David Nickson, Henrik Singmann, Caroline Meyer, Carla Toro, Lukasz Walasek
{"title":"Replicability and reproducibility of predictive models for diagnosis of depression among young adults using Electronic Health Records.","authors":"David Nickson, Henrik Singmann, Caroline Meyer, Carla Toro, Lukasz Walasek","doi":"10.1186/s41512-023-00160-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Recent advances in machine learning combined with the growing availability of digitized health records offer new opportunities for improving early diagnosis of depression. An emerging body of research shows that Electronic Health Records can be used to accurately predict cases of depression on the basis of individual's primary care records. The successes of these studies are undeniable, but there is a growing concern that their results may not be replicable, which could cast doubt on their clinical usefulness.</p><p><strong>Methods: </strong>To address this issue in the present paper, we set out to reproduce and replicate the work by Nichols et al. (2018), who trained predictive models of depression among young adults using Electronic Healthcare Records. Our contribution consists of three parts. First, we attempt to replicate the methodology used by the original authors, acquiring a more up-to-date set of primary health care records to the same specification and reproducing their data processing and analysis. Second, we test models presented in the original paper on our own data, thus providing out-of-sample prediction of the predictive models. Third, we extend past work by considering several novel machine-learning approaches in an attempt to improve the predictive accuracy achieved in the original work.</p><p><strong>Results: </strong>In summary, our results demonstrate that the work of Nichols et al. is largely reproducible and replicable. This was the case both for the replication of the original model and the out-of-sample replication applying NRCBM coefficients to our new EHRs data. Although alternative predictive models did not improve model performance over standard logistic regression, our results indicate that stepwise variable selection is not stable even in the case of large data sets.</p><p><strong>Conclusion: </strong>We discuss the challenges associated with the research on mental health and Electronic Health Records, including the need to produce interpretable and robust models. We demonstrated some potential issues associated with the reliance on EHRs, including changes in the regulations and guidelines (such as the QOF guidelines in the UK) and reliance on visits to GP as a predictor of specific disorders.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":"7 1","pages":"25"},"PeriodicalIF":2.6000,"publicationDate":"2023-12-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10696659/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-023-00160-2","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Recent advances in machine learning combined with the growing availability of digitized health records offer new opportunities for improving early diagnosis of depression. An emerging body of research shows that Electronic Health Records can be used to accurately predict cases of depression on the basis of individual's primary care records. The successes of these studies are undeniable, but there is a growing concern that their results may not be replicable, which could cast doubt on their clinical usefulness.
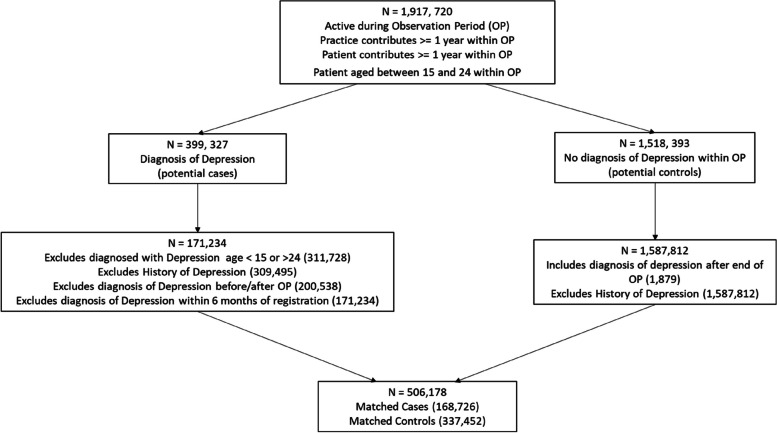
Methods: To address this issue in the present paper, we set out to reproduce and replicate the work by Nichols et al. (2018), who trained predictive models of depression among young adults using Electronic Healthcare Records. Our contribution consists of three parts. First, we attempt to replicate the methodology used by the original authors, acquiring a more up-to-date set of primary health care records to the same specification and reproducing their data processing and analysis. Second, we test models presented in the original paper on our own data, thus providing out-of-sample prediction of the predictive models. Third, we extend past work by considering several novel machine-learning approaches in an attempt to improve the predictive accuracy achieved in the original work.
