Bodore Al-Baker, Ashraf Ayoub, Xiangyang Ju, Peter Mossey
{"title":"Patch-based convolutional neural networks for automatic landmark detection of 3D facial images in clinical settings.","authors":"Bodore Al-Baker, Ashraf Ayoub, Xiangyang Ju, Peter Mossey","doi":"10.1093/ejo/cjae056","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The facial landmark annotation of 3D facial images is crucial in clinical orthodontics and orthognathic surgeries for accurate diagnosis and treatment planning. While manual landmarking has traditionally been the gold standard, it is labour-intensive and prone to variability.</p><p><strong>Objective: </strong>This study presents a framework for automated landmark detection in 3D facial images within a clinical context, using convolutional neural networks (CNNs), and it assesses its accuracy in comparison to that of ground-truth data.</p><p><strong>Material and methods: </strong>Initially, an in-house dataset of 408 3D facial images, each annotated with 37 landmarks by an expert, was constructed. Subsequently, a 2.5D patch-based CNN architecture was trained using this dataset to detect the same set of landmarks automatically.</p><p><strong>Results: </strong>The developed CNN model demonstrated high accuracy, with an overall mean localization error of 0.83 ± 0.49 mm. The majority of the landmarks had low localization errors, with 95% exhibiting a mean error of less than 1 mm across all axes. Moreover, the method achieved a high success detection rate, with 88% of detections having an error below 1.5 mm and 94% below 2 mm.</p><p><strong>Conclusion: </strong>The automated method used in this study demonstrated accuracy comparable to that achieved with manual annotations within clinical settings. In addition, the proposed framework for automatic landmark localization exhibited improved accuracy over existing models in the literature. Despite these advancements, it is important to acknowledge the limitations of this research, such as that it was based on a single-centre study and a single annotator. Future work should address computational time challenges to achieve further enhancements. This approach has significant potential to improve the efficiency and accuracy of orthodontic and orthognathic procedures.