{"title":"用于开放信息提取的生成对抗性网络","authors":"Jiabao Han, Hongzhi Wang","doi":"10.1007/s43674-021-00006-8","DOIUrl":null,"url":null,"abstract":"<div><p>Open information extraction (Open IE) is a core task of natural language processing (NLP). Even many efforts have been made in this area, and there are still many problems that need to be tackled. Conventional Open IE approaches use a set of handcrafted patterns to extract relational tuples from the corpus. Secondly, many NLP tools are employed in their procedure; therefore, they face error propagation. To address these problems and inspired by the recent success of Generative Adversarial Networks (GANs), we employ an adversarial training architecture and name it Adversarial-OIE. In Adversarial-OIE, the training of the Open IE model is assisted by a discriminator, which is a (Convolutional Neural Network) CNN model. The goal of the discriminator is to differentiate the extraction result generated by the Open IE model from the training data. The goal of the Open IE model is to produce high-quality triples to cheat the discriminator. A policy gradient method is leveraged to co-train the Open IE model and the discriminator. In particular, due to insufficient training, the discriminator usually leads to the instability of GAN training. We use the distant supervision method to generate training data for the Adversarial-OIE model to solve this problem. To demonstrate our approach, an empirical study on two large benchmark dataset shows that our approach significantly outperforms many existing baselines.</p></div>","PeriodicalId":72089,"journal":{"name":"Advances in computational intelligence","volume":"1 4","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2021-08-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1007/s43674-021-00006-8","citationCount":"2","resultStr":"{\"title\":\"Generative adversarial networks for open information extraction\",\"authors\":\"Jiabao Han, Hongzhi Wang\",\"doi\":\"10.1007/s43674-021-00006-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Open information extraction (Open IE) is a core task of natural language processing (NLP). Even many efforts have been made in this area, and there are still many problems that need to be tackled. Conventional Open IE approaches use a set of handcrafted patterns to extract relational tuples from the corpus. Secondly, many NLP tools are employed in their procedure; therefore, they face error propagation. To address these problems and inspired by the recent success of Generative Adversarial Networks (GANs), we employ an adversarial training architecture and name it Adversarial-OIE. In Adversarial-OIE, the training of the Open IE model is assisted by a discriminator, which is a (Convolutional Neural Network) CNN model. The goal of the discriminator is to differentiate the extraction result generated by the Open IE model from the training data. The goal of the Open IE model is to produce high-quality triples to cheat the discriminator. A policy gradient method is leveraged to co-train the Open IE model and the discriminator. In particular, due to insufficient training, the discriminator usually leads to the instability of GAN training. We use the distant supervision method to generate training data for the Adversarial-OIE model to solve this problem. To demonstrate our approach, an empirical study on two large benchmark dataset shows that our approach significantly outperforms many existing baselines.</p></div>\",\"PeriodicalId\":72089,\"journal\":{\"name\":\"Advances in computational intelligence\",\"volume\":\"1 4\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2021-08-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1007/s43674-021-00006-8\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in computational intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s43674-021-00006-8\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in computational intelligence","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.1007/s43674-021-00006-8","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Generative adversarial networks for open information extraction
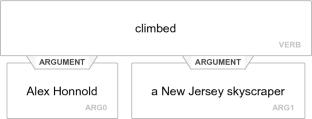
Open information extraction (Open IE) is a core task of natural language processing (NLP). Even many efforts have been made in this area, and there are still many problems that need to be tackled. Conventional Open IE approaches use a set of handcrafted patterns to extract relational tuples from the corpus. Secondly, many NLP tools are employed in their procedure; therefore, they face error propagation. To address these problems and inspired by the recent success of Generative Adversarial Networks (GANs), we employ an adversarial training architecture and name it Adversarial-OIE. In Adversarial-OIE, the training of the Open IE model is assisted by a discriminator, which is a (Convolutional Neural Network) CNN model. The goal of the discriminator is to differentiate the extraction result generated by the Open IE model from the training data. The goal of the Open IE model is to produce high-quality triples to cheat the discriminator. A policy gradient method is leveraged to co-train the Open IE model and the discriminator. In particular, due to insufficient training, the discriminator usually leads to the instability of GAN training. We use the distant supervision method to generate training data for the Adversarial-OIE model to solve this problem. To demonstrate our approach, an empirical study on two large benchmark dataset shows that our approach significantly outperforms many existing baselines.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
