{"title":"Introduction: “Noncanonical Amino Acids”","authors":"Nediljko Budisa","doi":"10.1021/acs.chemrev.5c00065","DOIUrl":null,"url":null,"abstract":"Published as part of <i>Chemical Reviews</i> special issue “Noncanonical Amino Acids”. Life is a chemically driven process, shaped by Earth’s geology and relying on persistent small molecules for core chemistry, while transient macromolecules control informational, thermodynamic and kinetic functions. Morowitz and Smith (1) have identified 60 universal carbon metabolites, with the central citric acid cycle providing stable intermediates as building blocks for biosynthesis, including proteins. The genetic code has evolved together with metabolism and expanded from a minimal set of amino acids (e.g., the “Alanine World Model” (2) postulates that there were Gly, Pro, Ala and a cationic amino acid) to the extant canonical 20. The special canonical amino acids selenocysteine and pyrrolysine (3) further expand the genetic code in certain life taxa. Wong’s coevolutionary theory (4) states that the code has evolved together with amino acid biosynthesis, starting with prebiotic amino acids and expanding through the reassignment of codons by means of “codon capture” or “ambiguous intermediate” mechanisms. (5) In this special issue on “<i>Noncanonical Amino Acids</i>”, Tze-Fei Wong builds on his lifelong work on the Co-evolution Theory and presents an excellent article “<i>Triphasic Development of the Genetic Code</i>” describing three distinct phases in the evolution of the genetic code. Phase 1 is the initial development of the amino acid repertoire in the RNA world. Phase 2 marks the emergence of cells with core metabolic pathways capable of delivering stable intermediates that served as precursors for most canonical amino acids in the extant genetic code. With an eye to the future, Wong anticipates Phase 3, in which the genetic code will expand its amino acid repertoire through anthropogenic intervention (incorporation of noncanonical amino acids (ncAAs)), paving the way for synthetic life forms with brand new genetic codes. The 20 α-L-canonical amino acids encoded by the universal genetic code are translated by ribosomal machinery, including tRNA, aminoacyl-tRNA synthetases (aaRSs), ribosomes, and associated factors. Protein translation decodes amino acid structures from nucleic acid sequences and recodes them into proteins, enabling programmable peptide and protein production. Expansion of the genetic code to incorporate ncAAs presents a significant biochemical challenge and offers insights into information flow, evolutionary innovation, and the possibilities for creating an “orthogonal central dogma” (6) (see Scheme 1) and synthetic cells with alternative life chemistry. (7) This approach enables new therapeutic proteins, biocatalysts for synthetic chemistry, and biological containment strategies. Although the technology has immense academic and industrial potential, much of it still remains untapped. <span><sup>a</sup></span>This framework comprises two main approaches: designing alternative nucleic acids (Xeno-Nucleic Acids, XNAs) as information polymers with novel base pairs, sugars and modified backbones and altering the canonical amino acid repertoire of the genetic code to synthesize proteins and proteomes that are new-to-nature, using noncanonical amino acids (ncAAs) and similar monomers. (9) The redesign of genes, genomes, and proteins with XNAs and ncAAs aims to establish an “orthogonal central dogma”. (6) This special issue “<i>Noncanonical Amino Acids</i>” highlights all aspects of the latest advances in genetic code engineering and expansion. It also highlights efforts in metabolic, genomic, and strain engineering to improve genetic code redesign in the context of orthogonal translation. In this context, we gathered leading experts in the field for our special issue “<i>Noncanonical Amino Acids</i>” to present the latest advances and breakthroughs. Most of the contributions are based on <i>in vivo</i> methods but also include <i>in vitro</i> approaches. It has been suggested (8) that about 70% of current codons could be reassigned by utilizing the substrate tolerance of aaRSs and engineering tRNA identity elements. Majekodunmi, Britton and Montclare demonstrated these possibilities through residue-specific insertion, which allows global alteration of protein properties in metabolically modified host cells (e.g., auxotrophs) to create novel proteins and materials. Notable applications of ncAAs include bioorthogonal noncanonical amino acid labeling (BONCAT), fluorescent labeling (FUNCAT, THRONCAT), cross-linking, fluorination, and enzyme engineering. The authors also discussed cell-free protein synthesis, the efficiency of ncAA incorporation, the challenges of engineering aaRSs, and the use of fluorine to customize biomaterials and proteins. The manuscript titled “<i>Residue-Specific Incorporation of Noncanonical Amino Acids in Auxotrophic Hosts: Quo Vadis</i>?” by Marin et al. makes a strong case for the use of metabolic prototypes (auxotrophs) as a viable alternative to stop-codon readthrough