</p>","PeriodicalId":11989,"journal":{"name":"European journal of orthodontics","volume":"46 6","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11602742/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European journal of orthodontics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1093/ejo/cjae056","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"DENTISTRY, ORAL SURGERY & MEDICINE","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The facial landmark annotation of 3D facial images is crucial in clinical orthodontics and orthognathic surgeries for accurate diagnosis and treatment planning. While manual landmarking has traditionally been the gold standard, it is labour-intensive and prone to variability.
Objective: This study presents a framework for automated landmark detection in 3D facial images within a clinical context, using convolutional neural networks (CNNs), and it assesses its accuracy in comparison to that of ground-truth data.
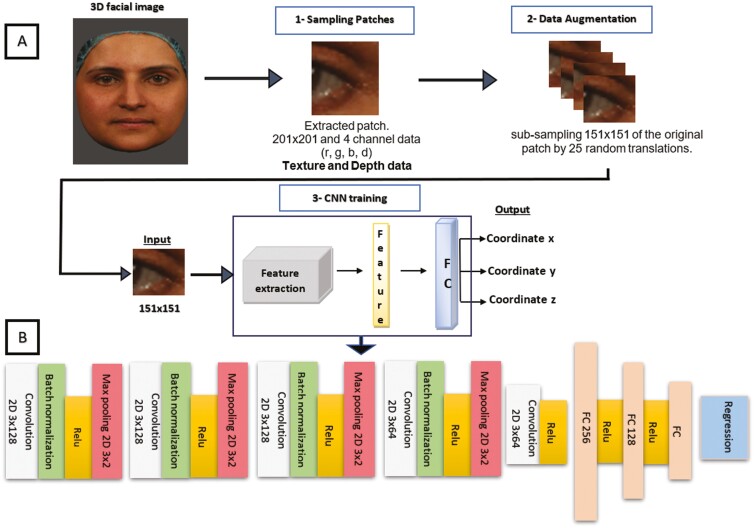
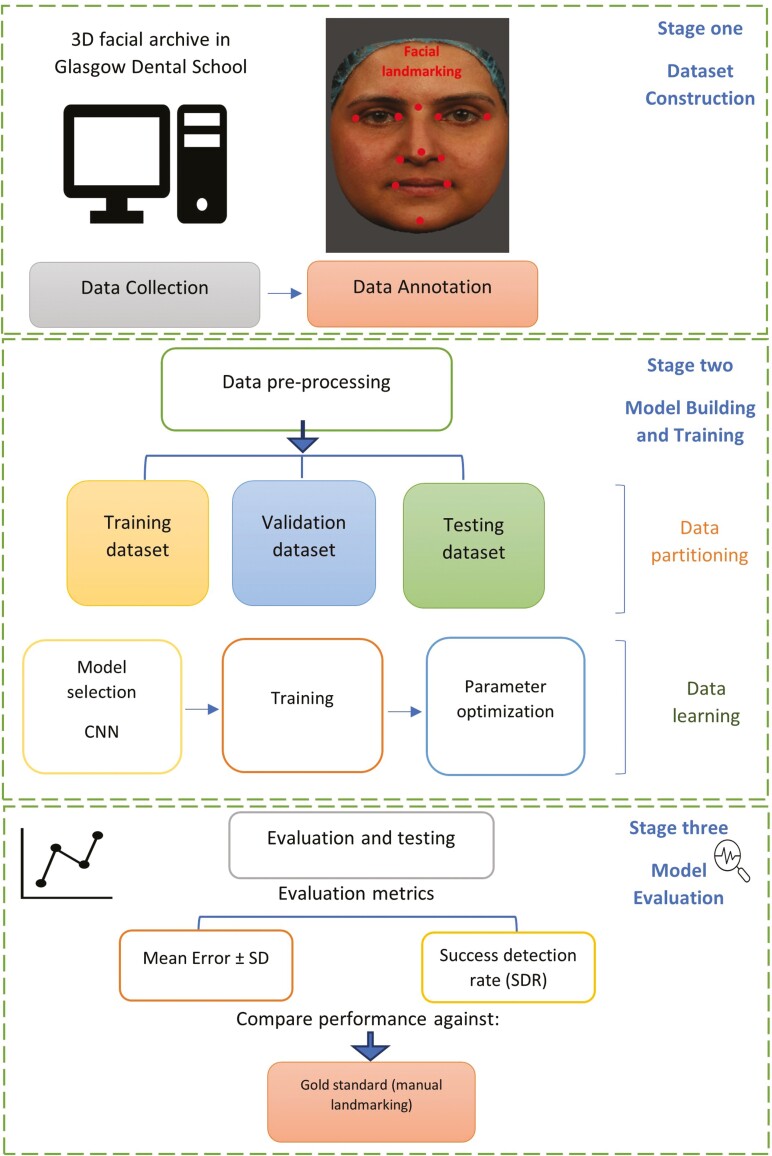
Material and methods: Initially, an in-house dataset of 408 3D facial images, each annotated with 37 landmarks by an expert, was constructed. Subsequently, a 2.5D patch-based CNN architecture was trained using this dataset to detect the same set of landmarks automatically.
Results: The developed CNN model demonstrated high accuracy, with an overall mean localization error of 0.83 ± 0.49 mm. The majority of the landmarks had low localization errors, with 95% exhibiting a mean error of less than 1 mm across all axes. Moreover, the method achieved a high success detection rate, with 88% of detections having an error below 1.5 mm and 94% below 2 mm.
Conclusion: The automated method used in this study demonstrated accuracy comparable to that achieved with manual annotations within clinical settings. In addition, the proposed framework for automatic landmark localization exhibited improved accuracy over existing models in the literature. Despite these advancements, it is important to acknowledge the limitations of this research, such as that it was based on a single-centre study and a single annotator. Future work should address computational time challenges to achieve further enhancements. This approach has significant potential to improve the efficiency and accuracy of orthodontic and orthognathic procedures.
期刊介绍:
The European Journal of Orthodontics publishes papers of excellence on all aspects of orthodontics including craniofacial development and growth. The emphasis of the journal is on full research papers. Succinct and carefully prepared papers are favoured in terms of impact as well as readability.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
