Manan Goel, Rishal Aggarwal, Bhuvanesh Sridharan, Pradeep Kumar Pal, U. Deva Priyakumar
{"title":"使用现代机器学习方法进行虚拟筛选和分子设计的药物样化学空间的高效和增强采样","authors":"Manan Goel, Rishal Aggarwal, Bhuvanesh Sridharan, Pradeep Kumar Pal, U. Deva Priyakumar","doi":"10.1002/wcms.1637","DOIUrl":null,"url":null,"abstract":"<p>Drug design involves the process of identifying and designing novel molecules that have desirable properties and bind well to a given target receptor. Typically, such molecules are identified by screening large chemical libraries for desirable physicochemical properties and binding strength with the target protein. This traditional approach, however, has severe limitations as exhaustively screening every molecule in known chemical libraries is computationally infeasible. Furthermore, currently available molecular libraries are only a minuscule part of the entire set of possible drug-like molecular structures (drug-like chemical space). In this review, we discuss how the former limitation is addressed by modeling virtual screening as a search space problem and how these endeavors utilize machine learning to reduce the number of required computational experiments to identify top candidates. We follow that up by discussing generative methods that attempt to approximate the entire drug-like chemical space providing us a path to explore beyond the known drug-like chemical space. We place special emphasis on generative models that learn the marginal distributions conditioned on specific properties or receptor structures for efficient sampling of molecules. Through this review, we aim to highlight modern machine learning based methods that try to efficiently enhance our sampling capability beyond conventional screening methods which, in turn, would benefit drug design significantly. Therefore, we also encourage further methods of development that work on such important aspects of drug design.</p><p>This article is categorized under:\n </p>","PeriodicalId":236,"journal":{"name":"Wiley Interdisciplinary Reviews: Computational Molecular Science","volume":"13 2","pages":""},"PeriodicalIF":27.0000,"publicationDate":"2022-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"7","resultStr":"{\"title\":\"Efficient and enhanced sampling of drug-like chemical space for virtual screening and molecular design using modern machine learning methods\",\"authors\":\"Manan Goel, Rishal Aggarwal, Bhuvanesh Sridharan, Pradeep Kumar Pal, U. Deva Priyakumar\",\"doi\":\"10.1002/wcms.1637\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Drug design involves the process of identifying and designing novel molecules that have desirable properties and bind well to a given target receptor. Typically, such molecules are identified by screening large chemical libraries for desirable physicochemical properties and binding strength with the target protein. This traditional approach, however, has severe limitations as exhaustively screening every molecule in known chemical libraries is computationally infeasible. Furthermore, currently available molecular libraries are only a minuscule part of the entire set of possible drug-like molecular structures (drug-like chemical space). In this review, we discuss how the former limitation is addressed by modeling virtual screening as a search space problem and how these endeavors utilize machine learning to reduce the number of required computational experiments to identify top candidates. We follow that up by discussing generative methods that attempt to approximate the entire drug-like chemical space providing us a path to explore beyond the known drug-like chemical space. We place special emphasis on generative models that learn the marginal distributions conditioned on specific properties or receptor structures for efficient sampling of molecules. Through this review, we aim to highlight modern machine learning based methods that try to efficiently enhance our sampling capability beyond conventional screening methods which, in turn, would benefit drug design significantly. Therefore, we also encourage further methods of development that work on such important aspects of drug design.</p><p>This article is categorized under:\\n </p>\",\"PeriodicalId\":236,\"journal\":{\"name\":\"Wiley Interdisciplinary Reviews: Computational Molecular Science\",\"volume\":\"13 2\",\"pages\":\"\"},\"PeriodicalIF\":27.0000,\"publicationDate\":\"2022-09-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"7\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Wiley Interdisciplinary Reviews: Computational Molecular Science\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/wcms.1637\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Wiley Interdisciplinary Reviews: Computational Molecular Science","FirstCategoryId":"92","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/wcms.1637","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
Efficient and enhanced sampling of drug-like chemical space for virtual screening and molecular design using modern machine learning methods
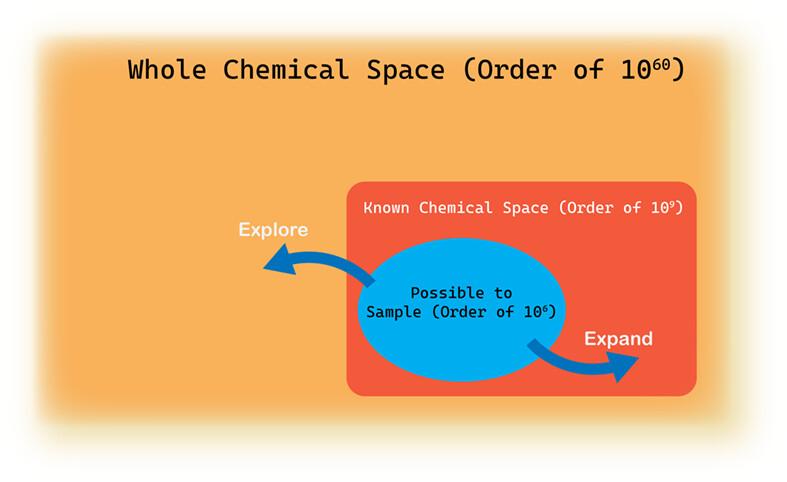
Drug design involves the process of identifying and designing novel molecules that have desirable properties and bind well to a given target receptor. Typically, such molecules are identified by screening large chemical libraries for desirable physicochemical properties and binding strength with the target protein. This traditional approach, however, has severe limitations as exhaustively screening every molecule in known chemical libraries is computationally infeasible. Furthermore, currently available molecular libraries are only a minuscule part of the entire set of possible drug-like molecular structures (drug-like chemical space). In this review, we discuss how the former limitation is addressed by modeling virtual screening as a search space problem and how these endeavors utilize machine learning to reduce the number of required computational experiments to identify top candidates. We follow that up by discussing generative methods that attempt to approximate the entire drug-like chemical space providing us a path to explore beyond the known drug-like chemical space. We place special emphasis on generative models that learn the marginal distributions conditioned on specific properties or receptor structures for efficient sampling of molecules. Through this review, we aim to highlight modern machine learning based methods that try to efficiently enhance our sampling capability beyond conventional screening methods which, in turn, would benefit drug design significantly. Therefore, we also encourage further methods of development that work on such important aspects of drug design.
期刊介绍:
Computational molecular sciences harness the power of rigorous chemical and physical theories, employing computer-based modeling, specialized hardware, software development, algorithm design, and database management to explore and illuminate every facet of molecular sciences. These interdisciplinary approaches form a bridge between chemistry, biology, and materials sciences, establishing connections with adjacent application-driven fields in both chemistry and biology. WIREs Computational Molecular Science stands as a platform to comprehensively review and spotlight research from these dynamic and interconnected fields.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