approaches, which are limited by the availability of only three stop codons and issues with protein yield. The authors emphasize that these limitations could hinder industrial applications and the broader adoption of genetic code expansion technologies. Instead, they suggest focusing on the reassignment of sense codons for the incorporation of ncAA as a more robust and promising strategy for advancing the field. The incorporation of ncAAs into proteins enables valuable modifications, either at the protein backbone or at the amino acid side chains. While changes in the backbone are often caused by post-translational modifications (PTMs), ribosomal protein translation can introduce these alternations directly into protein backbones by using proline analogues. In this context, Kubyshkin and Rubini provided a detailed and impressive overview of proline analogues, highlighting their natural occurrence, their role in drug development (e.g., nirmatrelvir) and their potential in peptide and protein engineering. Their work thoroughly reviews the unique role of proline and its analogues in protein biogenesis and explores the diverse chemical, physicochemical, and biochemical properties of proline analogues in the context of peptide and protein structures. Both the modified side chains of the α-L-canonical amino acids and their alternative backbone chemistries (nonproteinogenic monomers) can be incorporated into proteins and protein-like polymers (foldamers) using advanced <i>in vitro</i> platforms, offering greater flexibility than current <i>in vivo</i> methods. Sigal et al. highlight tRNAs as key “adaptor” molecules in ribosomal translation, where precise engineering enables reprogrammed biosynthesis with unusual ncAAs like D-amino acids, <i>N</i>-alkyl-amino acids, and β-amino acids, as well as “exotic” monomers such as α-hydroxy acids and α-thio acids. Beyond proof-of-principle, advances in translation efficiency, fidelity, and genetic code expansion have enabled the discovery of bioactive macrocyclic peptides and unique polypeptides for applications in biology, materials science, and pharmaceuticals. The review by Sigal et al. addresses all critical aspects of ribosomal translation reprogramming, including the following: (a) engineering recognition between tRNAs and aaRSs; (b) factors influencing peptide bond formation; and (c) decoding mRNA codons by tRNA anticodons, alongside the challenge of finding blank codon–anticodon pairs for genetic code manipulation. Ishida et al. highlight the “second genetic code”, where aaRSs bind amino acids and tRNAs, discriminate against noncognate substrates (i.e., interprets the genetic code), and generate aminoacyl-tRNAs for translation. Accurate incorporation based on the aaRS specificity, editing mechanisms and tRNA recognition codes complement the “first genetic code”, in which codon-anticodon interactions direct protein synthesis on ribosomes. The ribosome enforces genetic programming by recognizing tRNA-shaped molecules, aligning substrates for catalysis, and maintaining fidelity. Ishida et al. discuss engineering interfaces among amino acids, tRNAs, and the ribosome to incorporate ncAAs, including Elongation-Factor Tu (EF-Tu) modifications and tethered orthogonal ribosomes. Despite advancements, incorporating larger or backbone-modified ncAAs remains challenging, though the engineering of ribosomal peptidyl transferase center (PTC) and exit tunnel modifications offers promise. Costello et al. further detail noncanonical ribosomal decoding <i>in vitro</i> and <i>in vivo</i>, including engineering quadruplets, with comprehensive historical and conceptual insights. Both reviews emphasize ribosomal flexibility in accommodating backbone modifications, though incorporation remains limited to amino acids that can be loaded onto tRNAs via ribozymes or aaRSs. The introduction of novel codon sizes requires further modification and fine-tuning of translational mechanisms. Ward et al. provide an excellent overview of the development of tRNA-based therapies, noting that humans have over 600 tRNA genes. Certain mutant tRNAs can cause translation errors leading to diseases such as neurodegenerative disorders, cancer, and rare genetic conditions. Missense suppressor tRNAs insert incorrect amino acids, while nonsense suppressor tRNAs read through premature stop signals to produce full-length proteins. These mechanisms offer a basis for therapy, where “correct” tRNA variants can be used to correct genetic defects. Ward et al. also discuss the mechanisms of tRNA-based therapies, therapeutic windows for suppressing mutations, wild-type tRNA supplementation, and the challenges and opportunities of delivering tRNAs as synthetic RNAs or gene therapies. The expansion of the genetic code in animal cells and organisms is extensively and greatly detailed by Kim et al., further emphasizing therapeutic and general biotechnological potentials when ncAAs are included in this grand scheme. Finally, the importance of the <i>in vitro</i> platform for pharmaceutical molecule production is brought into focus in the review of Kubick et al., emphasizing