{"title":"PMTPred:基于机器学习的蛋白质甲基转移酶预测,使用 k 距氨基酸对的组成。","authors":"Arvind Kumar Yadav, Pradeep Kumar Gupta, Tiratha Raj Singh","doi":"10.1007/s11030-024-10937-2","DOIUrl":null,"url":null,"abstract":"<div><p>Protein methyltransferases (PMTs) are a group of enzymes that help catalyze the transfer of a methyl group to its substrates. These enzymes play an important role in epigenetic regulation and can methylate various substrates with DNA, RNA, protein, and small-molecule secondary metabolites. Dysregulation of methyltransferases is implicated in various human cancers. However, in light of the well-recognized significance of PMTs, reliable and efficient identification methods are essential. In the present work, we propose a machine-learning-based method for the identification of PMTs. Various sequence-based features were calculated, and prediction models were trained using various machine-learning algorithms using a tenfold cross-validation technique. After evaluating each model on the dataset, the SVM-based CKSAAP model achieved the highest prediction accuracy with balanced sensitivity and specificity. Also, this SVM model outperformed deep-learning algorithms for the prediction of PMTs. In addition, cross-database validation was performed to ensure the robustness of the model. Feature importance was assessed using shapley additive explanations (SHAP) values, providing insights into the contributions of different features to the model’s predictions. Finally, the SVM-based CKSAAP model was implemented in a standalone tool, PMTPred, due to its consistent performance during independent testing and cross-database evaluation. We believe that PMTPred will be a useful and efficient tool for the identification of PMTs. The PMTPred is freely available for download at https://github.com/ArvindYadav7/PMTPred and http://www.bioinfoindia.org/PMTPred/home.html for research and academic use.</p><h3>Graphical abstract</h3><div><figure><div><div><picture><source><img></source></picture></div></div></figure></div></div>","PeriodicalId":708,"journal":{"name":"Molecular Diversity","volume":"28 4","pages":"2301 - 2315"},"PeriodicalIF":3.8000,"publicationDate":"2024-07-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"PMTPred: machine-learning-based prediction of protein methyltransferases using the composition of k-spaced amino acid pairs\",\"authors\":\"Arvind Kumar Yadav, Pradeep Kumar Gupta, Tiratha Raj Singh\",\"doi\":\"10.1007/s11030-024-10937-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Protein methyltransferases (PMTs) are a group of enzymes that help catalyze the transfer of a methyl group to its substrates. These enzymes play an important role in epigenetic regulation and can methylate various substrates with DNA, RNA, protein, and small-molecule secondary metabolites. Dysregulation of methyltransferases is implicated in various human cancers. However, in light of the well-recognized significance of PMTs, reliable and efficient identification methods are essential. In the present work, we propose a machine-learning-based method for the identification of PMTs. Various sequence-based features were calculated, and prediction models were trained using various machine-learning algorithms using a tenfold cross-validation technique. After evaluating each model on the dataset, the SVM-based CKSAAP model achieved the highest prediction accuracy with balanced sensitivity and specificity. Also, this SVM model outperformed deep-learning algorithms for the prediction of PMTs. In addition, cross-database validation was performed to ensure the robustness of the model. Feature importance was assessed using shapley additive explanations (SHAP) values, providing insights into the contributions of different features to the model’s predictions. Finally, the SVM-based CKSAAP model was implemented in a standalone tool, PMTPred, due to its consistent performance during independent testing and cross-database evaluation. We believe that PMTPred will be a useful and efficient tool for the identification of PMTs. The PMTPred is freely available for download at https://github.com/ArvindYadav7/PMTPred and http://www.bioinfoindia.org/PMTPred/home.html for research and academic use.</p><h3>Graphical abstract</h3><div><figure><div><div><picture><source><img></source></picture></div></div></figure></div></div>\",\"PeriodicalId\":708,\"journal\":{\"name\":\"Molecular Diversity\",\"volume\":\"28 4\",\"pages\":\"2301 - 2315\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2024-07-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular Diversity\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11030-024-10937-2\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"CHEMISTRY, APPLIED\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Diversity","FirstCategoryId":"92","ListUrlMain":"https://link.springer.com/article/10.1007/s11030-024-10937-2","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, APPLIED","Score":null,"Total":0}
PMTPred: machine-learning-based prediction of protein methyltransferases using the composition of k-spaced amino acid pairs
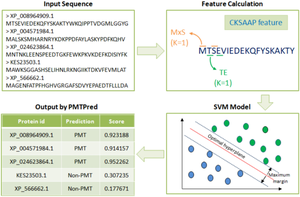
Protein methyltransferases (PMTs) are a group of enzymes that help catalyze the transfer of a methyl group to its substrates. These enzymes play an important role in epigenetic regulation and can methylate various substrates with DNA, RNA, protein, and small-molecule secondary metabolites. Dysregulation of methyltransferases is implicated in various human cancers. However, in light of the well-recognized significance of PMTs, reliable and efficient identification methods are essential. In the present work, we propose a machine-learning-based method for the identification of PMTs. Various sequence-based features were calculated, and prediction models were trained using various machine-learning algorithms using a tenfold cross-validation technique. After evaluating each model on the dataset, the SVM-based CKSAAP model achieved the highest prediction accuracy with balanced sensitivity and specificity. Also, this SVM model outperformed deep-learning algorithms for the prediction of PMTs. In addition, cross-database validation was performed to ensure the robustness of the model. Feature importance was assessed using shapley additive explanations (SHAP) values, providing insights into the contributions of different features to the model’s predictions. Finally, the SVM-based CKSAAP model was implemented in a standalone tool, PMTPred, due to its consistent performance during independent testing and cross-database evaluation. We believe that PMTPred will be a useful and efficient tool for the identification of PMTs. The PMTPred is freely available for download at https://github.com/ArvindYadav7/PMTPred and http://www.bioinfoindia.org/PMTPred/home.html for research and academic use.
期刊介绍:
Molecular Diversity is a new publication forum for the rapid publication of refereed papers dedicated to describing the development, application and theory of molecular diversity and combinatorial chemistry in basic and applied research and drug discovery. The journal publishes both short and full papers, perspectives, news and reviews dealing with all aspects of the generation of molecular diversity, application of diversity for screening against alternative targets of all types (biological, biophysical, technological), analysis of results obtained and their application in various scientific disciplines/approaches including:
combinatorial chemistry and parallel synthesis;
small molecule libraries;
microwave synthesis;
flow synthesis;
fluorous synthesis;
diversity oriented synthesis (DOS);
nanoreactors;
click chemistry;
multiplex technologies;
fragment- and ligand-based design;
structure/function/SAR;
computational chemistry and molecular design;
chemoinformatics;
screening techniques and screening interfaces;
analytical and purification methods;
robotics, automation and miniaturization;
targeted libraries;
display libraries;
peptides and peptoids;
proteins;
oligonucleotides;
carbohydrates;
natural diversity;
new methods of library formulation and deconvolution;
directed evolution, origin of life and recombination;
search techniques, landscapes, random chemistry and more;




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
