{"title":"基于加权融合和点向卷积的单眼图像深度估计方法","authors":"Chen Lei, Liang Zhengyou, Sun Yu","doi":"10.1049/cvi2.12212","DOIUrl":null,"url":null,"abstract":"<p>The existing monocular depth estimation methods based on deep learning have difficulty in estimating the depth near the edges of the objects in an image when the depth distance between these objects changes abruptly and decline in accuracy when an image has more noises. Furthermore, these methods consume more hardware resources because they have huge network parameters. To solve these problems, this paper proposes a depth estimation method based on weighted fusion and point-wise convolution. The authors design a maximum-average adaptive pooling weighted fusion module (MAWF) that fuses global features and local features and a continuous point-wise convolution module for processing the fused features derived from the (MAWF) module. The two modules work closely together for three times to perform weighted fusion and point-wise convolution of features of multi-scale from the encoder output, which can better decode the depth information of a scene. Experimental results show that our method achieves state-of-the-art performance on the KITTI dataset with <b><i>δ</i></b><sub>1</sub> up to 0.996 and the root mean square error metric down to 8% and has demonstrated the strong generalisation and robustness.</p>","PeriodicalId":56304,"journal":{"name":"IET Computer Vision","volume":"17 8","pages":"1005-1016"},"PeriodicalIF":1.5000,"publicationDate":"2023-06-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12212","citationCount":"0","resultStr":"{\"title\":\"A monocular image depth estimation method based on weighted fusion and point-wise convolution\",\"authors\":\"Chen Lei, Liang Zhengyou, Sun Yu\",\"doi\":\"10.1049/cvi2.12212\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The existing monocular depth estimation methods based on deep learning have difficulty in estimating the depth near the edges of the objects in an image when the depth distance between these objects changes abruptly and decline in accuracy when an image has more noises. Furthermore, these methods consume more hardware resources because they have huge network parameters. To solve these problems, this paper proposes a depth estimation method based on weighted fusion and point-wise convolution. The authors design a maximum-average adaptive pooling weighted fusion module (MAWF) that fuses global features and local features and a continuous point-wise convolution module for processing the fused features derived from the (MAWF) module. The two modules work closely together for three times to perform weighted fusion and point-wise convolution of features of multi-scale from the encoder output, which can better decode the depth information of a scene. Experimental results show that our method achieves state-of-the-art performance on the KITTI dataset with <b><i>δ</i></b><sub>1</sub> up to 0.996 and the root mean square error metric down to 8% and has demonstrated the strong generalisation and robustness.</p>\",\"PeriodicalId\":56304,\"journal\":{\"name\":\"IET Computer Vision\",\"volume\":\"17 8\",\"pages\":\"1005-1016\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2023-06-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12212\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Computer Vision\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12212\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12212","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A monocular image depth estimation method based on weighted fusion and point-wise convolution
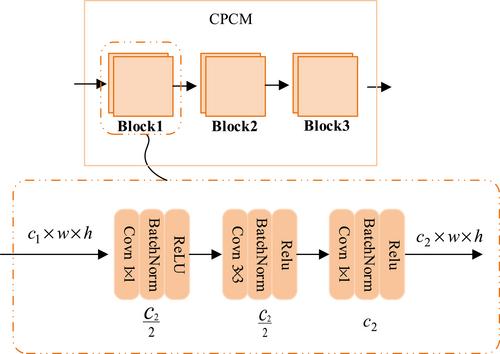
The existing monocular depth estimation methods based on deep learning have difficulty in estimating the depth near the edges of the objects in an image when the depth distance between these objects changes abruptly and decline in accuracy when an image has more noises. Furthermore, these methods consume more hardware resources because they have huge network parameters. To solve these problems, this paper proposes a depth estimation method based on weighted fusion and point-wise convolution. The authors design a maximum-average adaptive pooling weighted fusion module (MAWF) that fuses global features and local features and a continuous point-wise convolution module for processing the fused features derived from the (MAWF) module. The two modules work closely together for three times to perform weighted fusion and point-wise convolution of features of multi-scale from the encoder output, which can better decode the depth information of a scene. Experimental results show that our method achieves state-of-the-art performance on the KITTI dataset with δ1 up to 0.996 and the root mean square error metric down to 8% and has demonstrated the strong generalisation and robustness.
期刊介绍:
IET Computer Vision seeks original research papers in a wide range of areas of computer vision. The vision of the journal is to publish the highest quality research work that is relevant and topical to the field, but not forgetting those works that aim to introduce new horizons and set the agenda for future avenues of research in computer vision.
IET Computer Vision welcomes submissions on the following topics:
Biologically and perceptually motivated approaches to low level vision (feature detection, etc.);
Perceptual grouping and organisation
Representation, analysis and matching of 2D and 3D shape
Shape-from-X
Object recognition
Image understanding
Learning with visual inputs
Motion analysis and object tracking
Multiview scene analysis
Cognitive approaches in low, mid and high level vision
Control in visual systems
Colour, reflectance and light
Statistical and probabilistic models
Face and gesture
Surveillance
Biometrics and security
Robotics
Vehicle guidance
Automatic model aquisition
Medical image analysis and understanding
Aerial scene analysis and remote sensing
Deep learning models in computer vision
Both methodological and applications orientated papers are welcome.
Manuscripts submitted are expected to include a detailed and analytical review of the literature and state-of-the-art exposition of the original proposed research and its methodology, its thorough experimental evaluation, and last but not least, comparative evaluation against relevant and state-of-the-art methods. Submissions not abiding by these minimum requirements may be returned to authors without being sent to review.
Special Issues Current Call for Papers:
Computer Vision for Smart Cameras and Camera Networks - https://digital-library.theiet.org/files/IET_CVI_SC.pdf
Computer Vision for the Creative Industries - https://digital-library.theiet.org/files/IET_CVI_CVCI.pdf



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
