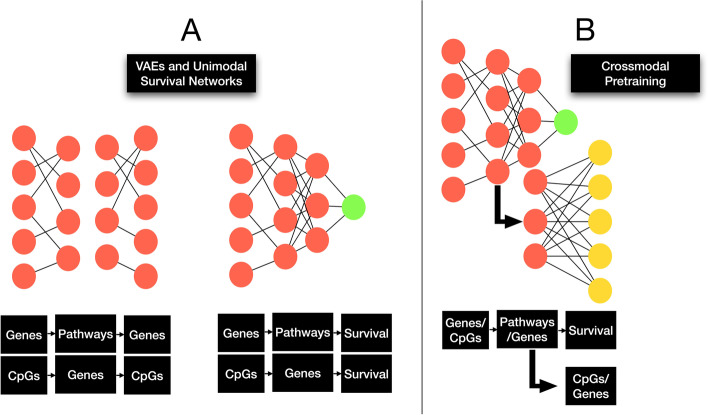
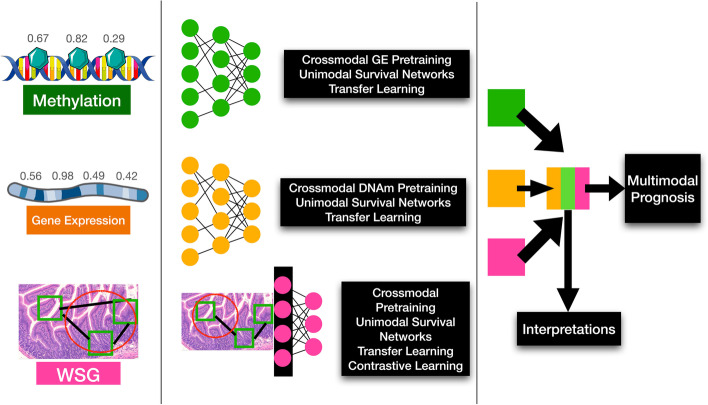
Methods: Here, we develop an interpretable multimodal modeling framework that combines DNA methylation, gene expression, and histopathology (i.e., tissue slides) data, and we compare performance of crossmodal pretraining, contrastive learning, and transfer learning versus the standard procedure.
Results: Our models outperform the existing state-of-the-art method (average 11.54% C-index increase), and baseline clinically driven models (average 11.7% C-index increase). Model interpretations elucidate consideration of biologically meaningful factors in making prognosis predictions.
Discussion: Our results demonstrate that the selection of pretraining strategies is crucial for obtaining highly accurate prognostication models, even more so than devising an innovative model architecture, and further emphasize the all-important role of the tumor microenvironment on disease progression.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