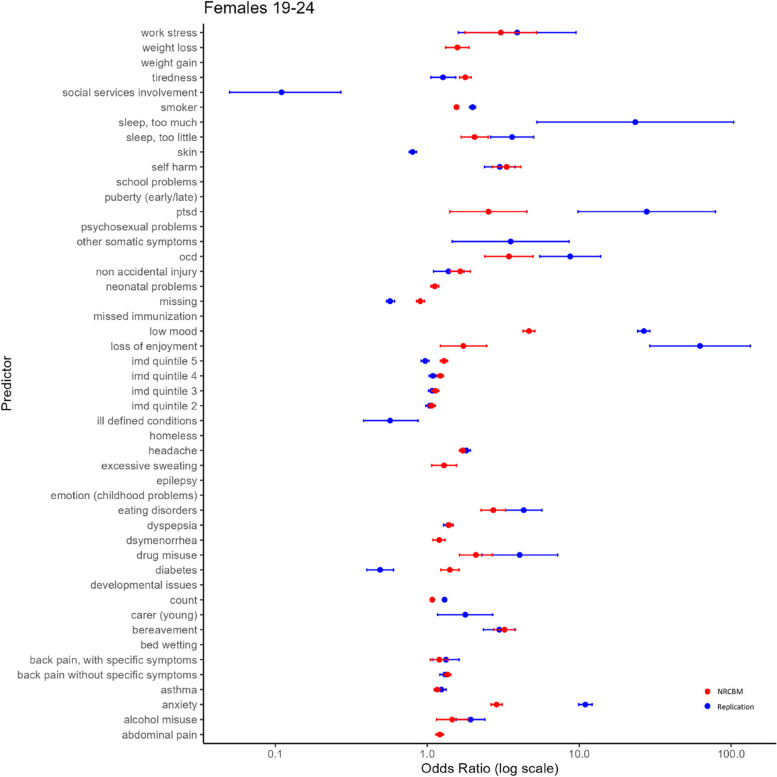
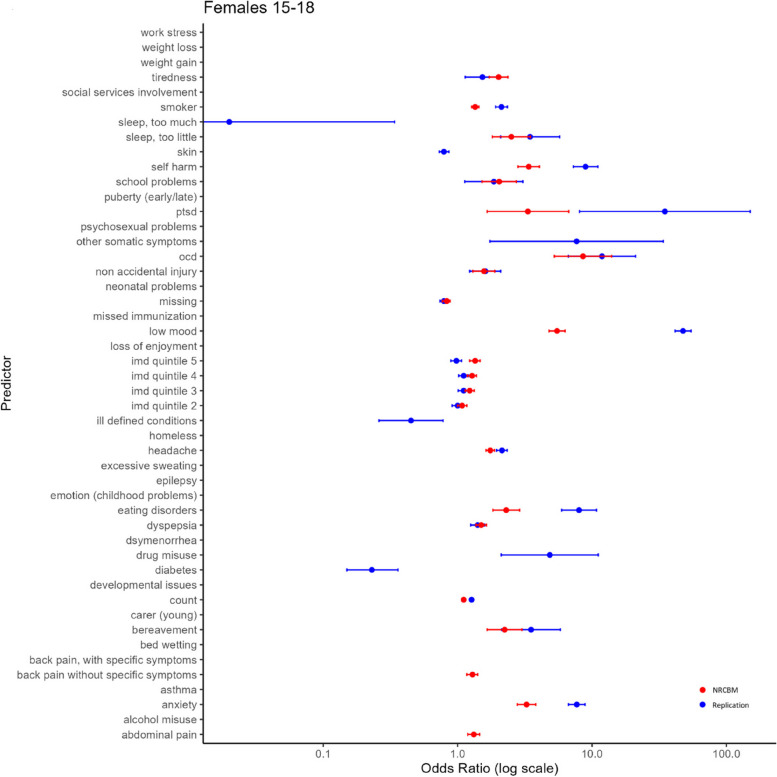
Results: In summary, our results demonstrate that the work of Nichols et al. is largely reproducible and replicable. This was the case both for the replication of the original model and the out-of-sample replication applying NRCBM coefficients to our new EHRs data. Although alternative predictive models did not improve model performance over standard logistic regression, our results indicate that stepwise variable selection is not stable even in the case of large data sets.
Conclusion: We discuss the challenges associated with the research on mental health and Electronic Health Records, including the need to produce interpretable and robust models. We demonstrated some potential issues associated with the reliance on EHRs, including changes in the regulations and guidelines (such as the QOF guidelines in the UK) and reliance on visits to GP as a predictor of specific disorders.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
