Dale Peasley, Rayus Kuplicki, Sandip Sen, Martin Paulus
{"title":"Leveraging Large Language Models and Agent-Based Systems for Scientific Data Analysis: Validation Study.","authors":"Dale Peasley, Rayus Kuplicki, Sandip Sen, Martin Paulus","doi":"10.2196/68135","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models have shown promise in transforming how complex scientific data are analyzed and communicated, yet their application to scientific domains remains challenged by issues of factual accuracy and domain-specific precision. The Laureate Institute for Brain Research-Tulsa University (LIBR-TU) Research Agent (LITURAt) leverages a sophisticated agent-based architecture to mitigate these limitations, using external data retrieval and analysis tools to ensure reliable, context-aware outputs that make scientific information accessible to both experts and nonexperts.</p><p><strong>Objective: </strong>The objective of this study was to develop and evaluate LITURAt to enable efficient analysis and contextualization of complex scientific datasets for diverse user expertise levels.</p><p><strong>Methods: </strong>An agent-based system based on large language models was designed to analyze and contextualize complex scientific datasets using a \"plan-and-solve\" framework. The system dynamically retrieves local data and relevant PubMed literature, performs statistical analyses, and generates comprehensive, context-aware summaries to answer user queries with high accuracy and consistency.</p><p><strong>Results: </strong>Our experiments demonstrated that LITURAt achieved an internal consistency rate of 94.8% and an external consistency rate of 91.9% across repeated and rephrased queries. Additionally, GPT-4 evaluations rated 80.3% (171/213) of the system's answers as accurate and comprehensive, with 23.5% (50/213) receiving the highest rating of 5 for completeness and precision.</p><p><strong>Conclusions: </strong>These findings highlight the potential of LITURAt to significantly enhance the accessibility and accuracy of scientific data analysis, achieving high consistency and strong performance in complex query resolution. Despite existing limitations, such as model stability for highly variable queries, LITURAt demonstrates promise as a robust tool for democratizing data-driven insights across diverse scientific domains.</p>","PeriodicalId":48616,"journal":{"name":"Jmir Mental Health","volume":"12 ","pages":"e68135"},"PeriodicalIF":5.8000,"publicationDate":"2025-02-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11841814/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Jmir Mental Health","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/68135","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PSYCHIATRY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Large language models have shown promise in transforming how complex scientific data are analyzed and communicated, yet their application to scientific domains remains challenged by issues of factual accuracy and domain-specific precision. The Laureate Institute for Brain Research-Tulsa University (LIBR-TU) Research Agent (LITURAt) leverages a sophisticated agent-based architecture to mitigate these limitations, using external data retrieval and analysis tools to ensure reliable, context-aware outputs that make scientific information accessible to both experts and nonexperts.
Objective: The objective of this study was to develop and evaluate LITURAt to enable efficient analysis and contextualization of complex scientific datasets for diverse user expertise levels.
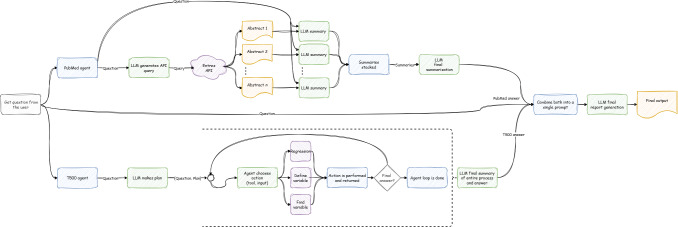
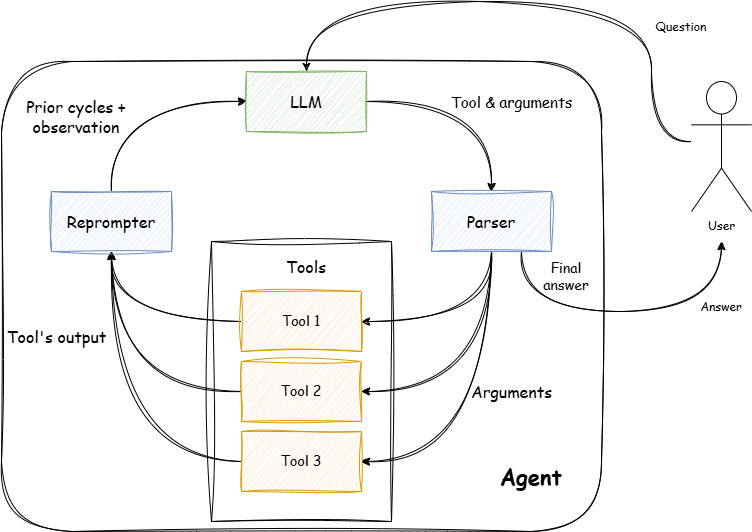
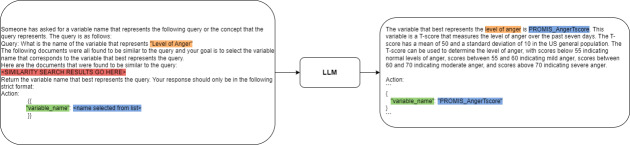
Methods: An agent-based system based on large language models was designed to analyze and contextualize complex scientific datasets using a "plan-and-solve" framework. The system dynamically retrieves local data and relevant PubMed literature, performs statistical analyses, and generates comprehensive, context-aware summaries to answer user queries with high accuracy and consistency.
Results: Our experiments demonstrated that LITURAt achieved an internal consistency rate of 94.8% and an external consistency rate of 91.9% across repeated and rephrased queries. Additionally, GPT-4 evaluations rated 80.3% (171/213) of the system's answers as accurate and comprehensive, with 23.5% (50/213) receiving the highest rating of 5 for completeness and precision.
Conclusions: These findings highlight the potential of LITURAt to significantly enhance the accessibility and accuracy of scientific data analysis, achieving high consistency and strong performance in complex query resolution. Despite existing limitations, such as model stability for highly variable queries, LITURAt demonstrates promise as a robust tool for democratizing data-driven insights across diverse scientific domains.
期刊介绍:
JMIR Mental Health (JMH, ISSN 2368-7959) is a PubMed-indexed, peer-reviewed sister journal of JMIR, the leading eHealth journal (Impact Factor 2016: 5.175).
JMIR Mental Health focusses on digital health and Internet interventions, technologies and electronic innovations (software and hardware) for mental health, addictions, online counselling and behaviour change. This includes formative evaluation and system descriptions, theoretical papers, review papers, viewpoint/vision papers, and rigorous evaluations.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
