Lara J. Kanbar , Anagh Mishra , Alexander Osborn , Andrew Cifuentes , Jennifer Combs , Michael Sorter , Drew Barzman , Judith W. Dexheimer
{"title":"Investigation of bias in the automated assessment of school violence","authors":"Lara J. Kanbar , Anagh Mishra , Alexander Osborn , Andrew Cifuentes , Jennifer Combs , Michael Sorter , Drew Barzman , Judith W. Dexheimer","doi":"10.1016/j.jbi.2024.104709","DOIUrl":null,"url":null,"abstract":"<div><h3>Objectives</h3><p>Natural language processing and machine learning have the potential to lead to biased predictions. We designed a novel Automated RIsk Assessment (ARIA) machine learning algorithm that assesses risk of violence and aggression in adolescents using natural language processing of transcribed student interviews. This work evaluated the possible sources of bias in the study design and the algorithm, tested how much of a prediction was explained by demographic covariates, and investigated the misclassifications based on demographic variables.</p></div><div><h3>Methods</h3><p>We recruited students 10–18 years of age and enrolled in middle or high schools in Ohio, Kentucky, Indiana, and Tennessee. The reference standard outcome was determined by a forensic psychiatrist as either a “high” or “low” risk level. ARIA used L2-regularized logistic regression to predict a risk level for each student using contextual and semantic features. We conducted three analyses: a PROBAST analysis of risk in study design; analysis of demographic variables as covariates; and a prediction analysis. Covariates were included in the linear regression analyses and comprised of race, sex, ethnicity, household education, annual household income, age at the time of visit, and utilization of public assistance.</p></div><div><h3>Results</h3><p>We recruited 412 students from 204 schools. ARIA performed with an AUC of 0.92, sensitivity of 71%, NPV of 77%, and specificity of 95%. Of these, 387 students with complete demographic information were included in the analysis. Individual linear regressions resulted in a coefficient of determination less than 0.08 across all demographic variables. When using all demographic variables to predict ARIA’s risk assessment score, the multiple linear regression model resulted in a coefficient of determination of 0.189. ARIA performed with a lower False Negative Rate (FNR) of 15.2% (CI [0 – 40]) for the Black subgroup and 12.7%, CI [0 – 41.4] for Other races, compared to an FNR of 26.1% (CI [14.1 – 41.8]) in the White subgroup.</p></div><div><h3>Conclusions</h3><p>Bias assessment is needed to address shortcomings within machine learning. In our work, student race, ethnicity, sex, use of public assistance, and annual household income did not explain ARIA’s risk assessment score of students. ARIA will continue to be evaluated regularly with increased subject recruitment.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"157 ","pages":"Article 104709"},"PeriodicalIF":4.5000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001278","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/15 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives
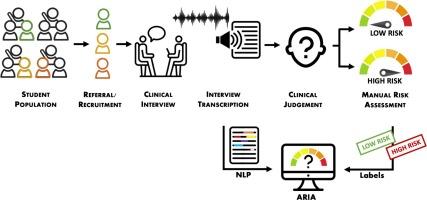
Natural language processing and machine learning have the potential to lead to biased predictions. We designed a novel Automated RIsk Assessment (ARIA) machine learning algorithm that assesses risk of violence and aggression in adolescents using natural language processing of transcribed student interviews. This work evaluated the possible sources of bias in the study design and the algorithm, tested how much of a prediction was explained by demographic covariates, and investigated the misclassifications based on demographic variables.
Methods
We recruited students 10–18 years of age and enrolled in middle or high schools in Ohio, Kentucky, Indiana, and Tennessee. The reference standard outcome was determined by a forensic psychiatrist as either a “high” or “low” risk level. ARIA used L2-regularized logistic regression to predict a risk level for each student using contextual and semantic features. We conducted three analyses: a PROBAST analysis of risk in study design; analysis of demographic variables as covariates; and a prediction analysis. Covariates were included in the linear regression analyses and comprised of race, sex, ethnicity, household education, annual household income, age at the time of visit, and utilization of public assistance.
Results
We recruited 412 students from 204 schools. ARIA performed with an AUC of 0.92, sensitivity of 71%, NPV of 77%, and specificity of 95%. Of these, 387 students with complete demographic information were included in the analysis. Individual linear regressions resulted in a coefficient of determination less than 0.08 across all demographic variables. When using all demographic variables to predict ARIA’s risk assessment score, the multiple linear regression model resulted in a coefficient of determination of 0.189. ARIA performed with a lower False Negative Rate (FNR) of 15.2% (CI [0 – 40]) for the Black subgroup and 12.7%, CI [0 – 41.4] for Other races, compared to an FNR of 26.1% (CI [14.1 – 41.8]) in the White subgroup.
Conclusions
Bias assessment is needed to address shortcomings within machine learning. In our work, student race, ethnicity, sex, use of public assistance, and annual household income did not explain ARIA’s risk assessment score of students. ARIA will continue to be evaluated regularly with increased subject recruitment.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