cell-free protein synthesis (CFPS) for the incorporation of ncAAs in producing complex biologics such as antibody-drug conjugates (ADCs) and biosynthetic pathways for therapeutic molecules. Dunkelmann and Chin and Koch and Budisa reviewed key advancements in pyrrolysyl-tRNA synthetase (PylRS), a powerful enzyme for incorporating various amino acids into proteins. The PylRS:tRNA<sup>Pyl</sup> pair, with its CUA anticodon, is an effective tool for orthogonal translation systems (OTS) in in-frame stop codon suppression (SCS) and site-specific ncAA incorporation. Particularly noteworthy is the strategy of orthogonal translation optimization based on aaRSs from psychrophilic sources, in contrast to the currently predominant use of enzymes from thermopiles. Similarly, Niu and Guo provided a comprehensive survey of orthogonalized protein translation in cells and organisms, addressing associated challenges. Together, these reviews summarize two decades of progress, including strategies for engineering orthogonal pairs, noncanonical monomers, quadruplets, codon size issues, and metabolic engineering. Central to all these efforts are the selection procedures for identifying and isolating molecular machines capable of incorporating ncAA. This is done by generating gene libraries of selected aaRSs using high-throughput screening techniques, which are covered in detail in the review by Lino et al. and also include genome engineering, adaptive evolution and the design of whole-cell chassis with alternative genetic codes. Recently, several groups have successfully demonstrated the use of phage-presented peptide libraries to achieve further diversification of ncAAs usage, far beyond the classical approaches, as presented by Hampton and Liu. Huang et al. have excellently addressed many often-overlooked aspects in the field, including enzyme chimeras and mutually orthogonal aaRS/tRNA pairs, engineering of tRNA transcription and tRNA chimeric variants and post-transcriptional modifications to improve orthogonal translation. Furthermore, the critical role of incorporating Nonsense-Mediated Decay (NMD) pathways in engineering efforts, and advanced screening methods such as PANCE (Phage-Assisted Non-Continuous Evolution), PACE (Phage-Assisted Continuous Evolution), and PRANCE (Phage- and Robotics-Assisted Near-Continuous Evolution) were discussed as well. Orthogonal machinery for ncAA incorporation often involves gene libraries of specific aminoacyl-tRNA synthetases. Two key systems, the tyrosine pair from <i>Methanocaldococcus jannaschii</i> (<i>Mj</i>TyrRS:tRNA<sup>Tyr</sup>) and the pyrrolysine pair from <i>Methanosarcina</i> species (PylRS:tRNA<sup>Pyl</sup>), were developed for OTS selection in <i>Escherichia coli</i> and other microbial and animal cells. (10) Jann et al. impressively reviewed engineering challenges and applications of nearly 500 ncAAs. <i>Mj</i>TyrRS-based pairs generally outperform PylRS systems in yield and efficiency and are better suited for suppressing multiple stop codons. PylRS-based systems, however, show lower catalytic efficiency and protein yields. It should be noted that E. Lemke and his team have pioneered the use of phase-separated biomolecular condensates to create synthetic organelles in cells with their “own” orthogonal translation, (11) which is a significant advance in the field as a whole. Chemla et al. highlighted the transformative potential of ncAAs in bioelectrochemistry (e.g., fuel cells, biobatteries) and materials science (e.g., smart biomaterials, therapeutic proteins, engineered fibers), providing a valuable resource on biomaterials and bioelectrochemistry enabled by orthogonal translation. Biocatalysis with ncAAs is an emerging field with significant potential for expansion, offering opportunities to influence enzymatic reactions, create novel active sites, and catalyze new-to-nature reactions, as highlighted by Green et al. and Drienovská, Roelfes, et al. The use of photocaged and photoswitchable ncAAs for optical control of protein activity as well as spatiotemporal regulation of biological function should enable optogenetics with atomic precision as elaborated by Deiters et al. Infield et al. described the use of ncAAs in channels for mechanistic studies involving photochemistry (e.g., cross-linking and caged amino acids) and atomic mutagenesis (isosteric manipulation of charge, aromaticity, and backbone mutation), as well as fluorescent ncAAs for real-time studies. Feng et al. provided a very useful overview of biological spectroscopy and microscopy with a focus on ncAAs that can be inserted at predetermined positions as site-specific vibrational, fluorescent, electron paramagnetic resonance (EPR), or nuclear magnetic resonance (NMR) probes. Yi et al. also provided a detailed account of the usefulness of ncAAs as valuable spectroscopic and biophysical probes in cellular, organismal, and <i>in vitro</i> settings, highlighting developments over the past two decades. De Faveri et al. provided an insightful historical account and overview of current developments, highlighting the challenges of using ncAAs in membrane