Gang Liu , Jinlong He , Pengfei Li , Zixu Zhao , Shenjun Zhong
{"title":"针对医学视觉问题解答的多目标跨模态自监督视觉语言预训练。","authors":"Gang Liu , Jinlong He , Pengfei Li , Zixu Zhao , Shenjun Zhong","doi":"10.1016/j.jbi.2024.104748","DOIUrl":null,"url":null,"abstract":"<div><div>Medical Visual Question Answering (VQA) is a task that aims to provide answers to questions about medical images, which utilizes both visual and textual information in the reasoning process. The absence of large-scale annotated medical VQA datasets presents a formidable obstacle to training a medical VQA model from scratch in an end-to-end manner. Existing works have been using image captioning dataset in the pre-training stage and fine-tuning to downstream VQA tasks. Following the same paradigm, we use a collection of public medical image captioning datasets to pre-train multimodality models in a self-supervised setup, and fine-tune to downstream medical VQA tasks. In the work, we propose a method that featured with Cross-Modal pre-training with Multiple Objectives (CMMO), which includes masked image modeling, masked language modeling, image-text matching, and image-text contrastive learning. The proposed method is designed to associate the visual features of medical images with corresponding medical concepts in captions, for learning aligned vision and language feature representations, and multi-modal interactions. The experimental results reveal that our proposed CMMO method outperforms state-of-the-art methods on three public medical VQA datasets, showing absolute improvements of 2.6%, 0.9%, and 4.0% on the VQA-RAD, PathVQA, and SLAKE dataset, respectively. We also conduct comprehensive ablation studies to validate our method, and visualize the attention maps which show a strong interpretability. The code and pre-trained weights will be released at <span><span>https://github.com/pengfeiliHEU/CMMO</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"160 ","pages":"Article 104748"},"PeriodicalIF":5.9000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Cross-Modal self-supervised vision language pre-training with multiple objectives for medical visual question answering\",\"authors\":\"Gang Liu , Jinlong He , Pengfei Li , Zixu Zhao , Shenjun Zhong\",\"doi\":\"10.1016/j.jbi.2024.104748\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Medical Visual Question Answering (VQA) is a task that aims to provide answers to questions about medical images, which utilizes both visual and textual information in the reasoning process. The absence of large-scale annotated medical VQA datasets presents a formidable obstacle to training a medical VQA model from scratch in an end-to-end manner. Existing works have been using image captioning dataset in the pre-training stage and fine-tuning to downstream VQA tasks. Following the same paradigm, we use a collection of public medical image captioning datasets to pre-train multimodality models in a self-supervised setup, and fine-tune to downstream medical VQA tasks. In the work, we propose a method that featured with Cross-Modal pre-training with Multiple Objectives (CMMO), which includes masked image modeling, masked language modeling, image-text matching, and image-text contrastive learning. The proposed method is designed to associate the visual features of medical images with corresponding medical concepts in captions, for learning aligned vision and language feature representations, and multi-modal interactions. The experimental results reveal that our proposed CMMO method outperforms state-of-the-art methods on three public medical VQA datasets, showing absolute improvements of 2.6%, 0.9%, and 4.0% on the VQA-RAD, PathVQA, and SLAKE dataset, respectively. We also conduct comprehensive ablation studies to validate our method, and visualize the attention maps which show a strong interpretability. The code and pre-trained weights will be released at <span><span>https://github.com/pengfeiliHEU/CMMO</span><svg><path></path></svg></span>.</div></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"160 \",\"pages\":\"Article 104748\"},\"PeriodicalIF\":5.9000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001667\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/12 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001667","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/12 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Cross-Modal self-supervised vision language pre-training with multiple objectives for medical visual question answering
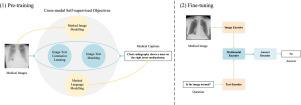
Medical Visual Question Answering (VQA) is a task that aims to provide answers to questions about medical images, which utilizes both visual and textual information in the reasoning process. The absence of large-scale annotated medical VQA datasets presents a formidable obstacle to training a medical VQA model from scratch in an end-to-end manner. Existing works have been using image captioning dataset in the pre-training stage and fine-tuning to downstream VQA tasks. Following the same paradigm, we use a collection of public medical image captioning datasets to pre-train multimodality models in a self-supervised setup, and fine-tune to downstream medical VQA tasks. In the work, we propose a method that featured with Cross-Modal pre-training with Multiple Objectives (CMMO), which includes masked image modeling, masked language modeling, image-text matching, and image-text contrastive learning. The proposed method is designed to associate the visual features of medical images with corresponding medical concepts in captions, for learning aligned vision and language feature representations, and multi-modal interactions. The experimental results reveal that our proposed CMMO method outperforms state-of-the-art methods on three public medical VQA datasets, showing absolute improvements of 2.6%, 0.9%, and 4.0% on the VQA-RAD, PathVQA, and SLAKE dataset, respectively. We also conduct comprehensive ablation studies to validate our method, and visualize the attention maps which show a strong interpretability. The code and pre-trained weights will be released at https://github.com/pengfeiliHEU/CMMO.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
