{"title":"Mining drug-target interactions from biomedical literature using chemical and gene descriptions-based ensemble transformer model.","authors":"Jehad Aldahdooh, Ziaurrehman Tanoli, Jing Tang","doi":"10.1093/bioadv/vbae106","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Drug-target interactions (DTIs) play a pivotal role in drug discovery, as it aims to identify potential drug targets and elucidate their mechanism of action. In recent years, the application of natural language processing (NLP), particularly when combined with pre-trained language models, has gained considerable momentum in the biomedical domain, with the potential to mine vast amounts of texts to facilitate the efficient extraction of DTIs from the literature.</p><p><strong>Results: </strong>In this article, we approach the task of DTIs as an entity-relationship extraction problem, utilizing different pre-trained transformer language models, such as BERT, to extract DTIs. Our results indicate that an ensemble approach, by combining gene descriptions from the Entrez Gene database with chemical descriptions from the Comparative Toxicogenomics Database (CTD), is critical for achieving optimal performance. The proposed model achieves an <i>F</i>1 score of 80.6 on the hidden DrugProt test set, which is the top-ranked performance among all the submitted models in the official evaluation. Furthermore, we conduct a comparative analysis to evaluate the effectiveness of various gene textual descriptions sourced from Entrez Gene and UniProt databases to gain insights into their impact on the performance. Our findings highlight the potential of NLP-based text mining using gene and chemical descriptions to improve drug-target extraction tasks.</p><p><strong>Availability and implementation: </strong>Datasets utilized in this study are accessible at https://dtis.drugtargetcommons.org/.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"4 1","pages":"vbae106"},"PeriodicalIF":2.8000,"publicationDate":"2024-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11293871/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbae106","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
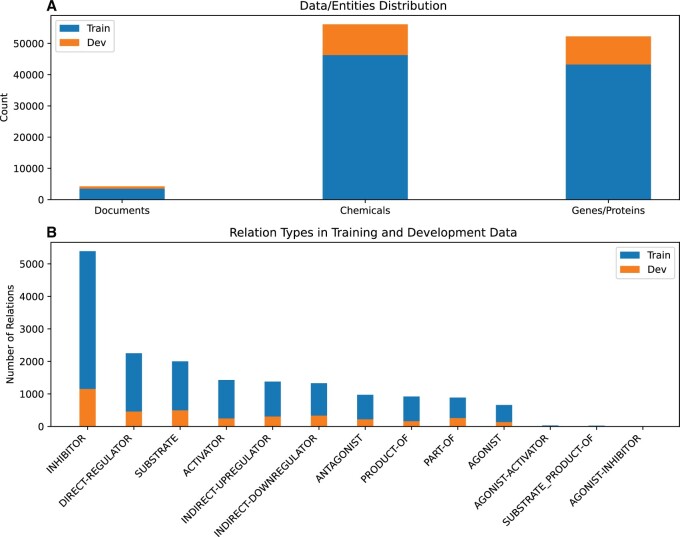
Motivation: Drug-target interactions (DTIs) play a pivotal role in drug discovery, as it aims to identify potential drug targets and elucidate their mechanism of action. In recent years, the application of natural language processing (NLP), particularly when combined with pre-trained language models, has gained considerable momentum in the biomedical domain, with the potential to mine vast amounts of texts to facilitate the efficient extraction of DTIs from the literature.
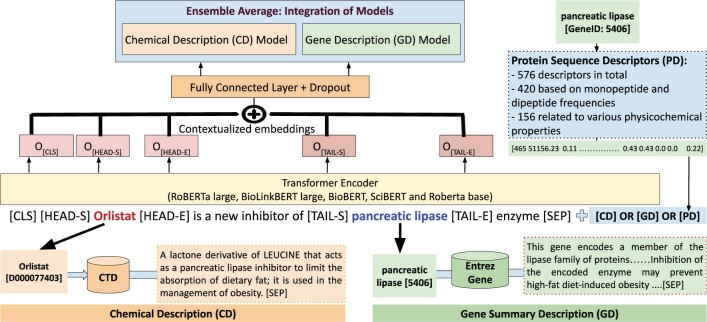
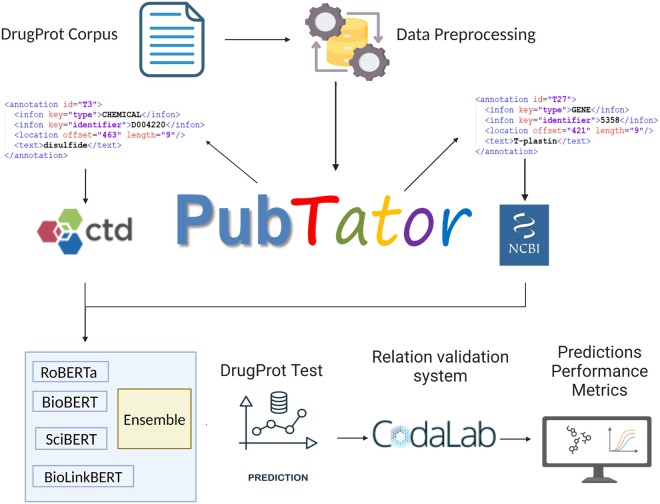
Results: In this article, we approach the task of DTIs as an entity-relationship extraction problem, utilizing different pre-trained transformer language models, such as BERT, to extract DTIs. Our results indicate that an ensemble approach, by combining gene descriptions from the Entrez Gene database with chemical descriptions from the Comparative Toxicogenomics Database (CTD), is critical for achieving optimal performance. The proposed model achieves an F1 score of 80.6 on the hidden DrugProt test set, which is the top-ranked performance among all the submitted models in the official evaluation. Furthermore, we conduct a comparative analysis to evaluate the effectiveness of various gene textual descriptions sourced from Entrez Gene and UniProt databases to gain insights into their impact on the performance. Our findings highlight the potential of NLP-based text mining using gene and chemical descriptions to improve drug-target extraction tasks.
Availability and implementation: Datasets utilized in this study are accessible at https://dtis.drugtargetcommons.org/.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
