Jenna L Ballard, Zexuan Wang, Wenrui Li, Li Shen, Qi Long
{"title":"基于深度学习的多组学数据整合与分析方法。","authors":"Jenna L Ballard, Zexuan Wang, Wenrui Li, Li Shen, Qi Long","doi":"10.1186/s13040-024-00391-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The rapid growth of deep learning, as well as the vast and ever-growing amount of available data, have provided ample opportunity for advances in fusion and analysis of complex and heterogeneous data types. Different data modalities provide complementary information that can be leveraged to gain a more complete understanding of each subject. In the biomedical domain, multi-omics data includes molecular (genomics, transcriptomics, proteomics, epigenomics, metabolomics, etc.) and imaging (radiomics, pathomics) modalities which, when combined, have the potential to improve performance on prediction, classification, clustering and other tasks. Deep learning encompasses a wide variety of methods, each of which have certain strengths and weaknesses for multi-omics integration.</p><p><strong>Method: </strong>In this review, we categorize recent deep learning-based approaches by their basic architectures and discuss their unique capabilities in relation to one another. We also discuss some emerging themes advancing the field of multi-omics integration.</p><p><strong>Results: </strong>Deep learning-based multi-omics integration methods were categorized broadly into non-generative (feedforward neural networks, graph convolutional neural networks, and autoencoders) and generative (variational methods, generative adversarial models, and a generative pretrained model). Generative methods have the advantage of being able to impose constraints on the shared representations to enforce certain properties or incorporate prior knowledge. They can also be used to generate or impute missing modalities. Recent advances achieved by these methods include the ability to handle incomplete data as well as going beyond the traditional molecular omics data types to integrate other modalities such as imaging data.</p><p><strong>Conclusion: </strong>We expect to see further growth in methods that can handle missingness, as this is a common challenge in working with complex and heterogeneous data. Additionally, methods that integrate more data types are expected to improve performance on downstream tasks by capturing a comprehensive view of each sample.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"38"},"PeriodicalIF":6.1000,"publicationDate":"2024-10-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11446004/pdf/","citationCount":"0","resultStr":"{\"title\":\"Deep learning-based approaches for multi-omics data integration and analysis.\",\"authors\":\"Jenna L Ballard, Zexuan Wang, Wenrui Li, Li Shen, Qi Long\",\"doi\":\"10.1186/s13040-024-00391-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The rapid growth of deep learning, as well as the vast and ever-growing amount of available data, have provided ample opportunity for advances in fusion and analysis of complex and heterogeneous data types. Different data modalities provide complementary information that can be leveraged to gain a more complete understanding of each subject. In the biomedical domain, multi-omics data includes molecular (genomics, transcriptomics, proteomics, epigenomics, metabolomics, etc.) and imaging (radiomics, pathomics) modalities which, when combined, have the potential to improve performance on prediction, classification, clustering and other tasks. Deep learning encompasses a wide variety of methods, each of which have certain strengths and weaknesses for multi-omics integration.</p><p><strong>Method: </strong>In this review, we categorize recent deep learning-based approaches by their basic architectures and discuss their unique capabilities in relation to one another. We also discuss some emerging themes advancing the field of multi-omics integration.</p><p><strong>Results: </strong>Deep learning-based multi-omics integration methods were categorized broadly into non-generative (feedforward neural networks, graph convolutional neural networks, and autoencoders) and generative (variational methods, generative adversarial models, and a generative pretrained model). Generative methods have the advantage of being able to impose constraints on the shared representations to enforce certain properties or incorporate prior knowledge. They can also be used to generate or impute missing modalities. Recent advances achieved by these methods include the ability to handle incomplete data as well as going beyond the traditional molecular omics data types to integrate other modalities such as imaging data.</p><p><strong>Conclusion: </strong>We expect to see further growth in methods that can handle missingness, as this is a common challenge in working with complex and heterogeneous data. Additionally, methods that integrate more data types are expected to improve performance on downstream tasks by capturing a comprehensive view of each sample.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"17 1\",\"pages\":\"38\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-10-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11446004/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-024-00391-z\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00391-z","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Deep learning-based approaches for multi-omics data integration and analysis.
Background: The rapid growth of deep learning, as well as the vast and ever-growing amount of available data, have provided ample opportunity for advances in fusion and analysis of complex and heterogeneous data types. Different data modalities provide complementary information that can be leveraged to gain a more complete understanding of each subject. In the biomedical domain, multi-omics data includes molecular (genomics, transcriptomics, proteomics, epigenomics, metabolomics, etc.) and imaging (radiomics, pathomics) modalities which, when combined, have the potential to improve performance on prediction, classification, clustering and other tasks. Deep learning encompasses a wide variety of methods, each of which have certain strengths and weaknesses for multi-omics integration.
