Raj Kumar, Manoj Tripathy, R. S. Anand, Niraj Kumar
{"title":"基于残差卷积神经网络的聋哑语音识别","authors":"Raj Kumar, Manoj Tripathy, R. S. Anand, Niraj Kumar","doi":"10.1007/s13369-024-08919-5","DOIUrl":null,"url":null,"abstract":"<div><p>People with dysarthric speech face problems communicating with others and voice-based smart devices. This paper presents the development of a spatial residual convolutional neural network (RCNN)-based dysarthric speech recognition (DSR) system to improve communication for individuals with dysarthric speech. The RCNN model is simplified to an optimal number of layers. The system utilizes a speaker-adaptive approach, incorporating transfer learning to leverage knowledge learned from healthy individuals and a new data augmentation technique to address voice hoarseness in patients. The dysarthric speech is preprocessed using a novel voice cropping technique based on erosion and dilation methods to eliminate unnecessary pauses and hiccups in the time domain. The isolated word recognition accuracy improved by nearly 8.16% for patients with very low intelligibility and 4.74% for patients with low intelligibility speech compared to previously reported results. The proposed DSR system gives the lowest word error rate of 24.09% on the UASpeech dysarthric speech datasets of 15 dysarthric speakers.</p></div>","PeriodicalId":54354,"journal":{"name":"Arabian Journal for Science and Engineering","volume":"49 12","pages":"16241 - 16251"},"PeriodicalIF":2.9000,"publicationDate":"2024-03-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Residual Convolutional Neural Network-Based Dysarthric Speech Recognition\",\"authors\":\"Raj Kumar, Manoj Tripathy, R. S. Anand, Niraj Kumar\",\"doi\":\"10.1007/s13369-024-08919-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>People with dysarthric speech face problems communicating with others and voice-based smart devices. This paper presents the development of a spatial residual convolutional neural network (RCNN)-based dysarthric speech recognition (DSR) system to improve communication for individuals with dysarthric speech. The RCNN model is simplified to an optimal number of layers. The system utilizes a speaker-adaptive approach, incorporating transfer learning to leverage knowledge learned from healthy individuals and a new data augmentation technique to address voice hoarseness in patients. The dysarthric speech is preprocessed using a novel voice cropping technique based on erosion and dilation methods to eliminate unnecessary pauses and hiccups in the time domain. The isolated word recognition accuracy improved by nearly 8.16% for patients with very low intelligibility and 4.74% for patients with low intelligibility speech compared to previously reported results. The proposed DSR system gives the lowest word error rate of 24.09% on the UASpeech dysarthric speech datasets of 15 dysarthric speakers.</p></div>\",\"PeriodicalId\":54354,\"journal\":{\"name\":\"Arabian Journal for Science and Engineering\",\"volume\":\"49 12\",\"pages\":\"16241 - 16251\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2024-03-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Arabian Journal for Science and Engineering\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s13369-024-08919-5\",\"RegionNum\":4,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Arabian Journal for Science and Engineering","FirstCategoryId":"103","ListUrlMain":"https://link.springer.com/article/10.1007/s13369-024-08919-5","RegionNum":4,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
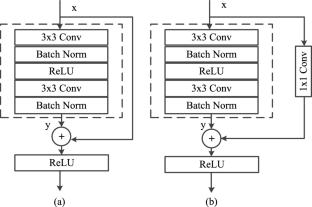
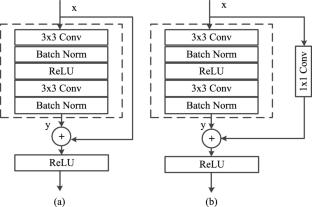
People with dysarthric speech face problems communicating with others and voice-based smart devices. This paper presents the development of a spatial residual convolutional neural network (RCNN)-based dysarthric speech recognition (DSR) system to improve communication for individuals with dysarthric speech. The RCNN model is simplified to an optimal number of layers. The system utilizes a speaker-adaptive approach, incorporating transfer learning to leverage knowledge learned from healthy individuals and a new data augmentation technique to address voice hoarseness in patients. The dysarthric speech is preprocessed using a novel voice cropping technique based on erosion and dilation methods to eliminate unnecessary pauses and hiccups in the time domain. The isolated word recognition accuracy improved by nearly 8.16% for patients with very low intelligibility and 4.74% for patients with low intelligibility speech compared to previously reported results. The proposed DSR system gives the lowest word error rate of 24.09% on the UASpeech dysarthric speech datasets of 15 dysarthric speakers.
期刊介绍:
King Fahd University of Petroleum & Minerals (KFUPM) partnered with Springer to publish the Arabian Journal for Science and Engineering (AJSE).
AJSE, which has been published by KFUPM since 1975, is a recognized national, regional and international journal that provides a great opportunity for the dissemination of research advances from the Kingdom of Saudi Arabia, MENA and the world.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