proteins, particularly in mammalian cell culture systems for functional expression. Their work emphasizes the need for engineering orthogonal pairs for efficient use in eukaryotes and to employ mild bioorthogonal reactions such as “click” chemistry to attach probes to membrane proteins in live cells, thus allowing the study of protein structure and dynamics <i>in situ</i>. The major challenge of bioorthogonal reactions is their bimolecular nature, which often results in inefficiency. Cao and Wang highlighted latent bioreactive ncAAs that enable selective covalent bonding through proximity-activated reactivity and offer numerous applications, including capturing transient interactions, modifying protein properties, and developing therapeutic agents such as covalent peptides and site-specifically labeled antibody conjugates. The use of noncanonical amino acids as “tags” inserted at predetermined positions is a highly compelling approach to mimic or introduce new post-translational modifications (PTMs). Gan and Fan’s review highlights the use of orthogonal translation to create novel, low-stoichiometry PTM sites on proteins without disrupting local microenvironments, enabling precise functional studies. Allen et al. describe the use of ncAAs, including phosphoserine, phosphothreonine, phosphotyrosine, and their mimics, to study reversible phosphorylation─a key mechanism for regulating protein function─by directly incorporating phosphoamino acids during orthogonal translation, eliminating the need for kinase-based or chemical synthesis methods. Finally, ubiquitylation, one of the most diverse PTMs essential for eukaryotic biology, has been systematically explored using ncAAs, as excellently demonstrated by Lang et al. Orthogonal translation enables synthetic, noninvasive, site-specific ubiquitylation─a crucial step toward unraveling the complexity of the ubiquitin code, its biological context, and relevant applications. This special issue shows how orthogonal translation with the incorporation of noncanonical amino acids into proteins by expanding or substituting the genetic code repertoire has reached a level of intellectual maturity that enables the transition of the entire field from purely academic research to an industrially relevant discipline and technology. A primary challenge in genetic code expansion via translation readthrough of in-frame stop codons is the limited availability of triplet codons for permanent reassignment as well as the metabolic availability of the desired ncAAs. This limitation can be addressed by strategies such as sense codon reassignment, as it is estimated that 30 to 40 sense codons are sufficient to encode an organism’s genetic information, leaving over 20 sense codons available for recoding with ncAAs. (12) Reprogramming protein translation with noncanonical amino acids allows us to reinterpret the original genetic message and effectively alter the “universal” genetic code─the fundamental language of life on Earth. This area of research pushes the boundaries of chemical composition and biochemical principles of life and contributes to our understanding of the origins of life. It also paves the way for the creation of synthetic life with alternative genetic codes and enables the development of novel biobased and bioinspired technologies for the benefit of society. Nediljko Budisa was born in 1966 and studied biology, chemistry, molecular biology and molecular biophysics at the University of Zagreb in Croatia. He completed his PhD in 1997 and then worked as a postdoc at the Max Planck Institute of Biochemistry (MPIB) in Martinsried, Germany, from 1997 to 2000. From 2001 to 2005, he habilitated in Biochemistry at the Technical University of Munich, and from 2005 to 2010, he was an independent group leader at the MPIB in the field of “Molecular Biotechnology”. In May 2010, he was appointed W3 Professor of Biocatalysis at the Technical University of Berlin, Institute of Chemistry. Since 2018, he has been Professor of Chemistry and holds the Tier-1 Canada Research Chair (CRC) in Chemical Synthetic Biology and Xenobiology at the University of Manitoba in Winnipeg, Canada. A pioneer in the field of genetic code engineering, he has significantly advanced the cotranslational incorporation of noncanonical amino acids into proteins. In addition to focusing on life engineering by modifying its chemical makeup, his work investigates the evolution and reprogramming of the genetic code with the aim of transforming the entire field from an academic discipline into a useful technology for healthcare and industry. aminoacyl-tRNA synthetase noncanonical amino acid orthogonal translation system posttranslational modifications Stop Codon Suppression transfer Ribo Nucleic Acid This article references 12 other publications. This article has not yet been cited by other publications.","PeriodicalId":32,"journal":{"name":"Chemical Reviews","volume":"66 1","pages":""},"PeriodicalIF":55.8000,"publicationDate":"2025-02-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Chemical Reviews","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acs.chemrev.5c00065","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
