D. S. Matthews, M. A. Spence, A. C. Mater, J. Nichols, S. B. Pulsford, M. Sandhu, J. A. Kaczmarski, C. M. Miton, N. Tokuriki, C. J. Jackson
{"title":"Leveraging ancestral sequence reconstruction for protein representation learning","authors":"D. S. Matthews, M. A. Spence, A. C. Mater, J. Nichols, S. B. Pulsford, M. Sandhu, J. A. Kaczmarski, C. M. Miton, N. Tokuriki, C. J. Jackson","doi":"10.1038/s42256-024-00935-2","DOIUrl":null,"url":null,"abstract":"Protein language models (PLMs) convert amino acid sequences into the numerical representations required to train machine learning models. Many PLMs are large (>600 million parameters) and trained on a broad span of protein sequence space. However, these models have limitations in terms of predictive accuracy and computational cost. Here we use multiplexed ancestral sequence reconstruction to generate small but focused functional protein sequence datasets for PLM training. Compared to large PLMs, this local ancestral sequence embedding produces representations with higher predictive accuracy. We show that due to the evolutionary nature of the ancestral sequence reconstruction data, local ancestral sequence embedding produces smoother fitness landscapes, in which protein variants that are closer in fitness value become numerically closer in representation space. This work contributes to the implementation of machine learning-based protein design in real-world settings, where data are sparse and computational resources are limited. Matthews et al. present a protein sequence embedding based on data from ancestral sequences that allows machine learning to be used for tasks where training data are scarce or expensive.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"6 12","pages":"1542-1555"},"PeriodicalIF":23.9000,"publicationDate":"2024-12-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00935-2","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
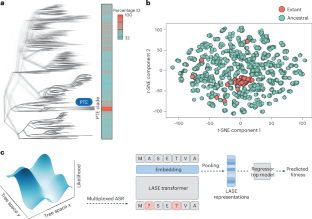
Protein language models (PLMs) convert amino acid sequences into the numerical representations required to train machine learning models. Many PLMs are large (>600 million parameters) and trained on a broad span of protein sequence space. However, these models have limitations in terms of predictive accuracy and computational cost. Here we use multiplexed ancestral sequence reconstruction to generate small but focused functional protein sequence datasets for PLM training. Compared to large PLMs, this local ancestral sequence embedding produces representations with higher predictive accuracy. We show that due to the evolutionary nature of the ancestral sequence reconstruction data, local ancestral sequence embedding produces smoother fitness landscapes, in which protein variants that are closer in fitness value become numerically closer in representation space. This work contributes to the implementation of machine learning-based protein design in real-world settings, where data are sparse and computational resources are limited. Matthews et al. present a protein sequence embedding based on data from ancestral sequences that allows machine learning to be used for tasks where training data are scarce or expensive.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
