Artuur M Leeuwenberg, Maarten van Smeden, Johannes A Langendijk, Arjen van der Schaaf, Murielle E Mauer, Karel G M Moons, Johannes B Reitsma, Ewoud Schuit
{"title":"Performance of binary prediction models in high-correlation low-dimensional settings: a comparison of methods.","authors":"Artuur M Leeuwenberg, Maarten van Smeden, Johannes A Langendijk, Arjen van der Schaaf, Murielle E Mauer, Karel G M Moons, Johannes B Reitsma, Ewoud Schuit","doi":"10.1186/s41512-021-00115-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Clinical prediction models are developed widely across medical disciplines. When predictors in such models are highly collinear, unexpected or spurious predictor-outcome associations may occur, thereby potentially reducing face-validity of the prediction model. Collinearity can be dealt with by exclusion of collinear predictors, but when there is no a priori motivation (besides collinearity) to include or exclude specific predictors, such an approach is arbitrary and possibly inappropriate.</p><p><strong>Methods: </strong>We compare different methods to address collinearity, including shrinkage, dimensionality reduction, and constrained optimization. The effectiveness of these methods is illustrated via simulations.</p><p><strong>Results: </strong>In the conducted simulations, no effect of collinearity was observed on predictive outcomes (AUC, R<sup>2</sup>, Intercept, Slope) across methods. However, a negative effect of collinearity on the stability of predictor selection was found, affecting all compared methods, but in particular methods that perform strong predictor selection (e.g., Lasso). Methods for which the included set of predictors remained most stable under increased collinearity were Ridge, PCLR, LAELR, and Dropout.</p><p><strong>Conclusions: </strong>Based on the results, we would recommend refraining from data-driven predictor selection approaches in the presence of high collinearity, because of the increased instability of predictor selection, even in relatively high events-per-variable settings. The selection of certain predictors over others may disproportionally give the impression that included predictors have a stronger association with the outcome than excluded predictors.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":" ","pages":"1"},"PeriodicalIF":2.6000,"publicationDate":"2022-01-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8751246/pdf/","citationCount":"10","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-021-00115-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 10
Abstract
Background: Clinical prediction models are developed widely across medical disciplines. When predictors in such models are highly collinear, unexpected or spurious predictor-outcome associations may occur, thereby potentially reducing face-validity of the prediction model. Collinearity can be dealt with by exclusion of collinear predictors, but when there is no a priori motivation (besides collinearity) to include or exclude specific predictors, such an approach is arbitrary and possibly inappropriate.
Methods: We compare different methods to address collinearity, including shrinkage, dimensionality reduction, and constrained optimization. The effectiveness of these methods is illustrated via simulations.
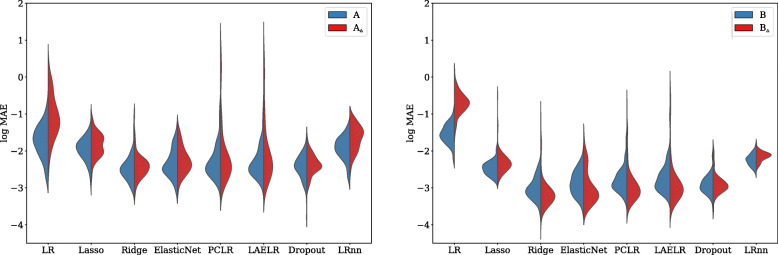
Results: In the conducted simulations, no effect of collinearity was observed on predictive outcomes (AUC, R2, Intercept, Slope) across methods. However, a negative effect of collinearity on the stability of predictor selection was found, affecting all compared methods, but in particular methods that perform strong predictor selection (e.g., Lasso). Methods for which the included set of predictors remained most stable under increased collinearity were Ridge, PCLR, LAELR, and Dropout.
Conclusions: Based on the results, we would recommend refraining from data-driven predictor selection approaches in the presence of high collinearity, because of the increased instability of predictor selection, even in relatively high events-per-variable settings. The selection of certain predictors over others may disproportionally give the impression that included predictors have a stronger association with the outcome than excluded predictors.




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