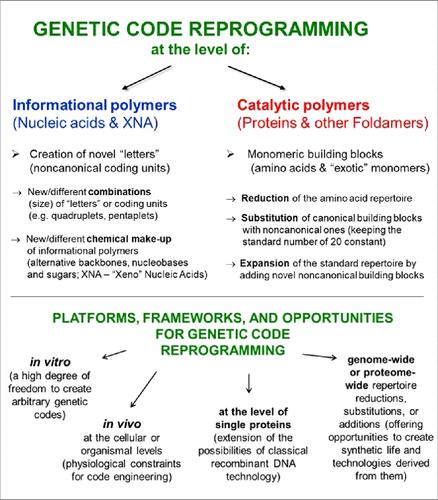
Published as part of Chemical Reviews special issue “Noncanonical Amino Acids”. Life is a chemically driven process, shaped by Earth’s geology and relying on persistent small molecules for core chemistry, while transient macromolecules control informational, thermodynamic and kinetic functions. Morowitz and Smith (1) have identified 60 universal carbon metabolites, with the central citric acid cycle providing stable intermediates as building blocks for biosynthesis, including proteins. The genetic code has evolved together with metabolism and expanded from a minimal set of amino acids (e.g., the “Alanine World Model” (2) postulates that there were Gly, Pro, Ala and a cationic amino acid) to the extant canonical 20. The special canonical amino acids selenocysteine and pyrrolysine (3) further expand the genetic code in certain life taxa. Wong’s coevolutionary theory (4) states that the code has evolved together with amino acid biosynthesis, starting with prebiotic amino acids and expanding through the reassignment of codons by means of “codon capture” or “ambiguous intermediate” mechanisms. (5) In this special issue on “Noncanonical Amino Acids”, Tze-Fei Wong builds on his lifelong work on the Co-evolution Theory and presents an excellent article “Triphasic Development of the Genetic Code” describing three distinct phases in the evolution of the genetic code. Phase 1 is the initial development of the amino acid repertoire in the RNA world. Phase 2 marks the emergence of cells with core metabolic pathways capable of delivering stable intermediates that served as precursors for most canonical amino acids in the extant genetic code. With an eye to the future, Wong anticipates Phase 3, in which the genetic code will expand its amino acid repertoire through anthropogenic intervention (incorporation of noncanonical amino acids (ncAAs)), paving the way for synthetic life forms with brand new genetic codes. The 20 α-L-canonical amino acids encoded by the universal genetic code are translated by ribosomal machinery, including tRNA, aminoacyl-tRNA synthetases (aaRSs), ribosomes, and associated factors. Protein translation decodes amino acid structures from nucleic acid sequences and recodes them into proteins, enabling programmable peptide and protein production. Expansion of the genetic code to incorporate ncAAs presents a significant biochemical challenge and offers insights into information flow, evolutionary innovation, and the possibilities for creating an “orthogonal central dogma” (6) (see Scheme 1) and synthetic cells with alternative life chemistry. (7) This approach enables new therapeutic proteins, biocatalysts for synthetic chemistry, and biological containment strategies. Although the technology has immense academic and industrial potential, much of it still remains untapped. aThis framework comprises two main approaches: designing alternative nucleic acids (Xeno-Nucleic Acids, XNAs) as information polymers with novel base pairs, sugars and modified backbones and altering the canonical amino acid repertoire of the genetic code to synthesize proteins and proteomes that are new-to-nature, using noncanonical amino acids (ncAAs) and similar monomers. (9) The redesign of genes, genomes, and proteins with XNAs and ncAAs aims to establish an “orthogonal central dogma”. (6) This special issue “Noncanonical Amino Acids” highlights all aspects of the latest advances in genetic code engineering and expansion. It also highlights efforts in metabolic, genomic, and strain engineering to improve genetic code redesign in the context of orthogonal translation. In this context, we gathered leading experts in the field for our special issue “Noncanonical Amino Acids” to present the latest advances and breakthroughs. Most of the contributions are based on in vivo methods but also include in vitro approaches. It has been suggested (8) that about 70% of current codons could be reassigned by utilizing the substrate tolerance of aaRSs and engineering tRNA identity elements. Majekodunmi, Britton and Montclare demonstrated these possibilities through residue-specific insertion, which allows global alteration of protein properties in metabolically modified host cells (e.g., auxotrophs) to create novel proteins and materials. Notable applications of ncAAs include bioorthogonal noncanonical amino acid labeling (BONCAT), fluorescent labeling (FUNCAT, THRONCAT), cross-linking, fluorination, and enzyme engineering. The authors also discussed cell-free protein synthesis, the efficiency of ncAA incorporation, the challenges of engineering aaRSs, and the use of fluorine to customize biomaterials and proteins. The manuscript titled “Residue-Specific Incorporation of Noncanonical Amino Acids in Auxotrophic Hosts: Quo Vadis?” by Marin et al. makes a strong case for the use of metabolic prototypes (auxotrophs) as a viable alternative to stop-codon readthrough approaches, which are limited by the availability of only three stop codons and issues with protein yield. The authors