Na Li, Kiarash Riazi, Jie Pan, Kednapa Thavorn, Jennifer Ziegler, Bram Rochwerg, Hude Quan, Hallie C Prescott, Peter M Dodek, Bing Li, Alain Gervais, Allan Garland
{"title":"Unsupervised clustering for sepsis identification in large-scale patient data: a model development and validation study.","authors":"Na Li, Kiarash Riazi, Jie Pan, Kednapa Thavorn, Jennifer Ziegler, Bram Rochwerg, Hude Quan, Hallie C Prescott, Peter M Dodek, Bing Li, Alain Gervais, Allan Garland","doi":"10.1186/s40635-025-00744-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Sepsis is a major global health problem. However, it lacks a true reference standard for case identification, complicating epidemiologic surveillance. Consensus definitions have changed multiple times, clinicians struggle to identify sepsis at the bedside, and differing identification algorithms generate wide variation in incidence rates. The two current identification approaches use codes from administrative data, or electronic health record (EHR)-based algorithms such as the Center for Disease Control Adult Sepsis Event (ASE); both have limitations. Here our primary purpose is to report initial steps in developing a novel approach to identifying sepsis using unsupervised clustering methods. Secondarily, we report preliminary analysis of resulting clusters, using identification by ASE criteria as a familiar comparator.</p><p><strong>Methods: </strong>This retrospective cohort study used hospital administrative and EHR data on adults admitted to intensive care units (ICUs) at five Canadian medical centres (2015-2017), with split development and validation cohorts. After preprocessing 592 variables (demographics, encounter characteristics, diagnoses, medications, laboratory tests, and clinical management) and applying data reduction, we presented 55 principal components to eight different clustering algorithms. An automated elbow method determined the optimal number of clusters, and the optimal algorithm was selected based on clustering metrics for consistency, separation, distribution and stability. Cluster membership in the validation cohort was assigned using an XGBoost model trained to predict cluster membership in the development cohort. For cluster analysis, we prospectively subdivided clusters by their fractions meeting ASE criteria (≥ 50% ASE-majority clusters vs. ASE-minority clusters), and compared their characteristics.</p><p><strong>Results: </strong>There were 3660 patients in the development cohort and 3012 in the validation cohort, of which 21.5% (development) and 19.1% (validation) were ASE (+). The Robust and Sparse K-means Clustering (RSKC) method performed best. In the development cohort, it identified 48 clusters of hospitalizations; 11 ASE-majority clusters contained 22.4% of all patients but 77.8% of all ASE (+) patients. 34.9% of the 209 ASE (-) patients in the ASE-majority clusters met more liberal ASE criteria for sepsis. Findings were consistent in the validation cohort.</p><p><strong>Conclusions: </strong>Unsupervised clustering applied to diverse, large-scale medical data offers a promising approach to the identification of sepsis phenotypes for epidemiological surveillance.</p>","PeriodicalId":13750,"journal":{"name":"Intensive Care Medicine Experimental","volume":"13 1","pages":"37"},"PeriodicalIF":2.8000,"publicationDate":"2025-03-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11925832/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Intensive Care Medicine Experimental","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s40635-025-00744-w","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CRITICAL CARE MEDICINE","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Sepsis is a major global health problem. However, it lacks a true reference standard for case identification, complicating epidemiologic surveillance. Consensus definitions have changed multiple times, clinicians struggle to identify sepsis at the bedside, and differing identification algorithms generate wide variation in incidence rates. The two current identification approaches use codes from administrative data, or electronic health record (EHR)-based algorithms such as the Center for Disease Control Adult Sepsis Event (ASE); both have limitations. Here our primary purpose is to report initial steps in developing a novel approach to identifying sepsis using unsupervised clustering methods. Secondarily, we report preliminary analysis of resulting clusters, using identification by ASE criteria as a familiar comparator.
