{"title":"利用集合学习与特征工程的混合方法,建立由时间序列定义的产品类别需求预测系统","authors":"Santiago Mejía, Jose Aguilar","doi":"10.1007/s00607-024-01320-y","DOIUrl":null,"url":null,"abstract":"<p>Retail companies face major problems in the estimation of their product’s future demand due to the high diversity of sales behavior that each good presents. Different forecasting models are implemented to meet the demand requirements for efficient inventory management. However, in most of the proposed works, a single model approach is applied to forecast all products, ignoring that some methods are better adapted for certain features of the demand time series of each product. The proposed forecasting system addresses this problem, by implementing a two-phase methodology that initially clusters the products with the application of an unsupervised learning approach using the extracted demand features of each good, and then, implements a second phase where, after a feature engineering process, a set of different forecasting methods are evaluated to identify those with best performs for each cluster. Finally, ensemble machine learning models are implemented using the top-performing models of each cluster to carry out the demand estimation. The results indicate that the proposed forecasting system improves the demand estimation over the single forecasting approaches when evaluating the R<sup>2</sup>, MSE, and MASE quality measures.</p>","PeriodicalId":10718,"journal":{"name":"Computing","volume":"99 1","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A demand forecasting system of product categories defined by their time series using a hybrid approach of ensemble learning with feature engineering\",\"authors\":\"Santiago Mejía, Jose Aguilar\",\"doi\":\"10.1007/s00607-024-01320-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Retail companies face major problems in the estimation of their product’s future demand due to the high diversity of sales behavior that each good presents. Different forecasting models are implemented to meet the demand requirements for efficient inventory management. However, in most of the proposed works, a single model approach is applied to forecast all products, ignoring that some methods are better adapted for certain features of the demand time series of each product. The proposed forecasting system addresses this problem, by implementing a two-phase methodology that initially clusters the products with the application of an unsupervised learning approach using the extracted demand features of each good, and then, implements a second phase where, after a feature engineering process, a set of different forecasting methods are evaluated to identify those with best performs for each cluster. Finally, ensemble machine learning models are implemented using the top-performing models of each cluster to carry out the demand estimation. The results indicate that the proposed forecasting system improves the demand estimation over the single forecasting approaches when evaluating the R<sup>2</sup>, MSE, and MASE quality measures.</p>\",\"PeriodicalId\":10718,\"journal\":{\"name\":\"Computing\",\"volume\":\"99 1\",\"pages\":\"\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-09-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00607-024-01320-y\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00607-024-01320-y","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
摘要
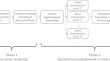
由于每种商品的销售行为千差万别,零售公司在估计其产品的未来需求时面临着重大问题。为了满足高效库存管理的需求要求,人们采用了不同的预测模型。然而,在大多数提议的工作中,都是采用单一模型方法来预测所有产品,而忽略了有些方法更适合每种产品需求时间序列的某些特征。为解决这一问题,所提出的预测系统分为两个阶段:首先,采用无监督学习方法,利用提取的每种商品的需求特征对产品进行聚类;然后,实施第二阶段,在特征工程流程之后,对一系列不同的预测方法进行评估,以确定哪些方法在每个聚类中表现最佳。最后,使用每个群组中表现最好的模型来实施集合机器学习模型,以进行需求预测。结果表明,在评估 R2、MSE 和 MASE 质量指标时,与单一预测方法相比,建议的预测系统提高了需求预测效果。
A demand forecasting system of product categories defined by their time series using a hybrid approach of ensemble learning with feature engineering
Retail companies face major problems in the estimation of their product’s future demand due to the high diversity of sales behavior that each good presents. Different forecasting models are implemented to meet the demand requirements for efficient inventory management. However, in most of the proposed works, a single model approach is applied to forecast all products, ignoring that some methods are better adapted for certain features of the demand time series of each product. The proposed forecasting system addresses this problem, by implementing a two-phase methodology that initially clusters the products with the application of an unsupervised learning approach using the extracted demand features of each good, and then, implements a second phase where, after a feature engineering process, a set of different forecasting methods are evaluated to identify those with best performs for each cluster. Finally, ensemble machine learning models are implemented using the top-performing models of each cluster to carry out the demand estimation. The results indicate that the proposed forecasting system improves the demand estimation over the single forecasting approaches when evaluating the R2, MSE, and MASE quality measures.
期刊介绍:
Computing publishes original papers, short communications and surveys on all fields of computing. The contributions should be written in English and may be of theoretical or applied nature, the essential criteria are computational relevance and systematic foundation of results.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
