Tinglin Huang , Syed Asad Rizvi , Rohan Krishna Thakur , Vimig Socrates , Meili Gupta , David van Dijk , R. Andrew Taylor , Rex Ying
{"title":"HEART: Learning better representation of EHR data with a heterogeneous relation-aware transformer","authors":"Tinglin Huang , Syed Asad Rizvi , Rohan Krishna Thakur , Vimig Socrates , Meili Gupta , David van Dijk , R. Andrew Taylor , Rex Ying","doi":"10.1016/j.jbi.2024.104741","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><div>Pretrained language models have recently demonstrated their effectiveness in modeling Electronic Health Record (EHR) data by modeling the encounters of patients as sentences. However, existing methods fall short of utilizing the inherent heterogeneous correlations between medical entities—which include diagnoses, medications, procedures, and lab tests. Existing studies either focus merely on diagnosis entities or encode different entities in a homogeneous space, leading to suboptimal performance. Motivated by this, we aim to develop a foundational language model pre-trained on EHR data with explicitly incorporating the heterogeneous correlations among these entities.</div></div><div><h3>Methods:</h3><div>In this study, we propose <span>HEART</span>, a heterogeneous relation-aware transformer for EHR. Our model includes a range of heterogeneous entities within each input sequence and represents pairwise relationships between entities as a relation embedding. Such a higher-order representation allows the model to perform complex reasoning and derive attention weights in the heterogeneous context. Additionally, a multi-level attention scheme is employed to exploit the connection between different encounters while alleviating the high computational costs. For pretraining, <span>HEART</span> engages with two tasks, missing entity prediction and anomaly detection, which both effectively enhance the model’s performance on various downstream tasks.</div></div><div><h3>Results:</h3><div>Extensive experiments on two EHR datasets and five downstream tasks demonstrate <span>HEART</span>’s superior performance compared to four SOTA foundation models. For instance, <span>HEART</span> achieves improvements of 12.1% and 4.1% over Med-BERT in death and readmission prediction, respectively. Additionally, case studies show that <span>HEART</span> offers interpretable insights into the relationships between entities through the learned relation embeddings.</div></div><div><h3>Conclusion:</h3><div>We study the problem of EHR representation learning and propose HEART, a model that leverages the heterogeneous relationships between medical entities. Our approach includes a multi-level encoding scheme and two specialized pretrained objectives, designed to boost both the efficiency and effectiveness of the model. We have comprehensively evaluated HEART across five clinically significant downstream tasks using two EHR datasets. The experimental results verify the model’s great performance and validate its practical utility in healthcare applications. Code: <span><span>https://github.com/Graph-and-Geometric-Learning/HEART</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"159 ","pages":"Article 104741"},"PeriodicalIF":4.5000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S153204642400159X","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/29 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective:
Pretrained language models have recently demonstrated their effectiveness in modeling Electronic Health Record (EHR) data by modeling the encounters of patients as sentences. However, existing methods fall short of utilizing the inherent heterogeneous correlations between medical entities—which include diagnoses, medications, procedures, and lab tests. Existing studies either focus merely on diagnosis entities or encode different entities in a homogeneous space, leading to suboptimal performance. Motivated by this, we aim to develop a foundational language model pre-trained on EHR data with explicitly incorporating the heterogeneous correlations among these entities.
Methods:
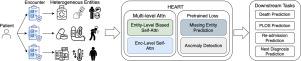
In this study, we propose HEART, a heterogeneous relation-aware transformer for EHR. Our model includes a range of heterogeneous entities within each input sequence and represents pairwise relationships between entities as a relation embedding. Such a higher-order representation allows the model to perform complex reasoning and derive attention weights in the heterogeneous context. Additionally, a multi-level attention scheme is employed to exploit the connection between different encounters while alleviating the high computational costs. For pretraining, HEART engages with two tasks, missing entity prediction and anomaly detection, which both effectively enhance the model’s performance on various downstream tasks.
Results:
Extensive experiments on two EHR datasets and five downstream tasks demonstrate HEART’s superior performance compared to four SOTA foundation models. For instance, HEART achieves improvements of 12.1% and 4.1% over Med-BERT in death and readmission prediction, respectively. Additionally, case studies show that HEART offers interpretable insights into the relationships between entities through the learned relation embeddings.
Conclusion:
We study the problem of EHR representation learning and propose HEART, a model that leverages the heterogeneous relationships between medical entities. Our approach includes a multi-level encoding scheme and two specialized pretrained objectives, designed to boost both the efficiency and effectiveness of the model. We have comprehensively evaluated HEART across five clinically significant downstream tasks using two EHR datasets. The experimental results verify the model’s great performance and validate its practical utility in healthcare applications. Code: https://github.com/Graph-and-Geometric-Learning/HEART.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
