{"title":"基于DIANA的听觉词汇决策实验的计算建模。","authors":"Filip Nenadić, Benjamin V Tucker, Louis Ten Bosch","doi":"10.1177/00238309221111752","DOIUrl":null,"url":null,"abstract":"<p><p>We present an implementation of DIANA, a computational model of spoken word recognition, to model responses collected in the Massive Auditory Lexical Decision (MALD) project. DIANA is an end-to-end model, including an activation and decision component that takes the acoustic signal as input, activates internal word representations, and outputs lexicality judgments and estimated response latencies. Simulation 1 presents the process of creating acoustic models required by DIANA to analyze novel speech input. Simulation 2 investigates DIANA's performance in determining whether the input signal is a word present in the lexicon or a pseudoword. In Simulation 3, we generate estimates of response latency and correlate them with general tendencies in participant responses in MALD data. We find that DIANA performs fairly well in free word recognition and lexical decision. However, the current approach for estimating response latency provides estimates opposite to those found in behavioral data. We discuss these findings and offer suggestions as to what a contemporary model of spoken word recognition should be able to do.</p>","PeriodicalId":51255,"journal":{"name":"Language and Speech","volume":"66 3","pages":"564-605"},"PeriodicalIF":1.1000,"publicationDate":"2023-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/36/4f/10.1177_00238309221111752.PMC10394956.pdf","citationCount":"0","resultStr":"{\"title\":\"Computational Modeling of an Auditory Lexical Decision Experiment Using DIANA.\",\"authors\":\"Filip Nenadić, Benjamin V Tucker, Louis Ten Bosch\",\"doi\":\"10.1177/00238309221111752\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>We present an implementation of DIANA, a computational model of spoken word recognition, to model responses collected in the Massive Auditory Lexical Decision (MALD) project. DIANA is an end-to-end model, including an activation and decision component that takes the acoustic signal as input, activates internal word representations, and outputs lexicality judgments and estimated response latencies. Simulation 1 presents the process of creating acoustic models required by DIANA to analyze novel speech input. Simulation 2 investigates DIANA's performance in determining whether the input signal is a word present in the lexicon or a pseudoword. In Simulation 3, we generate estimates of response latency and correlate them with general tendencies in participant responses in MALD data. We find that DIANA performs fairly well in free word recognition and lexical decision. However, the current approach for estimating response latency provides estimates opposite to those found in behavioral data. We discuss these findings and offer suggestions as to what a contemporary model of spoken word recognition should be able to do.</p>\",\"PeriodicalId\":51255,\"journal\":{\"name\":\"Language and Speech\",\"volume\":\"66 3\",\"pages\":\"564-605\"},\"PeriodicalIF\":1.1000,\"publicationDate\":\"2023-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/36/4f/10.1177_00238309221111752.PMC10394956.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Language and Speech\",\"FirstCategoryId\":\"98\",\"ListUrlMain\":\"https://doi.org/10.1177/00238309221111752\",\"RegionNum\":2,\"RegionCategory\":\"文学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"AUDIOLOGY & SPEECH-LANGUAGE PATHOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language and Speech","FirstCategoryId":"98","ListUrlMain":"https://doi.org/10.1177/00238309221111752","RegionNum":2,"RegionCategory":"文学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"AUDIOLOGY & SPEECH-LANGUAGE PATHOLOGY","Score":null,"Total":0}
Computational Modeling of an Auditory Lexical Decision Experiment Using DIANA.
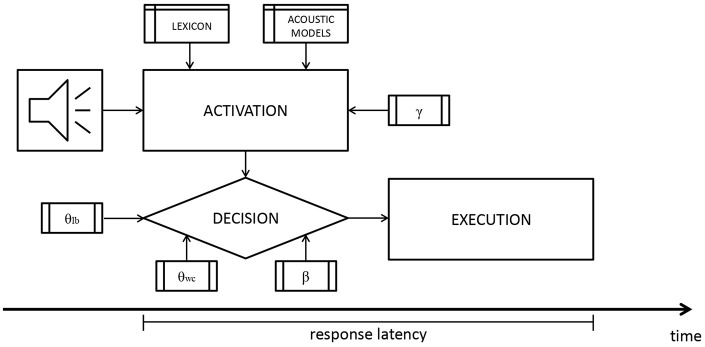
We present an implementation of DIANA, a computational model of spoken word recognition, to model responses collected in the Massive Auditory Lexical Decision (MALD) project. DIANA is an end-to-end model, including an activation and decision component that takes the acoustic signal as input, activates internal word representations, and outputs lexicality judgments and estimated response latencies. Simulation 1 presents the process of creating acoustic models required by DIANA to analyze novel speech input. Simulation 2 investigates DIANA's performance in determining whether the input signal is a word present in the lexicon or a pseudoword. In Simulation 3, we generate estimates of response latency and correlate them with general tendencies in participant responses in MALD data. We find that DIANA performs fairly well in free word recognition and lexical decision. However, the current approach for estimating response latency provides estimates opposite to those found in behavioral data. We discuss these findings and offer suggestions as to what a contemporary model of spoken word recognition should be able to do.
期刊介绍:
Language and Speech is a peer-reviewed journal which provides an international forum for communication among researchers in the disciplines that contribute to our understanding of the production, perception, processing, learning, use, and disorders of speech and language. The journal accepts reports of original research in all these areas.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