emphasize that these limitations could hinder industrial applications and the broader adoption of genetic code expansion technologies. Instead, they suggest focusing on the reassignment of sense codons for the incorporation of ncAA as a more robust and promising strategy for advancing the field. The incorporation of ncAAs into proteins enables valuable modifications, either at the protein backbone or at the amino acid side chains. While changes in the backbone are often caused by post-translational modifications (PTMs), ribosomal protein translation can introduce these alternations directly into protein backbones by using proline analogues. In this context, Kubyshkin and Rubini provided a detailed and impressive overview of proline analogues, highlighting their natural occurrence, their role in drug development (e.g., nirmatrelvir) and their potential in peptide and protein engineering. Their work thoroughly reviews the unique role of proline and its analogues in protein biogenesis and explores the diverse chemical, physicochemical, and biochemical properties of proline analogues in the context of peptide and protein structures. Both the modified side chains of the α-L-canonical amino acids and their alternative backbone chemistries (nonproteinogenic monomers) can be incorporated into proteins and protein-like polymers (foldamers) using advanced in vitro platforms, offering greater flexibility than current in vivo methods. Sigal et al. highlight tRNAs as key “adaptor” molecules in ribosomal translation, where precise engineering enables reprogrammed biosynthesis with unusual ncAAs like D-amino acids, N-alkyl-amino acids, and β-amino acids, as well as “exotic” monomers such as α-hydroxy acids and α-thio acids. Beyond proof-of-principle, advances in translation efficiency, fidelity, and genetic code expansion have enabled the discovery of bioactive macrocyclic peptides and unique polypeptides for applications in biology, materials science, and pharmaceuticals. The review by Sigal et al. addresses all critical aspects of ribosomal translation reprogramming, including the following: (a) engineering recognition between tRNAs and aaRSs; (b) factors influencing peptide bond formation; and (c) decoding mRNA codons by tRNA anticodons, alongside the challenge of finding blank codon–anticodon pairs for genetic code manipulation. Ishida et al. highlight the “second genetic code”, where aaRSs bind amino acids and tRNAs, discriminate against noncognate substrates (i.e., interprets the genetic code), and generate aminoacyl-tRNAs for translation. Accurate incorporation based on the aaRS specificity, editing mechanisms and tRNA recognition codes complement the “first genetic code”, in which codon-anticodon interactions direct protein synthesis on ribosomes. The ribosome enforces genetic programming by recognizing tRNA-shaped molecules, aligning substrates for catalysis, and maintaining fidelity. Ishida et al. discuss engineering interfaces among amino acids, tRNAs, and the ribosome to incorporate ncAAs, including Elongation-Factor Tu (EF-Tu) modifications and tethered orthogonal ribosomes. Despite advancements, incorporating larger or backbone-modified ncAAs remains challenging, though the engineering of ribosomal peptidyl transferase center (PTC) and exit tunnel modifications offers promise. Costello et al. further detail noncanonical ribosomal decoding in vitro and in vivo, including engineering quadruplets, with comprehensive historical and conceptual insights. Both reviews emphasize ribosomal flexibility in accommodating backbone modifications, though incorporation remains limited to amino acids that can be loaded onto tRNAs via ribozymes or aaRSs. The introduction of novel codon sizes requires further modification and fine-tuning of translational mechanisms. Ward et al. provide an excellent overview of the development of tRNA-based therapies, noting that humans have over 600 tRNA genes. Certain mutant tRNAs can cause translation errors leading to diseases such as neurodegenerative disorders, cancer, and rare genetic conditions. Missense suppressor tRNAs insert incorrect amino acids, while nonsense suppressor tRNAs read through premature stop signals to produce full-length proteins. These mechanisms offer a basis for therapy, where “correct” tRNA variants can be used to correct genetic defects. Ward et al. also discuss the mechanisms of tRNA-based therapies, therapeutic windows for suppressing mutations, wild-type tRNA supplementation, and the challenges and opportunities of delivering tRNAs as synthetic RNAs or gene therapies. The expansion of the genetic code in animal cells and organisms is extensively and greatly detailed by Kim et al., further emphasizing therapeutic and general biotechnological potentials when ncAAs are included in this grand scheme. Finally, the importance of the in vitro platform for pharmaceutical molecule production is brought into focus in the review of Kubick et al., emphasizing cell-free protein synthesis (CFPS) for the incorporation of ncAAs in producing complex biologics such as antibody-drug conjugates (ADCs) and biosynthetic