Hao Wang, Yuzhuo Chen, Hang Yu, Menghui Qi, De Xia, Minkai Qin, XuCheng Lv, Bing Lu, Ruiliang Gao, Yong Wang, Shanjun Mao
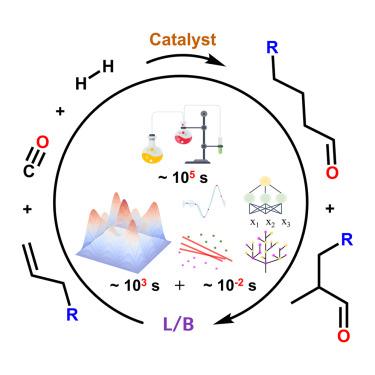
{"title":"Personalized machine learning models of terminal olefin hydroformylation for regioselectivity prediction","authors":"Hao Wang, Yuzhuo Chen, Hang Yu, Menghui Qi, De Xia, Minkai Qin, XuCheng Lv, Bing Lu, Ruiliang Gao, Yong Wang, Shanjun Mao","doi":"10.1016/j.checat.2024.101079","DOIUrl":null,"url":null,"abstract":"<p>The integration of machine learning into hydroformylation processes represents a pivotal advancement in high-throughput screening within the chemical industry. This study employs a data-driven approach to develop predictive models for terminal olefin reactions. Using a database of 1,167 entries, we merged reaction embeddings with corresponding labels. The well-trained extreme gradient boosting model achieves a test set coefficient of determination (R<sup>2</sup>) score of 0.897. However, when applied to specific-olefin tasks, the model shows suboptimal performance. Therefore, tailored models for specific olefins like 1-octene and styrene are developed, achieving improved test set R<sup>2</sup> scores of 0.850 and 0.789, respectively, compared to the general-olefin task. Interpretability findings highlight the significance of high-temperature, low-pressure, and low-concentration metals in enhancing linear regioselectivity and providing chemical insights. This study underscores the transformative potential of machine learning as a surrogate model in advancing high-throughput screening and optimizing chemical processes in the industry.</p>","PeriodicalId":53121,"journal":{"name":"Chem Catalysis","volume":"1 1","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2024-08-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Chem Catalysis","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.checat.2024.101079","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
The integration of machine learning into hydroformylation processes represents a pivotal advancement in high-throughput screening within the chemical industry. This study employs a data-driven approach to develop predictive models for terminal olefin reactions. Using a database of 1,167 entries, we merged reaction embeddings with corresponding labels. The well-trained extreme gradient boosting model achieves a test set coefficient of determination (R2) score of 0.897. However, when applied to specific-olefin tasks, the model shows suboptimal performance. Therefore, tailored models for specific olefins like 1-octene and styrene are developed, achieving improved test set R2 scores of 0.850 and 0.789, respectively, compared to the general-olefin task. Interpretability findings highlight the significance of high-temperature, low-pressure, and low-concentration metals in enhancing linear regioselectivity and providing chemical insights. This study underscores the transformative potential of machine learning as a surrogate model in advancing high-throughput screening and optimizing chemical processes in the industry.
期刊介绍:
Chem Catalysis is a monthly journal that publishes innovative research on fundamental and applied catalysis, providing a platform for researchers across chemistry, chemical engineering, and related fields. It serves as a premier resource for scientists and engineers in academia and industry, covering heterogeneous, homogeneous, and biocatalysis. Emphasizing transformative methods and technologies, the journal aims to advance understanding, introduce novel catalysts, and connect fundamental insights to real-world applications for societal benefit.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
