Yi-Kai Zheng , Bi Zeng , Yi-Chun Feng , Lu Zhou , Yi-Xue Li
{"title":"PLRTE:使用大型语言模型进行生物医学关系三元组提取的渐进式学习。","authors":"Yi-Kai Zheng , Bi Zeng , Yi-Chun Feng , Lu Zhou , Yi-Xue Li","doi":"10.1016/j.jbi.2024.104738","DOIUrl":null,"url":null,"abstract":"<div><div>Document-level relation triplet extraction is crucial in biomedical text mining, aiding in drug discovery and the construction of biomedical knowledge graphs. Current language models face challenges in generalizing to unseen datasets and relation types in biomedical relation triplet extraction, which limits their effectiveness in these crucial tasks. To address this challenge, our study optimizes models from two critical dimensions: data-task relevance and granularity of relations, aiming to enhance their generalization capabilities significantly. We introduce a novel progressive learning strategy to obtain the PLRTE model. This strategy not only enhances the model’s capability to comprehend diverse relation types in the biomedical domain but also implements a structured four-level progressive learning process through semantic relation augmentation, compositional instruction, and dual-axis level learning. Our experiments on the DDI and BC5CDR document-level biomedical relation triplet datasets demonstrate a significant performance improvement of 5% to 20% over the current state-of-the-art baselines. Furthermore, our model exhibits exceptional generalization capabilities on the unseen Chemprot and GDA datasets, further validating the effectiveness of optimizing data-task association and relation granularity for enhancing model generalizability.</div></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"159 ","pages":"Article 104738"},"PeriodicalIF":4.5000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"PLRTE: Progressive learning for biomedical relation triplet extraction using large language models\",\"authors\":\"Yi-Kai Zheng , Bi Zeng , Yi-Chun Feng , Lu Zhou , Yi-Xue Li\",\"doi\":\"10.1016/j.jbi.2024.104738\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Document-level relation triplet extraction is crucial in biomedical text mining, aiding in drug discovery and the construction of biomedical knowledge graphs. Current language models face challenges in generalizing to unseen datasets and relation types in biomedical relation triplet extraction, which limits their effectiveness in these crucial tasks. To address this challenge, our study optimizes models from two critical dimensions: data-task relevance and granularity of relations, aiming to enhance their generalization capabilities significantly. We introduce a novel progressive learning strategy to obtain the PLRTE model. This strategy not only enhances the model’s capability to comprehend diverse relation types in the biomedical domain but also implements a structured four-level progressive learning process through semantic relation augmentation, compositional instruction, and dual-axis level learning. Our experiments on the DDI and BC5CDR document-level biomedical relation triplet datasets demonstrate a significant performance improvement of 5% to 20% over the current state-of-the-art baselines. Furthermore, our model exhibits exceptional generalization capabilities on the unseen Chemprot and GDA datasets, further validating the effectiveness of optimizing data-task association and relation granularity for enhancing model generalizability.</div></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"159 \",\"pages\":\"Article 104738\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001564\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/18 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001564","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/18 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
PLRTE: Progressive learning for biomedical relation triplet extraction using large language models
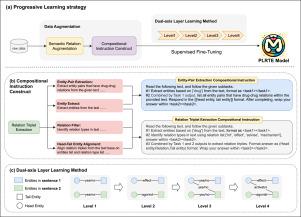
Document-level relation triplet extraction is crucial in biomedical text mining, aiding in drug discovery and the construction of biomedical knowledge graphs. Current language models face challenges in generalizing to unseen datasets and relation types in biomedical relation triplet extraction, which limits their effectiveness in these crucial tasks. To address this challenge, our study optimizes models from two critical dimensions: data-task relevance and granularity of relations, aiming to enhance their generalization capabilities significantly. We introduce a novel progressive learning strategy to obtain the PLRTE model. This strategy not only enhances the model’s capability to comprehend diverse relation types in the biomedical domain but also implements a structured four-level progressive learning process through semantic relation augmentation, compositional instruction, and dual-axis level learning. Our experiments on the DDI and BC5CDR document-level biomedical relation triplet datasets demonstrate a significant performance improvement of 5% to 20% over the current state-of-the-art baselines. Furthermore, our model exhibits exceptional generalization capabilities on the unseen Chemprot and GDA datasets, further validating the effectiveness of optimizing data-task association and relation granularity for enhancing model generalizability.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
