Hongling Zheng, Li Shen, Anke Tang, Yong Luo, Han Hu, Bo Du, Yonggang Wen, Dacheng Tao
{"title":"Learning from models beyond fine-tuning","authors":"Hongling Zheng, Li Shen, Anke Tang, Yong Luo, Han Hu, Bo Du, Yonggang Wen, Dacheng Tao","doi":"10.1038/s42256-024-00961-0","DOIUrl":null,"url":null,"abstract":"Foundation models have demonstrated remarkable performance across various tasks, primarily due to their abilities to comprehend instructions and access extensive, high-quality data. These capabilities showcase the effectiveness of current foundation models and suggest a promising trajectory. Owing to multiple constraints, such as the extreme scarcity or inaccessibility of raw data used to train foundation models and the high cost of training large-scale foundation models from scratch, the use of pre-existing foundation models or application programming interfaces for downstream tasks has become a new research trend, which we call Learn from Model (LFM). LFM involves extracting and leveraging prior knowledge from foundation models through fine-tuning, editing and fusion methods and applying it to downstream tasks. We emphasize that maximizing the use of parametric knowledge in data-scarce scenarios is critical to LFM. Analysing the LFM paradigm can guide the selection of the most appropriate technology in a given scenario to minimize parameter storage and computational costs while improving the performance of foundation models on new tasks. This Review provides a comprehensive overview of current methods based on foundation models from the perspective of LFM. Large general-purpose models are becoming more prevalent and useful, but also harder to train and find suitable training data for. Zheng et al. discuss how models can be used to train other models.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"7 1","pages":"6-17"},"PeriodicalIF":23.9000,"publicationDate":"2025-01-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00961-0","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
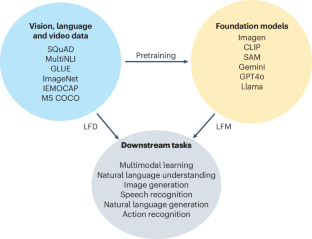
Foundation models have demonstrated remarkable performance across various tasks, primarily due to their abilities to comprehend instructions and access extensive, high-quality data. These capabilities showcase the effectiveness of current foundation models and suggest a promising trajectory. Owing to multiple constraints, such as the extreme scarcity or inaccessibility of raw data used to train foundation models and the high cost of training large-scale foundation models from scratch, the use of pre-existing foundation models or application programming interfaces for downstream tasks has become a new research trend, which we call Learn from Model (LFM). LFM involves extracting and leveraging prior knowledge from foundation models through fine-tuning, editing and fusion methods and applying it to downstream tasks. We emphasize that maximizing the use of parametric knowledge in data-scarce scenarios is critical to LFM. Analysing the LFM paradigm can guide the selection of the most appropriate technology in a given scenario to minimize parameter storage and computational costs while improving the performance of foundation models on new tasks. This Review provides a comprehensive overview of current methods based on foundation models from the perspective of LFM. Large general-purpose models are becoming more prevalent and useful, but also harder to train and find suitable training data for. Zheng et al. discuss how models can be used to train other models.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
