{"title":"Differentially private federated learning with non-IID data","authors":"Shuyan Cheng, Peng Li, Ruchuan Wang, He Xu","doi":"10.1007/s00607-024-01257-2","DOIUrl":null,"url":null,"abstract":"<p>In Differentially Private Federated Learning (DPFL), gradient clipping and random noise addition disproportionately affect statistically heterogeneous data. As a consequence, DPFL has a disparate impact: the accuracy of models trained with DPFL tends to decrease more on these data. If the accuracy of the original model decreases on heterogeneous data, DPFL may degrade the accuracy performance more. In this work, we study the utility loss inequality due to differential privacy and compare the convergence of the private and non-private models. Specifically, we analyze the gradient differences caused by statistically heterogeneous data and explain how statistical heterogeneity relates to the effect of privacy on model convergence. In addition, we propose an improved DPFL algorithm, called R-DPFL, to achieve differential privacy at the same cost but with good utility. R-DPFL adjusts the gradient clipping value and the number of selected users at beginning according to the degree of statistical heterogeneity of the data, and weakens the direct proportional relationship between the differential privacy and the gradient difference, thereby reducing the impact of differential privacy on the model trained on heterogeneous data. Our experimental evaluation shows the effectiveness of our elimination algorithm in achieving the same cost of differential privacy with satisfactory utility. Our code is publicly available at https://github.com/chengshuyan/R-DPFL.</p>","PeriodicalId":10718,"journal":{"name":"Computing","volume":"20 1","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00607-024-01257-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
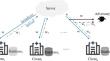
Abstract
In Differentially Private Federated Learning (DPFL), gradient clipping and random noise addition disproportionately affect statistically heterogeneous data. As a consequence, DPFL has a disparate impact: the accuracy of models trained with DPFL tends to decrease more on these data. If the accuracy of the original model decreases on heterogeneous data, DPFL may degrade the accuracy performance more. In this work, we study the utility loss inequality due to differential privacy and compare the convergence of the private and non-private models. Specifically, we analyze the gradient differences caused by statistically heterogeneous data and explain how statistical heterogeneity relates to the effect of privacy on model convergence. In addition, we propose an improved DPFL algorithm, called R-DPFL, to achieve differential privacy at the same cost but with good utility. R-DPFL adjusts the gradient clipping value and the number of selected users at beginning according to the degree of statistical heterogeneity of the data, and weakens the direct proportional relationship between the differential privacy and the gradient difference, thereby reducing the impact of differential privacy on the model trained on heterogeneous data. Our experimental evaluation shows the effectiveness of our elimination algorithm in achieving the same cost of differential privacy with satisfactory utility. Our code is publicly available at https://github.com/chengshuyan/R-DPFL.
期刊介绍:
Computing publishes original papers, short communications and surveys on all fields of computing. The contributions should be written in English and may be of theoretical or applied nature, the essential criteria are computational relevance and systematic foundation of results.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