pathways for therapeutic molecules. Dunkelmann and Chin and Koch and Budisa reviewed key advancements in pyrrolysyl-tRNA synthetase (PylRS), a powerful enzyme for incorporating various amino acids into proteins. The PylRS:tRNAPyl pair, with its CUA anticodon, is an effective tool for orthogonal translation systems (OTS) in in-frame stop codon suppression (SCS) and site-specific ncAA incorporation. Particularly noteworthy is the strategy of orthogonal translation optimization based on aaRSs from psychrophilic sources, in contrast to the currently predominant use of enzymes from thermopiles. Similarly, Niu and Guo provided a comprehensive survey of orthogonalized protein translation in cells and organisms, addressing associated challenges. Together, these reviews summarize two decades of progress, including strategies for engineering orthogonal pairs, noncanonical monomers, quadruplets, codon size issues, and metabolic engineering. Central to all these efforts are the selection procedures for identifying and isolating molecular machines capable of incorporating ncAA. This is done by generating gene libraries of selected aaRSs using high-throughput screening techniques, which are covered in detail in the review by Lino et al. and also include genome engineering, adaptive evolution and the design of whole-cell chassis with alternative genetic codes. Recently, several groups have successfully demonstrated the use of phage-presented peptide libraries to achieve further diversification of ncAAs usage, far beyond the classical approaches, as presented by Hampton and Liu. Huang et al. have excellently addressed many often-overlooked aspects in the field, including enzyme chimeras and mutually orthogonal aaRS/tRNA pairs, engineering of tRNA transcription and tRNA chimeric variants and post-transcriptional modifications to improve orthogonal translation. Furthermore, the critical role of incorporating Nonsense-Mediated Decay (NMD) pathways in engineering efforts, and advanced screening methods such as PANCE (Phage-Assisted Non-Continuous Evolution), PACE (Phage-Assisted Continuous Evolution), and PRANCE (Phage- and Robotics-Assisted Near-Continuous Evolution) were discussed as well. Orthogonal machinery for ncAA incorporation often involves gene libraries of specific aminoacyl-tRNA synthetases. Two key systems, the tyrosine pair from Methanocaldococcus jannaschii (MjTyrRS:tRNATyr) and the pyrrolysine pair from Methanosarcina species (PylRS:tRNAPyl), were developed for OTS selection in Escherichia coli and other microbial and animal cells. (10) Jann et al. impressively reviewed engineering challenges and applications of nearly 500 ncAAs. MjTyrRS-based pairs generally outperform PylRS systems in yield and efficiency and are better suited for suppressing multiple stop codons. PylRS-based systems, however, show lower catalytic efficiency and protein yields. It should be noted that E. Lemke and his team have pioneered the use of phase-separated biomolecular condensates to create synthetic organelles in cells with their “own” orthogonal translation, (11) which is a significant advance in the field as a whole. Chemla et al. highlighted the transformative potential of ncAAs in bioelectrochemistry (e.g., fuel cells, biobatteries) and materials science (e.g., smart biomaterials, therapeutic proteins, engineered fibers), providing a valuable resource on biomaterials and bioelectrochemistry enabled by orthogonal translation. Biocatalysis with ncAAs is an emerging field with significant potential for expansion, offering opportunities to influence enzymatic reactions, create novel active sites, and catalyze new-to-nature reactions, as highlighted by Green et al. and Drienovská, Roelfes, et al. The use of photocaged and photoswitchable ncAAs for optical control of protein activity as well as spatiotemporal regulation of biological function should enable optogenetics with atomic precision as elaborated by Deiters et al. Infield et al. described the use of ncAAs in channels for mechanistic studies involving photochemistry (e.g., cross-linking and caged amino acids) and atomic mutagenesis (isosteric manipulation of charge, aromaticity, and backbone mutation), as well as fluorescent ncAAs for real-time studies. Feng et al. provided a very useful overview of biological spectroscopy and microscopy with a focus on ncAAs that can be inserted at predetermined positions as site-specific vibrational, fluorescent, electron paramagnetic resonance (EPR), or nuclear magnetic resonance (NMR) probes. Yi et al. also provided a detailed account of the usefulness of ncAAs as valuable spectroscopic and biophysical probes in cellular, organismal, and in vitro settings, highlighting developments over the past two decades. De Faveri et al. provided an insightful historical account and overview of current developments, highlighting the challenges of using ncAAs in membrane proteins, particularly in mammalian cell culture systems for functional expression. Their work emphasizes the need for engineering orthogonal pairs for efficient use in eukaryotes and to employ mild bioorthogonal reactions such as “click” chemistry to attach probes to membrane proteins in live cells, thus allowing the study of protein structure and dynamics in situ. The major challenge of bioorthogonal reactions is their bimolecular nature, which often results in inefficiency. Cao and Wang highlighted latent bioreactive ncAAs that enable selective covalent bonding through proximity-activated reactivity and offer numerous applications, including capturing transient interactions, modifying protein properties, and developing therapeutic agents such as covalent peptides and site-specifically labeled antibody conjugates. The use of noncanonical amino acids as “tags” inserted at predetermined positions is a highly compelling approach to mimic or introduce new post-translational modifications (PTMs). Gan and Fan’s review highlights the use of orthogonal translation to create novel, low-stoichiometry PTM sites on proteins without disrupting local microenvironments, enabling precise functional studies. Allen et al. describe the use of ncAAs, including phosphoserine, phosphothreonine, phosphotyrosine, and their mimics, to study reversible phosphorylation─a key mechanism for regulating protein function─by directly incorporating phosphoamino acids during orthogonal translation, eliminating the need for kinase-based or chemical synthesis methods. Finally, ubiquitylation, one of the most diverse PTMs essential for eukaryotic biology, has been systematically explored using ncAAs, as excellently demonstrated by Lang et al. Orthogonal translation enables synthetic, noninvasive, site-specific ubiquitylation─a crucial step toward unraveling the complexity of the ubiquitin code, its biological context, and relevant applications. This special issue shows how orthogonal translation with the incorporation of noncanonical amino acids into proteins by expanding or substituting the genetic code repertoire has reached a level of intellectual maturity that enables the transition of the entire field from purely academic research to an industrially relevant discipline and technology. A primary challenge in genetic code expansion via translation readthrough of in-frame stop codons is the limited availability of triplet codons for permanent reassignment as well as the metabolic availability of the desired ncAAs. This limitation can be addressed by strategies such as sense codon reassignment, as it is estimated that 30 to 40 sense codons are sufficient to encode an organism’s genetic information, leaving over 20 sense codons available for recoding with ncAAs. (12) Reprogramming protein translation with noncanonical amino acids allows us to reinterpret the original genetic message and effectively alter the “universal” genetic code─the fundamental language of life on Earth. This area of research pushes the boundaries of chemical composition and biochemical principles of life and contributes to our understanding of the origins of life. It also paves the way for the creation of synthetic life with alternative genetic codes and enables the development of novel biobased and bioinspired technologies for the benefit of society. Nediljko Budisa was born in 1966 and studied biology, chemistry, molecular biology and molecular biophysics at the University of Zagreb in Croatia. He completed his PhD in 1997 and then worked as a postdoc at the Max Planck Institute of Biochemistry (MPIB) in Martinsried, Germany, from 1997 to 2000. From 2001 to 2005, he habilitated in Biochemistry at the Technical University of Munich, and from 2005 to 2010, he was an independent group leader at the MPIB in the field of “Molecular Biotechnology”. In May 2010, he was appointed W3 Professor of Biocatalysis at the Technical University of Berlin, Institute of Chemistry. Since 2018, he has been Professor of Chemistry and holds the Tier-1 Canada Research Chair (CRC) in Chemical Synthetic Biology and Xenobiology at the University of Manitoba in Winnipeg, Canada. A pioneer in the field of genetic code engineering, he has significantly advanced the cotranslational incorporation of noncanonical amino acids into proteins. In addition to focusing on life engineering by modifying its chemical makeup, his work investigates the evolution and reprogramming of the genetic code with the aim of transforming the entire field from an academic discipline into a useful technology for healthcare and industry. aminoacyl-tRNA synthetase noncanonical amino acid orthogonal translation system posttranslational modifications Stop Codon Suppression transfer Ribo Nucleic Acid This article references 12 other publications. This article has not yet been cited by other publications.
期刊介绍:
Chemical Reviews is a highly regarded and highest-ranked journal covering the general topic of chemistry. Its mission is to provide comprehensive, authoritative, critical, and readable reviews of important recent research in organic, inorganic, physical, analytical, theoretical, and biological chemistry.
Since 1985, Chemical Reviews has also published periodic thematic issues that focus on a single theme or direction of emerging research.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
