{"title":"A deep learning framework for multi-object tracking in team sports videos","authors":"Wei Cao, Xiaoyong Wang, Xianxiang Liu, Yishuai Xu","doi":"10.1049/cvi2.12266","DOIUrl":null,"url":null,"abstract":"<p>In response to the challenges of Multi-Object Tracking (MOT) in sports scenes, such as severe occlusions, similar appearances, drastic pose changes, and complex motion patterns, a deep-learning framework CTGMOT (CNN-Transformer-GNN-based MOT) specifically for multiple athlete tracking in sports videos that performs joint modelling of detection, appearance and motion features is proposed. Firstly, a detection network that combines Convolutional Neural Networks (CNN) and Transformers is constructed to extract both local and global features from images. The fusion of appearance and motion features is achieved through a design of parallel dual-branch decoders. Secondly, graph models are built using Graph Neural Networks (GNN) to accurately capture the spatio-temporal correlations between object and trajectory features from inter-frame and intra-frame associations. Experimental results on the public sports tracking dataset SportsMOT show that the proposed framework outperforms other state-of-the-art methods for MOT in complex sport scenes. In addition, the proposed framework shows excellent generality on benchmark datasets MOT17 and MOT20.</p>","PeriodicalId":56304,"journal":{"name":"IET Computer Vision","volume":"18 5","pages":"574-590"},"PeriodicalIF":1.3000,"publicationDate":"2024-01-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12266","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/cvi2.12266","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
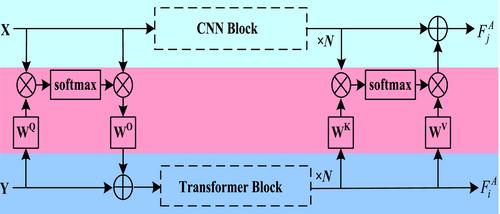
In response to the challenges of Multi-Object Tracking (MOT) in sports scenes, such as severe occlusions, similar appearances, drastic pose changes, and complex motion patterns, a deep-learning framework CTGMOT (CNN-Transformer-GNN-based MOT) specifically for multiple athlete tracking in sports videos that performs joint modelling of detection, appearance and motion features is proposed. Firstly, a detection network that combines Convolutional Neural Networks (CNN) and Transformers is constructed to extract both local and global features from images. The fusion of appearance and motion features is achieved through a design of parallel dual-branch decoders. Secondly, graph models are built using Graph Neural Networks (GNN) to accurately capture the spatio-temporal correlations between object and trajectory features from inter-frame and intra-frame associations. Experimental results on the public sports tracking dataset SportsMOT show that the proposed framework outperforms other state-of-the-art methods for MOT in complex sport scenes. In addition, the proposed framework shows excellent generality on benchmark datasets MOT17 and MOT20.
期刊介绍:
IET Computer Vision seeks original research papers in a wide range of areas of computer vision. The vision of the journal is to publish the highest quality research work that is relevant and topical to the field, but not forgetting those works that aim to introduce new horizons and set the agenda for future avenues of research in computer vision.
IET Computer Vision welcomes submissions on the following topics:
Biologically and perceptually motivated approaches to low level vision (feature detection, etc.);
Perceptual grouping and organisation
Representation, analysis and matching of 2D and 3D shape
Shape-from-X
Object recognition
Image understanding
Learning with visual inputs
Motion analysis and object tracking
Multiview scene analysis
Cognitive approaches in low, mid and high level vision
Control in visual systems
Colour, reflectance and light
Statistical and probabilistic models
Face and gesture
Surveillance
Biometrics and security
Robotics
Vehicle guidance
Automatic model aquisition
Medical image analysis and understanding
Aerial scene analysis and remote sensing
Deep learning models in computer vision
Both methodological and applications orientated papers are welcome.
Manuscripts submitted are expected to include a detailed and analytical review of the literature and state-of-the-art exposition of the original proposed research and its methodology, its thorough experimental evaluation, and last but not least, comparative evaluation against relevant and state-of-the-art methods. Submissions not abiding by these minimum requirements may be returned to authors without being sent to review.
Special Issues Current Call for Papers:
Computer Vision for Smart Cameras and Camera Networks - https://digital-library.theiet.org/files/IET_CVI_SC.pdf
Computer Vision for the Creative Industries - https://digital-library.theiet.org/files/IET_CVI_CVCI.pdf




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