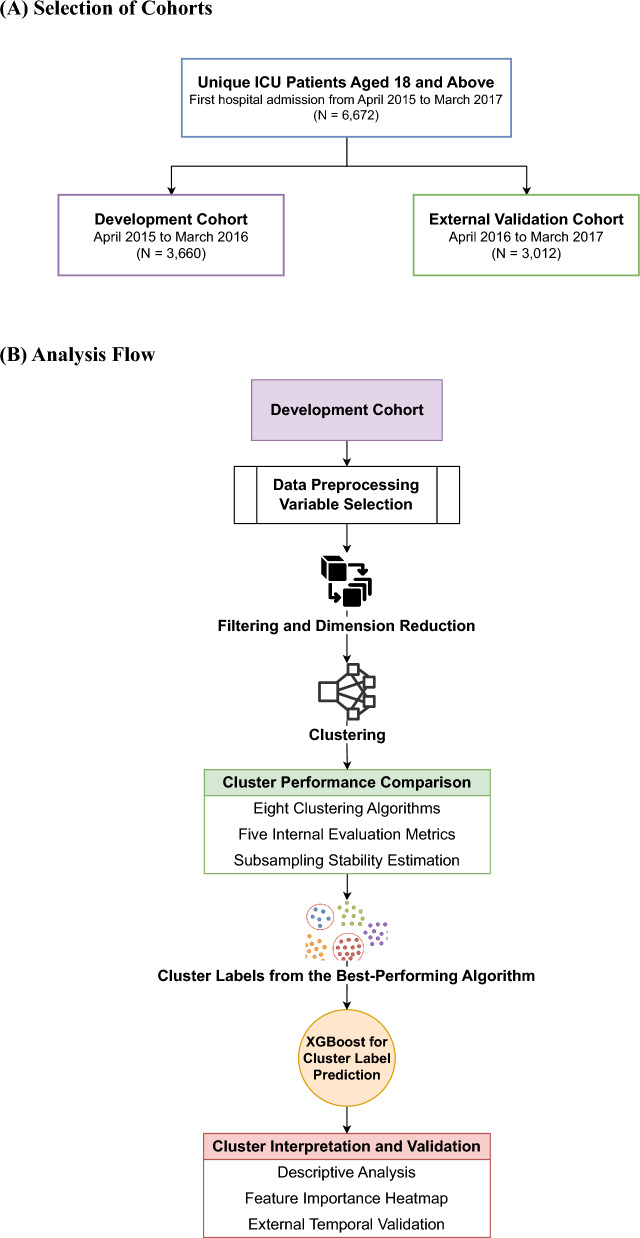
Methods: This retrospective cohort study used hospital administrative and EHR data on adults admitted to intensive care units (ICUs) at five Canadian medical centres (2015-2017), with split development and validation cohorts. After preprocessing 592 variables (demographics, encounter characteristics, diagnoses, medications, laboratory tests, and clinical management) and applying data reduction, we presented 55 principal components to eight different clustering algorithms. An automated elbow method determined the optimal number of clusters, and the optimal algorithm was selected based on clustering metrics for consistency, separation, distribution and stability. Cluster membership in the validation cohort was assigned using an XGBoost model trained to predict cluster membership in the development cohort. For cluster analysis, we prospectively subdivided clusters by their fractions meeting ASE criteria (≥ 50% ASE-majority clusters vs. ASE-minority clusters), and compared their characteristics.
Results: There were 3660 patients in the development cohort and 3012 in the validation cohort, of which 21.5% (development) and 19.1% (validation) were ASE (+). The Robust and Sparse K-means Clustering (RSKC) method performed best. In the development cohort, it identified 48 clusters of hospitalizations; 11 ASE-majority clusters contained 22.4% of all patients but 77.8% of all ASE (+) patients. 34.9% of the 209 ASE (-) patients in the ASE-majority clusters met more liberal ASE criteria for sepsis. Findings were consistent in the validation cohort.
Conclusions: Unsupervised clustering applied to diverse, large-scale medical data offers a promising approach to the identification of sepsis phenotypes for epidemiological surveillance.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