Method: In this review, we categorize recent deep learning-based approaches by their basic architectures and discuss their unique capabilities in relation to one another. We also discuss some emerging themes advancing the field of multi-omics integration.
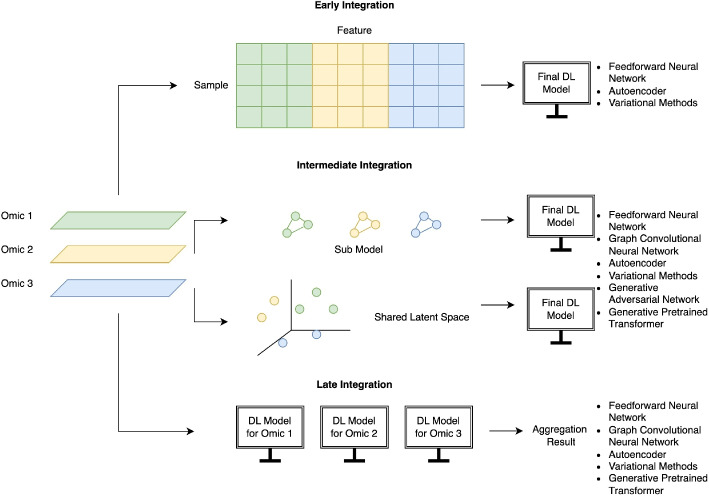
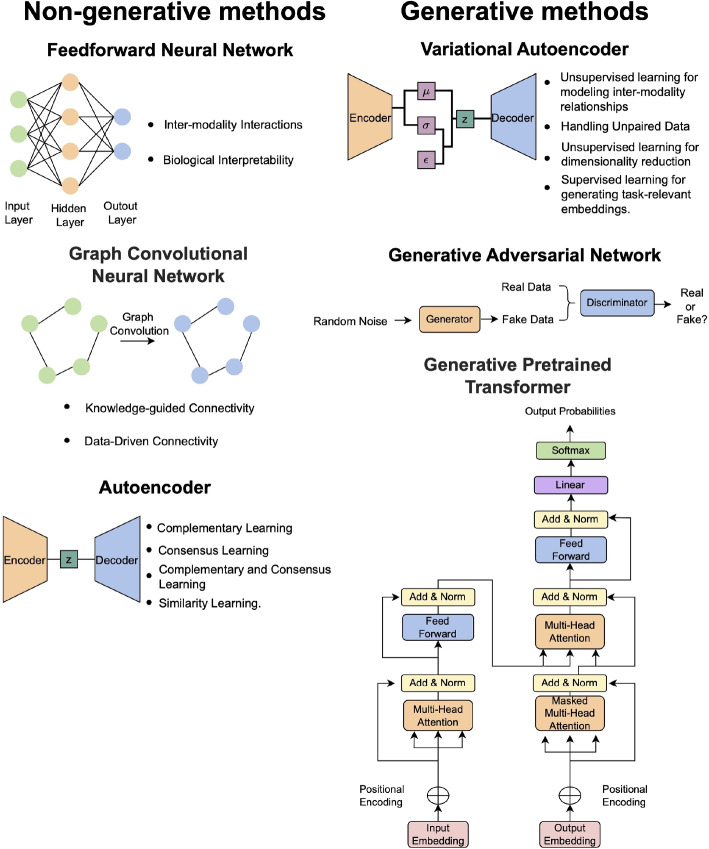
Results: Deep learning-based multi-omics integration methods were categorized broadly into non-generative (feedforward neural networks, graph convolutional neural networks, and autoencoders) and generative (variational methods, generative adversarial models, and a generative pretrained model). Generative methods have the advantage of being able to impose constraints on the shared representations to enforce certain properties or incorporate prior knowledge. They can also be used to generate or impute missing modalities. Recent advances achieved by these methods include the ability to handle incomplete data as well as going beyond the traditional molecular omics data types to integrate other modalities such as imaging data.
Conclusion: We expect to see further growth in methods that can handle missingness, as this is a common challenge in working with complex and heterogeneous data. Additionally, methods that integrate more data types are expected to improve performance on downstream tasks by capturing a comprehensive view of each sample.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
