Nikolay Babakov, Varvara Logacheva, Alexander Panchenko
{"title":"Beyond plain toxic: building datasets for detection of flammable topics and inappropriate statements","authors":"Nikolay Babakov, Varvara Logacheva, Alexander Panchenko","doi":"10.1007/s10579-023-09682-z","DOIUrl":null,"url":null,"abstract":"Toxicity on the Internet is an acknowledged problem. It includes a wide range of actions from the use of obscene words to offenses and hate speech toward particular users or groups of people. However, there also exist other types of inappropriate messages which are usually not viewed as toxic as they do not contain swear words or explicit offenses. Such messages can contain covert toxicity or generalizations, incite harmful actions (crime, suicide, drug use), and provoke “heated” discussions. These messages are often related to particular sensitive topics, e.g. politics, sexual minorities, or social injustice. Such topics tend to yield toxic emotional reactions more often than other topics, e.g. cars or computing. At the same time, not all messages within “flammable” topics are inappropriate. This work focuses on automatically detecting inappropriate language in natural texts. This is crucial for monitoring user-generated content and developing dialogue systems and AI assistants. While many works focus on toxicity detection, we highlight the fact that texts can be harmful without being toxic or containing obscene language. Blind censorship based on keywords is a common approach to address these issues, but it limits a system’s functionality. This work proposes a safe and effective solution to serve broad user needs and develop necessary resources and tools. Thus, machinery for inappropriateness detection could be useful (i) for making communication on the Internet safer, more productive, and inclusive by flagging truly inappropriate content while not banning messages blindly by topic; (ii) for detection of inappropriate messages generated by automatic systems, e.g. neural chatbots, due to biases in training data; (iii) for debiasing training data for language models (e.g. BERT and GPT-2). Towards this end, in this work, we present two text collections labeled according to a binary notion of inappropriateness (124,597 samples) and a multinomial notion of sensitive topic (33,904 samples). Assuming that the notion of inappropriateness is common among people of the same culture, we base our approach on a human intuitive understanding of what is not acceptable and harmful. To devise an objective view of inappropriateness, we define it in a data-driven way through crowdsourcing. Namely, we run a large-scale annotation study asking workers if a given chatbot-generated utterance could harm the reputation of the company that created this chatbot. High values of inter-annotator agreement suggest that the notion of inappropriateness exists and can be uniformly understood by different people. To define the notion of a sensitive topic in an objective way we use guidelines suggested by specialists in the Legal and PR departments of a large company. We use the collected datasets to train inappropriateness and sensitive topic classifiers employing both classic and Transformer-based models.","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"14 3","pages":"0"},"PeriodicalIF":1.8000,"publicationDate":"2023-10-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10579-023-09682-z","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
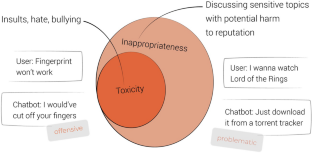
Toxicity on the Internet is an acknowledged problem. It includes a wide range of actions from the use of obscene words to offenses and hate speech toward particular users or groups of people. However, there also exist other types of inappropriate messages which are usually not viewed as toxic as they do not contain swear words or explicit offenses. Such messages can contain covert toxicity or generalizations, incite harmful actions (crime, suicide, drug use), and provoke “heated” discussions. These messages are often related to particular sensitive topics, e.g. politics, sexual minorities, or social injustice. Such topics tend to yield toxic emotional reactions more often than other topics, e.g. cars or computing. At the same time, not all messages within “flammable” topics are inappropriate. This work focuses on automatically detecting inappropriate language in natural texts. This is crucial for monitoring user-generated content and developing dialogue systems and AI assistants. While many works focus on toxicity detection, we highlight the fact that texts can be harmful without being toxic or containing obscene language. Blind censorship based on keywords is a common approach to address these issues, but it limits a system’s functionality. This work proposes a safe and effective solution to serve broad user needs and develop necessary resources and tools. Thus, machinery for inappropriateness detection could be useful (i) for making communication on the Internet safer, more productive, and inclusive by flagging truly inappropriate content while not banning messages blindly by topic; (ii) for detection of inappropriate messages generated by automatic systems, e.g. neural chatbots, due to biases in training data; (iii) for debiasing training data for language models (e.g. BERT and GPT-2). Towards this end, in this work, we present two text collections labeled according to a binary notion of inappropriateness (124,597 samples) and a multinomial notion of sensitive topic (33,904 samples). Assuming that the notion of inappropriateness is common among people of the same culture, we base our approach on a human intuitive understanding of what is not acceptable and harmful. To devise an objective view of inappropriateness, we define it in a data-driven way through crowdsourcing. Namely, we run a large-scale annotation study asking workers if a given chatbot-generated utterance could harm the reputation of the company that created this chatbot. High values of inter-annotator agreement suggest that the notion of inappropriateness exists and can be uniformly understood by different people. To define the notion of a sensitive topic in an objective way we use guidelines suggested by specialists in the Legal and PR departments of a large company. We use the collected datasets to train inappropriateness and sensitive topic classifiers employing both classic and Transformer-based models.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
